Bacalaureat - de la forma microsoftizată, la R
[1] data.gov.ro "date accesibile, reutilizabile si redistribuibile" de la instituţii publice
[2] Statistici pe judeţ, mediu şi grupe de medii, folosind R (partea a III-a)
În ultimii ani, datele constituite în urma desfăşurării examenelor naţionale ajung să fie publicate pe [1]. Zicând "publicate", avem de înţeles "publicate în format utilizabil" - adică (subliniem), nu ca "document Microsoft Word" (şi nici ca "document PDF" (sau "imagine JPG", sau secvenţă de cadre video) - a vedea de exemplu, edu.ro care este în fond un depozit de fişiere ".DOC" şi ".PDF" oferite spre "download"): se colectează date asupra unui anumit subiect de interes nu pentru a le tipări şi a ne uita la ele - ci în vederea explorării, prelucrării şi analizei ulterioare; datele respective au sens şi devin valoroase în măsura în care ele fac posibilă deducerea unor anumite caracteristici şi eventual, tendinţe ale subiectului sau domeniului pe care - în mod punctual - îl reprezintă.
După ce specialiştii le-au disecat, sintetizând concluziile corespunzătoare - datele respective îşi pierd importanţa practică (punctuală), devenind o simplă notiţă pentru istorie; eventual, dacă sunt păstrate ca atare - ele pot servi oricând drept material didactic. Astfel, datele preluate de la [1] pentru "examenele naţionale" constituie un material didactic de bună calitate: avem de-a face cu seturi voluminoase, de date reale şi în plus, avem de sesizat şi de îndreptat carenţe (obişnuite din păcate, pentru instituţiile noastre) ale reprezentării şi înregistrării acestor date.
Într-o serie de articole anterioare (încheind cu [2]) am prezentat elemente de limbaj R şi de grafică statistică, angajând datele examenului de evaluare naţională; de fapt, aveam de ales între două seturi de date de examen şi am preferat pe cel pentru care fişierul CSV de la [1] are dimensiunea mai mică (de aproape opt ori: 14.4 MB faţă de 105.8 MB). Cu această experienţă în spate, vom angaja acum şi datele examenului de bacalaureat, din fişierul de 105.8 MB bacinscriere2015sesiuneai00.csv.
1. text CSV versus document ODS
De fapt aveam de ales şi acum, între două fişiere (şi am ales CSV):

"ODS" indică un fişier în format Open Document Format for Office Applications; toate suitele "office" - inclusiv Microsoft Office - suportă formatul ODF (.odt pentru Text sau "document Microsoft Word", .odp pentru "Presentation", .ods pentru "Spreadsheet", .odg pentru "Graphics", etc.).
Am descărcat ambele fişiere indicate şi mai întâi le-am comparat ca dimensiune (folosind ls cu -s pentru "size" şi -h pentru "human readable format"; -1 listează câte un fişier pe linie):
vb@Home:~/15_bac$ ls -hs1 bacins* # fişierele numite începând cu "bacins" 38M bacinscriere2015sesiuneai000.ods OpenDocument Spreadsheet 106M bacinscriere2015sesiuneai00.csv Comma Separated Values
Dar să nu ne păcălim comparând mot à mot 38 MB şi 106 MB; un fişier ODF (dar nu-i de loc necesar să ştii asta, ca să foloseşti ODF) constă dintr-o arhivă ZIP conţinând fişiere XML asociate conţinutului şi specificaţiilor de formatare ale documentului:
vb@Home:~/15_bac$ unzip bacinscriere2015sesiuneai000.ods Archive: bacinscriere2015sesiuneai000.ods extracting: mimetype inflating: styles.xml inflating: content.xml inflating: META-INF/manifest.xml inflating: meta.xml vb@Home:~/15_bac$ ls -hs1 *.xml 902M content.xml 4.0K meta.xml 4.0K styles.xml
Ultima secvenţă redată mai sus arată că prin dezarhivarea fişierului ODS (de 38 MB) avem un fişier XML care are peste 900 MB; este clar preferabil, fişierul CSV de 106 MB (care arhivat, ar avea 7 MB).
Din "meta.xml" deducem imediat că fişierul ODT oferit la [1] a fost generat din Microsoft Excel:
<meta:generator> MicrosoftOffice/12.0 MicrosoftExcel/CalculationVersion-4518 </meta:generator>
"styles.xml" defineşte formatări pentru afişare sau scriere: numele (şi aspecte ca mărimea) fontului folosit, margini de pagină, caracteristici ale antetului şi subsolului paginii, etc.; iar "content.xml" conţine şi el - pe lângă datele propriu-zise, aflate fiecare sub câte un tag XML <text:p> - numeroase specificaţii de formatare a rândurilor şi celulelor. Cam aşa arată în final, tabelul rezultat încărcând fişierul ODS în Gnumeric (coloanele se întind până la AZ - 52 de coloane):
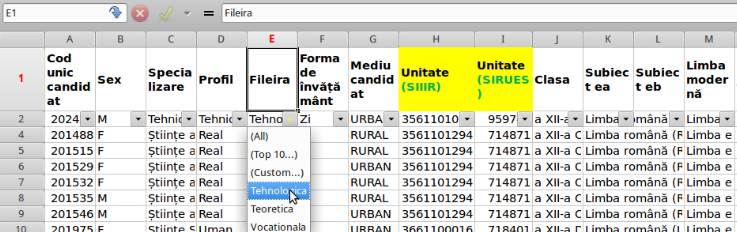
Foaia de calcul sugerată în imaginea de mai sus (în care era aplicată culoarea galben pe antetul coloanelor obligatoriu de completat) a permis desigur - şi aceasta, fără a şti ceva despre formatul ODF! - introducerea şi modificarea interactivă a datelor, precum şi tipărirea "frumoasă" a tabelului. Dar aici nu ne facem un scop din a afişa sau a tipări tabelul respectiv (sau porţiuni ale sale) şi nici nu avem de introdus ori de modificat date - încât am ales fără nicio ezitare fişierul în format CSV (de 9 ori mai scurt decât celălalt, conţinând numele coloanelor şi doar datele propriu-zise - nu şi formatări de scriere - din fiecare coloană).
1.1 (notă): document ODS versus LAMP (aplicaţii Web cu baze de date)
Ar fi fost cum nu se poate mai firesc ca la originea datelor respective să fie o bază de date (cu tabele relaţionate între ele, pentru candidaţii seriei curente, pentru candidaţii din promoţii anterioare, pentru profile, probe, etc.), întreţinută eventual prin intermediul unor formulare adecvate fiecărei etape a desfăşurării examenului, începând de la înscrierea candidaţilor. Ar fi vorba în fond de o aplicaţie Web tipică, angajând de exemplu MySQL (măcar pentru crearea bazei de date) şi - de exemplu - Python (prevăzând funcţii pentru conectare autorizată la baza de date, pentru crearea formularelor de transfer a datelor spre şi dinspre utilizatori, etc.), folosind eventual şi javaScript şi bineînţeles, HTML şi CSS.
Dar tehnologia vizată astfel - numită generic LAMP, cu variante moderne bazate pe Node.js - este cu siguranţă mai greu de înţeles şi de însuşit decât mecanica point-and-click specifică gamei Microsoft Office şi educaţiei facile şi în plus este mai nouă: produsele web framework de exemplu, au început să apară şi să "prindă" după anul 2006, în timp ce ODF s-a definitivat şi s-a impus în 2002-2005.
Faptul că ODF a fost împins în diverse ţări şi organizaţii drept formatul standard pentru documentele oficiale publice ne este explicat ca fiind un mare câştig: nu mai depinzi de un software anume, fiindcă toate suitele "office" (nu numai Microsoft Office) recunosc acest format şi totodată, acest format este valabil şi pentru documente produse cu "procesoare de text" precum Microsoft Word şi pentru documente tabelare produse cu aplicaţii precum Microsoft Excel, etc.
Însă această justificare… şchioapătă. De exemplu, ca individ eşti scutit să cumperi licenţe Microsoft - poţi deschide documentele respective folosind free software; dar instituţiile care produc documentele respective folosesc Microsoft Windows şi Microsoft Office (nicidecum "free software"), angajând mereu bugetul public pentru a achiziţiona licenţele aferente, pentru fiecare calculator în parte. Şi chiar este departe de adevăr, că "nu mai depinzi de un software anume" - depinzi de "office", adică de limitările specifice "point-and-click" (urmând cu asemenea educaţie, să devii treptat un funcţionăraş standard).
ODF este în fond un format şi rigid şi greoi, oferind mult mai puţin decât oferă o aplicaţie Web chiar şi modestă; dar lucrurile nu pot evolua în altă direcţie decât cea vizată de ODF, dat fiind că pentru guvern(e) şi parlamente şi instituţii informatizare este nimic altceva decât microsoftizare.
2. Windows "widechar" (UTF-16) versus UTF-8
Windows foloseşte UTF-16 pentru codificarea caracterelor, în vederea reprezentării şi manipulării textelor scrise în diverse limbi; deci pentru fiecare caracter se utilizează 16 biţi (pentru caractere mai rar întâlnite se îmbină după o anumită regulă, două coduri de câte 16 biţi). În imaginea redată mai sus a tabelului rezultat încărcând fişierul ODS în Gnumeric - vedem şi caractere specifice limbii române (în cuvântul "Ştiinţe" din coloana C, în cuvântul "învăţământ" din antetul coloanei F, etc.); în Excel putem verifica reprezentarea acestor caractere folosind funcţiile unicode() şi unichar():

Micul experiment sugerat de această imagine arată că "ă" este reprezentat prin codul de 16 biţi cu valoarea zecimală 259, iar codului 0xC483 (redat în notaţie hexazecimală) îi corespunde nu caracterul "ă", ci un anumit caracter japonez (redat în coloana E din imagine). Însă în UTF-8, codul de doi octeţi (tot 16 biţi, dar văzuţi nu împreună ca valoare de tip "wchar-t", ci ca un grup de câte 8 biţi) 0xC483 reprezintă chiar caracterul "ă" (şi nu caracterul japonez din coloana E).
Prin urmare, fişierul CSV a ajuns aşa de mare (la aproape 106 MB) mai ales din cauza reprezentării fiecărui caracter pe câte doi octeţi; de fapt, în fişierul respectiv numărul de caractere nestandard (ca "ă", "ş", "ţ", etc.) este foarte mic - dat fiind că numele candidaţilor au fost înlocuite prin coduri numerice; iar pentru caracterele din setul standard (a-z, A-Z, 0-9, ',', '.', etc.), octetul superior din reprezentarea UTF-16 este totdeauna 0 (încât l-am putea omite, păstrând numai octetul inferior care este chiar codul ASCII obişnuit al caracterului respectiv).
Putem folosi programul utilitar iconv, pentru a transforma fişierul CSV descărcat de la [1] - codificat prin UTF-16 - într-un fişier codificat prin UTF-8:
vb@Home:~/15_bac$ iconv --from-code=UTF-16 --to-code=UTF-8 --output=bac15.csv \ bacinscriere2015sesiuneai00.csv vb@Home:~/15_bac$ ls -hs bac15.csv 55M bac15.csv
Fişierul CSV iniţial s-a redus aproape la jumătate (55 MB faţă de 106 MB) şi în continuare vom lucra numai cu fişierul "bac15.csv" rezultat astfel. În plus, această transformare ne asigură şi o anumită simplificare: unele comenzi ar necesita precizarea codificării, printr-un parametru "fileEncoding" (de exemplu read.csv( "bacinscriere2015sesiuneai00.csv", fileEncoding="UTF-16" )) - dar parametrul respectiv are valoarea implicită "UTF-8" - încât eşti scutit de grija lui, pentru textele UTF-8.
Fiindcă fişierul a provenit din Windows, caracterul '\n' ("sfârşit de linie") este reprezentat prin 2 octeţi: 0x0D şi 0x0A (ne referim la "bac15.csv"; în fişierul CSV iniţial, în UTF-16 - '\n' era reprezentat prin 4 octeţi: 0x000D şi 0x000A); pe Linux, caracterul '\n' este reprezentat pe un singur octet, 0x0A=LF şi putem folosi un program utilitar ca fromdos pentru a înlocui 0x0D0A prin 0x0A (vezi Newline).
3. Separatori: virgula separă, punctul împarte, TAB deplasează
Cu programul utilitar xxd putem lista o zonă de octeţi consecutivi din fişierul "bac15.csv":
vb@Home:~/15_bac$ xxd -g 1 -s +50 -l 48 bac15.csv 0000032: 09 46 6f 72 6d 61 20 64 65 20 c3 ae 6e 76 c4 83 .Forma de ..nv.. (0xC483 -> ă) 0000042: c8 9b c4 83 6d c3 a2 6e 74 09 4d 65 64 69 75 20 ....m..nt.Mediu 0000052: 63 61 6e 64 69 64 61 74 09 55 6e 69 74 61 74 65 candidat.Unitate
Cei doi octeţi subliniaţi compun valoarea 0xC483 care este codul UTF-8 pentru "ă" - cum am precizat deja la §2. Câmpurile "Forma de învăţământ" şi "Mediu candidat" sunt separate prin octetul 09 - care este codul caracterului de control '\t' (numit "TAB", asociat tastei de tabulare); să mai observăm că denumirile respective nu sunt încadrate de câte un caracter '"' (ghilimele).
Nu există un format CSV standard - putem separa câmpurile prin '\t' ca în cazul de faţă, sau prin ';', sau printr-un caracter convenit (care să nu fie folosit ca atare, în text). Totuşi nu degeaba numele este "Comma Separated Values", adică "valori separate prin virgulă"; experienţa comună de folosire a tastaturii pentru editarea de texte (inclusiv tabele de date) şi pentru lucrul din linia de comandă cu diverse interpretoare de comenzi induce unor taste anumite roluri: componentele (unui text) sunt separate prin virgulă (în timp ce caracterul ";" este binecunoscut în programare drept "terminator" al formulărilor de program); împărţirea în partea întreagă şi respectiv, partea fracţionară a cifrelor unui număr se face prin caracterul punct (indiferent de interpretorul matematic folosit); ne deplasăm dintr-o coloană în alta (de tabel, sau chiar şi de text) folosind tasta TAB.
Dacă vom respecta normele uzuale, ne asigurăm anumite simplificări de programare: de regulă, acele funcţii care au de-a face cu CSV parametrizează separatorii - dar le asigură ca valori implicite pe cele uzuale (şi folosindu-le pe acestea ne scutim de griji şi evităm anumite dificultăţi).
Folosim sed pentru a înlocui ',' cu '.' şi apoi, '\t' cu ',':
vb@Home:~/15_bac$ sed -i -e 's/\,/\./g' bac15.csv 3.141593, nu 3,141593 vb@Home:~/15_bac$ sed -i -e 's/\t/\,/g' bac15.csv virgula separă, TAB deplasează!
Este drept că am înlocuit cu '.' şi caracterele ',' care apar în contexte nenumerice; de exemplu "Arhitectură, arte ambientale și design" a devenit "Arhitectură. arte ambientale și design". Dar nu puteam lăsa nicăieri ',' fiindcă şirurile de caractere care apar ca valori în diverse câmpuri nu sunt încadrate între ghilimele şi ca urmare, virgula internă dacă există, ar fi intrepretată ca separator de câmpuri! Redăm imaginea înregistrării complete a datelor unuia dintre candidaţi:

Observăm că într-adevăr, nu apar ghilimele; ni se pare preferabil să greşim - înlocuind toate virgulele cu '.' - în loc de a fi încorporat de atâtea ori, ghilimelele de protecţie necesare.
Lansând R putem acum să folosim funcţia read.csv() în cea mai simplă formă (cel puţin aşa stau lucrurile în cazul R version 3.3.1 (2016-06-21)):
vb@Home:~/15_bac$ R -q # --quiet (nu mai afişează mesajul introductiv) > bac5 <- read.csv("bac15.csv") > print(object.size(bac5), units="MB") 40.2 Mb
Am obţinut obiectul de memorie numit de-acum încolo "bac5", despre care vedem deocamdată (folosind funcţia object.size()) că se întinde cam pe 40-41 MB; nu vom mai avea de-a face cu fişierul "bac15.csv", iar pentru obiectul "bac5" va fi uşor să corectăm cazurile în care am obţinut '.' în locul virgulei, în interiorul valorilor textuale.
Desigur, "nu vom mai avea de-a face" în principiu; uneori va fi mai uşor să corectăm un anumit aspect luînd-o de la capăt (operând iarăşi pe fişierul CSV, cu care ziceam că "nu mai avem de-a face").
4. Coloane de tabel versus structură de date
Prin funcţia read.csv() pe care am invocat-o mai sus, denumirile coloanelor iniţiale au devenit nişte nume de variabile: caracterul ' ' (spaţiu) şi caractere precum '(' existente în denumirea iniţială au fost înlocuite prin '.' (de exemplu, "Unitate (SIIIR)" a devenit "Unitate..SIIIR."); a rezultat în final, o structură de date care în R se numeşte "data.frame" şi pe care o putem inspecta folosind funcţia str():
> str(bac5) 'data.frame': 168939 obs. of 52 variables: $ Cod.unic.candidat : int 202458 202461 201488 201515 201529 201532 201535 201546 201975 ... $ Sex : Factor w/ 2 levels "F","M": 2 2 1 1 1 1 2 2 1 2 ... $ Specializare : Factor w/ 96 levels "Arhitectură. arte ambientale și design",..: 59 59 20 ... $ Profil : Factor w/ 10 levels "Artistic","Educație fizică și sport",..: 8 8 5 5 5 5 5 ... $ Fileira : Factor w/ 3 levels "Tehnologica",..: 1 1 2 2 2 2 2 2 2 2 ... $ Forma.de.învățământ: Factor w/ 3 levels "Frecvență redusă",..: 3 3 3 3 3 3 3 3 3 3 ... $ Mediu.candidat : Factor w/ 2 levels "RURAL","URBAN": 2 1 1 1 2 1 1 2 2 2 ... $ Unitate..SIIIR. : num 3.56e+09 3.56e+09 3.56e+09 3.56e+09 3.56e+09 ... $ Unitate..SIRUES. : int 959744 959744 714871 714871 714871 714871 714871 714871 718401 714871 ... $ Clasa : Factor w/ 3306 levels "a XII-a ","a XII-a -",..: 1952 1952 784 784 784 ... $ Subiect.ea : Factor w/ 2 levels "Limba română (REAL)",..: 1 1 1 1 1 1 1 1 2 1 ... $ Subiect.eb : Factor w/ 10 levels "","Limba croată",..: 1 1 1 1 1 1 1 1 1 1 ... $ Limba.modernă : Factor w/ 10 levels "Limba ebraică",..: 2 2 2 2 2 2 2 2 2 2 ... $ Subiect.ec : Factor w/ 5 levels "Istorie","Matematică MATE-INFO",..: 5 5 4 4 4 4 4 4 1 2 ... $ Subiect.ed : Factor w/ 18 levels "Anatomie și fiziologie umană. genetică și ecologie umană", $ Promoție : Factor w/ 16 levels "19XY","2000-2001",..: 16 16 16 16 16 16 16 16 16 16 ... $ NOTE_RECUN_A : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ... $ NOTE_RECUN_B : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ... $ NOTE_RECUN_C : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 1 ... $ NOTE_RECUN_D : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 1 2 ... $ NOTE_RECUN_EA : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ... $ NOTE_RECUN_EB : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ... $ NOTE_RECUN_EC : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ... $ NOTE_RECUN_ED : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ... $ STATUS_A : Factor w/ 6 levels "Absent","Avansat",..: 4 2 2 2 4 4 4 4 2 4 ... $ STATUS_B : Factor w/ 5 levels "-","Absent","Avansat",..: 1 1 1 1 1 1 1 1 1 1 ... $ STATUS_C : Factor w/ 4 levels "Absent","Calificativ",..: 2 2 2 2 2 2 2 2 2 3 ... $ STATUS_D : Factor w/ 8 levels "Absent","Avansat",..: 2 8 5 5 5 5 5 5 3 5 ... $ STATUS_EA : Factor w/ 4 levels "Absent","Eliminat",..: 4 4 4 4 4 4 4 4 4 4 ... $ STATUS_EB : Factor w/ 5 levels "-","Absent","Eliminat",..: 1 1 1 1 1 1 1 1 1 1 ... $ STATUS_EC : Factor w/ 4 levels "Absent","Eliminat",..: 4 4 4 4 4 3 4 4 4 4 ... $ STATUS_ED : Factor w/ 4 levels "Absent","Eliminat",..: 3 4 4 4 4 3 4 4 4 4 ... $ ITA : Factor w/ 5 levels "-","A1","A2",..: 3 4 4 3 3 3 4 4 4 1 ... $ SCRIS_ITC : Factor w/ 5 levels "-","A1","A2",..: 3 1 3 3 3 3 3 3 3 1 ... $ SCRIS_PMS : Factor w/ 5 levels "-","A1","A2",..: 4 3 2 2 2 1 2 4 3 1 ... $ ORAL_PMO : Factor w/ 5 levels "-","A1","A2",..: 4 4 3 2 3 2 3 5 4 1 ... $ ORAL_IO : Factor w/ 5 levels "-","A1","A2",..: 5 4 3 2 3 2 3 5 4 1 ... $ NOTA_EA : num 6.05 7.85 9.1 6.2 8.45 5.8 7.7 5.65 7 9.9 ... $ NOTA_EB : num NA NA NA NA NA NA NA NA NA NA ... $ NOTA_EC : num 5.1 7.6 5.5 5 5 2.85 5.05 5.8 7.95 9.3 ... $ NOTA_ED : num 4.2 6.85 6.2 6.45 6.95 3.6 7.15 7.3 9.1 8.4 ... $ CONTESTATIE_EA : Factor w/ 2 levels "Da","Nu": 2 2 2 1 2 2 2 2 2 2 ... $ NOTA_CONTESTATIE_EA: num NA NA NA 7 NA NA NA NA NA NA ... $ CONTESTATIE_EB : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 2 2 2 2 2 ... $ NOTA_CONTESTATIE_EB: num NA NA NA NA NA NA NA NA NA NA ... $ CONTESTATIE_EC : Factor w/ 2 levels "Da","Nu": 2 2 2 2 2 1 2 2 2 2 ... $ NOTA_CONTESTATIE_EC: num NA NA NA NA NA 3.2 NA NA NA NA ... $ CONTESTATIE_ED : Factor w/ 2 levels "Da","Nu": 2 2 2 1 2 1 2 2 2 2 ... $ NOTA_CONTESTATIE_ED: num NA NA NA 6.85 NA 3.05 NA NA NA NA ... $ PUNCTAJ.DIGITALE : int 56 54 78 81 75 90 83 79 NA 92 ... $ STATUS : Factor w/ 4 levels "Absent","Eliminat",..: 3 4 4 4 4 3 4 4 4 4 ... $ Medie : num NA 7.43 6.93 6.15 6.8 NA 6.63 6.25 8.01 9.2 ...
Cele 52 de variabile din "bac5" sunt fie vectori numerici, fie vectori "factor" şi fiecare dintre aceştia are câte 168939 valori (deci în total au fost înscrişi 168939 candidaţi). Pentru exemplificare - factorul bac5$Subiect.ed indică în ordine alfabetică opţiunile probei D a bacalaureatului:
> levels(bac5$Subiect.ed)
[1] "Anatomie și fiziologie umană. genetică și ecologie umană"
[2] "Biologie vegetală și animală"
[3] "Chimie anorganică TEH Nivel I/II " [11] "Geografie"
[4] "Chimie anorganică TEO Nivel I/II " [12] "Informatică MI C/C++"
[5] "Chimie organică TEH Nivel I/II" [13] "Informatică MI Pascal"
[6] "Chimie organică TEO Nivel I/II" [14] "Informatică SN C/C++"
[7] "Economie" [15] "Informatică SN Pascal"
[8] "Filosofie" [16] "Logică. argumentare și comunicare"
[9] "Fizică TEH" [17] "Psihologie"
[10] "Fizică TEO" [18] "Sociologie"
Câţi au susţinut proba D la prima dintre opţiunile redate mai sus? Cu funcţia subset() extragem din "bac5" înregistrările dorite şi apoi folosim funcţia nrow():
> subset(bac5, Subiect.ed == levels(Subiect.ed)[1]) -> D1 > nrow(D1) [1] 29627 # 29627 linii din 'bac5' au valoarea 1 în coloana 'Subiect.ed'
Putem face şi această mică verificare - afişând coloanele 1 şi 15 din primele două înregistrări:
> D1[1:2, c(1, 15)] # coloana 15 este "Proba D" Cod.unic.candidat Subiect.ed 18 206307 Anatomie și fiziologie umană. genetică și ecologie umană 19 206308 Anatomie și fiziologie umană. genetică și ecologie umană
Dar şirul de caractere care indică opţiunea respectivă a probei D se foloseşte numai pentru afişare! Intern, opţiunea respectivă este reprezentată prin numărul de ordine al ei - putem constata aceasta împărţind dimensiunea zonei de memorie ocupate de obiect la lungimea vectorului:
> object.size(D1$Subiect.ed)
120320 bytes
> 120320/29627
[1] 4.06116 # Valorile din a 15-a coloană sunt reprezentate intern pe câte 4 octeţi
Desigur că am obţinut ceva mai mult decât 4 (care este numărul de octeţi alocat pentru "integer") - fiindcă orice structură de date memorează şi diverse informaţii contextuale. În orice caz - micul experiment redat mai sus evidenţiază unul dintre avantajele mari ale structurării datelor (implicând desigur un limbaj de programare adecvat): în fişierul text "bac15.csv" şirul de caractere "Anatomie și fiziologie umană. genetică și ecologie umană" apare de 29627 ori, ocupând în total 29627*61 = 1807247 octeţi (numărul de caractere ale şirului este 56, dar am adăugat câte un octet pentru cele 5 caractere nestandard conţinute) - adică de peste 15 ori mai mult decât ocupă în memorie variabila corespunzătoare datelor respective, D1$Subiect.ed.
5. Sensul datelor
La [1] se furnizează "rezultatele anonimizate": numele şi prenumele candidaţilor au fost "şterse", punând în loc (cum vedem în prima coloană din tabelul redat la §1) un "Cod unic candidat". Şi noi aici, am şterge sau am abrevia numele dacă ar fi existat (mai ales fiindcă au fost scrise cu majuscule!) - dar nu din raţiuni de confidenţialitate, ci pentru motivul că numele persoanelor sunt irelevante din punct de vedere statistic.
Găsim şi coloane de date care sunt irelevante şi coloane de date posibil redundante (reprezentând informaţii care pot fi deduse), iar unele coloane au denumiri impracticabile ca "identificatori" de variabile în programare ("Forma de învăţământ" vizează doar scopul tipăririi tabelului). Unele denumiri sunt stâlcite ("Fileira" în loc de "Filiera") sau stângace, trădând construcţia ad-hoc a tabelului, fără prea multă gândire şi bătaie de cap (dar aceasta este specific pentru maniera de lucru "point-and-click").
Cerinţa de bază va fi fost aceea de a tipări toate informaţiile cumulate pe parcursul desfăşurării examenului, separând aşa fel una de alta încât să nu fie pusă la încercare în nici un fel, inteligenţa celui care va căuta datele în tabel; de exemplu, apar patru coloane "NOTA_CONTESTATIE_E " pentru înregistrarea notelor acordate în urma soluţionării eventualei contestaţii - dar şi patru coloane "CONTESTATIE_E " pentru a înregistra că s-a făcut sau nu contestaţie la proba respectivă.
Chiar dacă nu este neapărat necesar (pentru a începe să ne ocupăm de statistici) şi nici nu este plăcut de făcut - vom elimina acele coloane care nu au sens şi vom simplifica unele denumiri. Întâi, salvăm pentru orice eventualitate structura de date "bac5" (o vom putea eventual recupera din fişierul respectiv, prin load()) şi listăm vectorul numelor variabilelor (avem astfel şi indecşii aferenţi):
> save(bac5, file="bac5.RData")
> names(bac5)
[1] "Cod.unic.candidat" "Sex" "Specializare"
[4] "Profil" "Fileira" "Forma.de.învățământ"
[7] "Mediu.candidat" "Unitate..SIIIR." "Unitate..SIRUES."
[10] "Clasa" "Subiect.ea" "Subiect.eb"
[13] "Limba.modernă" "Subiect.ec" "Subiect.ed"
[16] "Promoție" "NOTE_RECUN_A" "NOTE_RECUN_B"
[19] "NOTE_RECUN_C" "NOTE_RECUN_D" "NOTE_RECUN_EA"
[22] "NOTE_RECUN_EB" "NOTE_RECUN_EC" "NOTE_RECUN_ED"
[25] "STATUS_A" "STATUS_B" "STATUS_C"
[28] "STATUS_D" "STATUS_EA" "STATUS_EB"
[31] "STATUS_EC" "STATUS_ED" "ITA"
[34] "SCRIS_ITC" "SCRIS_PMS" "ORAL_PMO"
[37] "ORAL_IO" "NOTA_EA" "NOTA_EB"
[40] "NOTA_EC" "NOTA_ED" "CONTESTATIE_EA"
[43] "NOTA_CONTESTATIE_EA" "CONTESTATIE_EB" "NOTA_CONTESTATIE_EB"
[46] "CONTESTATIE_EC" "NOTA_CONTESTATIE_EC" "CONTESTATIE_ED"
[49] "NOTA_CONTESTATIE_ED" "PUNCTAJ.DIGITALE" "STATUS"
[52] "Medie"
Într-o structură "data.frame", fiecare observaţie are asociat câte un nume (în mod implicit, acesta este numărul de ordine al liniei respective); totuşi, păstrăm coloana "Cod.unic.candidat" (al cărei sens este de a identifica unic o linie, la fel ca şi numărul de ordine), dar sub numele simplu "Cand" - pentru că ea permite legarea eventuală cu tabelul de la care am plecat. Înlocuim denumirile "Subiect.ea", etc. cu "proba.A", etc. şi "NOTA_EA" etc. cu "nota.A" etc.:
names(bac5)[c(1, 5, 6, 7)] <- c("Cand", "Filiera", "Forma", "Mediu") names(bac5)[c(11:15)] <- c("proba.A", "proba.B", "limba", "proba.C", "proba.D") names(bac5)[c(38:41)] <- c("nota.A", "nota.B", "nota.C", "nota.D")
Dintre toate coloanele, cea denumită "Clasa" este chiar dubioasă, având valori cu totul particulare (ca să nu zicem însemne) precum "a XII-a B Talvac Sergiu" etc., sau bălării precum "a XII-a XII C", sau "a XII-a CLASA a XII-a" etc.; vom elimina şi cele opt coloane "NOTE_RECUN_ " de tip "Da/Nu", reprezentând recunoaşterea sau nerecunoaşterea notelor din sesiunile anterioare - coloane care au sens doar pentru fracţiunea de candidaţi care n-au încheiat examenul în anii anteriori; eliminăm şi cele opt coloane "STATUS_ " de tip "Da/Nu" - acestea induc valoarea finală a câmpului "STATUS" (păstrat):
bac5[, c(17:32, 42, 44, 46, 48)] <- NULL # elimină NOTE_RECUN_*, STATUS_*, CONTESTATIE_E* bac5$Clasa <- NULL # elimină coloana bălăriilor, `Clasa`
În plus faţă de ce am precizat mai sus, am eliminat şi cele 4 coloane "CONTESTATIE_E*"; răspunsul "Da/Nu" al acestora - dacă ar interesa - se deduce imediat din existenţa notei corespunzătoare în coloanele "NOTA_CONTESTATIE_E*" (coloane pe care le redenumim - dar nu mai redăm comanda respectivă - după modelul "nota.A.co").
5.1. Constituirea factorului corespunzător judeţelor
SIRUES era folosit înainte de 1990 pentru identificarea tuturor întreprinderilor "economico-sociale" din ţară (pare să corespundă azi cu numărul de înmatriculare la registrul comerţului); câmpul respectiv (chiar dacă este marcat "orange" în tabelul iniţial) este inutil în "bac5" şi o să-l eliminăm.
Coloana "Unitate..SIIIR." conţine codul din SIIIR care pe primele două cifre dintre cele zece identifică judeţul şi apoi codifică o serie de informaţii privitoare la unitatea şcolară din care provine candidatul respectiv; ne poate interesa numai judeţul şi avem de ţinut seama de faptul că în structura de date "bac5" valorile din câmpul respectiv sunt de tip numeric - astfel că prin conversie la caracter, putem obţine doar 9 cifre în loc de 10 (pentru judeţele codificate prin '0X', zeroul iniţial "s-a pierdut" prin conversia în reprezentare numerică):
> bac5[[8]][105040:105050]
[1] 1061104147 1061104147 1061104147 961100082 961100082 961100082
[7] 661100901 661101531 661100901 461107463 961102446
Aici am avut în vedere că o structură data.frame este în fond o listă de vectori (coloane), iar operatorul "[[" asigură selectarea unei componente a listei pe baza indexului acesteia (în timp ce operatorul "$" selectează pe baza numelui variabilei respective). Am constatat (şi am redat mai sus două rânduri) că de pe la înregistrarea de rang 105000 încep să apară şi candidaţii din judeţe de cod "0X" (cu prima cifră zero) - pentru care valoarea din coloana 8 are la afişare doar 9 cifre.
Următoarea funcţie returnează prima cifră prefixată cu "0", sau primele două cifre din codul de 9, respectiv 10 cifre primit ca argument:
jud_from_siiir <- function(siiir) { return(ifelse(nchar(siiir) == 10, substr(siiir, 1, 2), paste0(c(0), substr(siiir, 1, 1))) )}
În R, de obicei, funcţiile sunt "vectorizate": odată definită pentru un obiect, funcţia respectivă se poate invoca pentru un vector cu obiecte de tipul respectiv (sau pentru care este definită o conversie la tipul respectiv). De exemplu, funcţia introdusă mai sus poate fi aplicată unui vector de coduri:
> jud_from_siiir(c("123456789", "4012345678")) # [1] "01" "40"
Folosind astfel funcţia de mai sus, adăugăm în "bac5" variabila $jud, de clasă "character", având ca valori codurile de câte două cifre ale judeţelor; în final, eliminăm codurile SIIIR şi SIRUES:
> bac5$jud <- jud_from_siiir(bac5[[8]]) > bac5[, c(8, 9)] <- NULL
Undeva în [2], creasem o structură "jud.csp" conţinând şi numele judeţelor, în ordinea codurilor acestora; o putem refolosi acum, pentru a transforma coloana de coduri bac5$jud într-un "factor" având drept valori denumirile judeţelor:
> bac5$jud <- as.factor(bac5$jud) > levels(bac5$jud) <- jud.csp$judeţ
Redăm una dintre înregistrări (transpunând-o pe coloană prin funcţia t()) pentru a avea o imagine a modificărilor întreprinse:
>t(bac5[55482, ])
Cand "308401" SCRIS_PMS "-"
Sex "M" ORAL_PMO "B2"
Specie "Științe ale Naturii" ORAL_IO "B1"
Profil "Real" nota.A "5.35"
Filiera "Teoretica" nota.B NA
Forma "Zi" nota.C "5.55"
Mediu "RURAL" nota.D "6.95"
proba.A "Limba română (REAL)" nota.A.co "6.35"
proba.B "" nota.B.co NA
limba "Limba franceză" nota.C.co NA
proba.C "Matematică ST-NAT" nota.D.co NA
proba.D "Biologie vegetală și animală" DIGITALE "31"
Promoție "2014-2015" STATUS "Promovat"
ITA "A1" Medie "6.28"
SCRIS_ITC "A2" jud "Mureş"
Se vede că am mai înlocuit "PUNCTAJ.DIGITALE" cu "DIGITALE" şi "Specializare" cu mai scurt-ul "Specie"; bineînţeles că dacă va fi de afişat, vom afişa "Specializare" (de exemplu) şi nu cum am decis mai sus să folosim intern.
Am rămas cum se vede, la 30 de coloane de date - eliminând (cu justificările cuvenite) acele 22 de coloane care chiar nu au vreo importanţă pentru analiza rezultatelor, ţinând doar de organizarea şi desfăşurarea funcţionărească a examenului şi reflectând desigur, limitările inerente ale manierei de lucru "point-and-click" cu un singur tabel.
6. Notele finale versus instituţia contestaţiei
În tabelul original, notele acordate în urma soluţionării contestaţiilor sunt înregistrate separat de notele iniţiale. Dar se cuvine să avem încredere în "instituţia contestaţiei", încât până la urmă vom unifica aici coloanele respective (presupunând că proporţia litigiilor n-a ajuns la o limită care să sugereze repetarea întregului examen); desigur, nu de "încredere" este vorba, ci de faptul că în statisticile noastre interesează notele finale, nu şi cele iniţiale şi cele acordate la contestaţii.
În structura de date "bac5", coloanele notelor de la contestaţii au rangurile 23:26 şi conţin fie notele acordate de "Comisia de contestaţii", fie valoarea 'NA' (pentru absenţa contestaţiei); aplicăm fiecărei coloane 'q' dintre acestea, o funcţie anonimă care angajează funcţia is.na() pentru a verifica dacă valoarea curentă este sau nu 'NA' ("Not Available") şi funcţia sum(), care converteşte valorile logice la 0 şi 1 şi le însumează - rezultând numărul de contestaţii la proba respectivă:
> apply(bac5[, 23:26], 2, function(q) sum(!is.na(q))) -> frecvenţă_contestaţii > round(frecvenţă_contestaţii / nrow(bac5), 3) nota.A.co nota.B.co nota.C.co nota.D.co 0.134 0.003 0.078 0.084
La proba A au fost de aproape două ori mai multe contestaţii decât la C, sau la D - validând supoziţia larg acceptată că o lucrare la "Limba română" are mult mai mari şanse să fie notată sensibil diferit de către un alt corector, decât una la "Matematică". Dar altfel, având sub 14% contestaţii la o probă sau alta - nu credem că merită să ne mai ocupăm de contestaţii; vom elimina cele patru coloane, după ce determinăm întâi notele finale.
După normele oficiale actuale, nota finală este cea acordată de către comisia de contestaţii dacă nota iniţială este între 4.5 şi 4.99 (inclusiv), sau dacă nota iniţială este cel puţin 9.5, sau dacă diferenţa dintre cele două note este cel puţin 0.5; altfel, nota finală rămâne cea acordată iniţial:
noteFinale <- function() { for(k in 19:22) { # 'proba.A' este pe coloana 19, 'proba.B' pe 20, etc. ni <- bac5[, k] # notele iniţiale (sau '-2', '-1', 'NA') la proba indicată de k nc <- bac5[, k+4] # notele din contestaţie (sau 'NA') pentru proba indicată de k sch <- !is.na(ni) & !is.na(nc) & # schimbă (TRUE) sau nu, vechea notă cu cea nouă (ni >= 4.5 & ni < 5 | ni >= 9.5 | abs(ni - nc) >= 0.5) bac5[, k] <<- ifelse(sch, nc, ni) # "<<-" modifică variabilele "globale" } }
Pentru fiecare probă, am extras din "bac5" vectorul notelor iniţiale şi vectorul notelor din contestaţie şi am constituit vectorul de valori logice 'sch', astfel încât TRUE pe un anumit rang în acest vector să însemne că sunt îndeplinite condiţiile pentru schimbarea notei iniţiale cu cea de la contestaţie (pentru proba respectivă, la candidatul de pe rangul respectiv). Funcţia ifelse() primeşte ca argumente cei trei vectori şi returnează un vector care pe fiecare rang are fie valoarea din al doilea, fie pe cea din al treilea argument, în funcţie de valoarea logică de pe rangul respectiv din primul argument.
Am ambalat comenzile tocmai descrise într-o funcţie numai pentru a le refolosi cât mai simplu posibil, într-o procedură următoare de testare. În principiu, în R funcţiile nu au efecte laterale; dacă avem de modificat o variabilă "globală" (exterioră contextului funcţiei), atunci trebuie folosit operatorul "<<-" (vezi ultima linie din corpul funcţiei de mai sus).
Salvăm datele iniţiale, invocăm funcţia de mai sus pentru finalizarea notelor şi "ştergem" coloanele notelor acordate de comisia de contestaţii:
save(bac5, file="bac5.RData") # în vederea eventualei recuperări a datelor iniţiale noteFinale() # schimbă după caz, notele iniţiale cu cele din contestaţii bac5[, c(23:26)] <- NULL # elimină coloanele notelor acordate la contestaţii
Valorile negative -1 şi -2 care apar uneori în coloanele notelor iniţiale (rămânând nemodificate după secvenţa de mai sus), corespund cu "eliminat" sau "absent" şi dacă ar fi existat consecvenţă în această asociere, atunci puteam renunţa şi la câmpul "STATUS" (dar nu este cazul - de exemplu, întâlnim "-2" şi pentru "absent", dar şi în cazuri de "eliminat").
7. Procedură de testare
Aplicând o secvenţă de comenzi pe un lot voluminos de date - cum am făcut mai sus - apare imboldul imperios de a ne încredinţa că rezultatele sunt corecte. Putem proceda analog cu maniera standard de verificare a obiectelor produse într-o fabrică: nu se testează toate cele 10000 de becuri, ci doar 100 de becuri (sau poate numai 10) alese la întâmplare.
În secvenţa următoare - înscrisă în fişierul "check.R" - recuperăm "bac5" din fişierul "bac5.RData", extragem înregistrările care conţin cel puţin o contestaţie şi selectăm aleatoriu câteva dintre acestea; apoi transformăm setul "bac5" aplicându-i secvenţa de comenzi noteFinale() şi selectăm după aceea înregistrările corespunzătoare valorilor din câmpul Cand din lotul extras anterior:
1 2 3 4 5 6 7 8 | # check.R load("bac5.RData") litigii <- bac5[Reduce("|", data.frame(!sapply(bac5[23:26], is.na))), ] lotTest <- litigii[sample(1:nrow(litigii), 5), c(1, 19:26)] print(lotTest[order(lotTest$Cand), ], row.names=FALSE) noteFinale(); bac5[, c(23:26)] <- NULL lotTestRes <- subset(bac5, Cand %in% lotTest$Cand, select=c(1, 19:22)) print(lotTestRes[order(lotTestRes$Cand), ], row.names=FALSE) |
Avem de explicat unele dintre comenzile implicate aici; dar mai întâi - iată rezultatul produs:
> source("check.R") # execută în sesiunea R curentă, comenzile din fişier Cand nota.A nota.B nota.C nota.D nota.A.co nota.B.co nota.C.co nota.D.co 46685 5.90 NA 5.80 5.80 NA NA NA 5.50 84923 5.00 NA 3.45 3.65 NA NA 3.6 3.60 224926 8.20 NA 9.90 8.30 9.1 NA NA 9.25 241672 8.60 NA 6.95 7.50 9.1 NA 7.5 7.15 351099 5.55 NA 5.50 6.55 4.5 NA 6.2 6.85 Cand nota.A nota.B nota.C nota.D 46685 5.9 NA 5.80 5.80 84923 5.0 NA 3.45 3.65 224926 9.1 NA 9.90 9.25 241672 9.1 NA 7.50 7.50 351099 4.5 NA 6.20 6.55
Primul lot de 5 linii de date prezintă notele iniţiale şi pe cele din contestaţii, iar al doilea prezintă notele finale corespunzătoare. Se poate vedea uşor că rezultatele sunt corecte; de exemplu, nota 4.5 din nota.A.co a devenit nota finală a probei A la candidatul identificat prin Cand=351099 (înlocuind nota iniţială 5.55) - în schimb, la acelaşi candidat, nota finală pentru proba D a rămas nota iniţială, fiindcă diferenţa dintre aceasta (6.55) şi nota din contestaţie (6.85) este sub 0.5.
În linia 3 avem o formulare funcţională concisă pentru ceea ce puteam exprima direct astfel:
litigii <- subset(bac5, !is.na(nota.A.co) | !is.na(nota.B.co) | !is.na(nota.C.co) | !is.na(nota.D.co))
Între cele două formulări avem cam aceeaşi diferenţă ca între scrierea termen cu termen a unei sume şi scrierea sumei respective folosind operatorul ∑. În loc de a scrie fiecare vector nota.*.co, împreună de fiecare dată cu !is.na(*) şi cu disjuncţia finală între ei - am considerat lista de vectori bac5[23:26], pe care (invocând sapply()) am aplicat funcţia is.na(); am obţinut astfel o matrice de valori logice pe care imediat le-am inversat aplicându-i operatorul '!' (negaţia logică vectorială); apoi, am transformat această matrice (invocând data.frame()) într-o listă de vectori coloană - listă pe care am transmis-o funcţiei Reduce(): aceasta va aplica operatorul primit '|' primilor doi vectori din listă, apoi vectorului rezultat şi următorului vector din listă, ş.a.m.d. până la epuizarea listei primite ca argument (a vedea eventual şi Două exemple de reducere/acumulare funcţională). Vectorul final rezultat astfel (cu atâtea valori logice câte linii are "bac5") a fost folosit apoi ca "vector-index", selectând în variabila "litigii" acele înregistrări din "bac5" cărora vectorul respectiv le asociază valoarea TRUE.
În linia 4 am invocat sample() pentru a selecta aleatoriu 5 înregistrări dintre cele existente în "litigii", păstrând numai câmpul de identificare "Cand" şi câmpurile notelor iniţiale şi ale celor de la contestaţii; în linia 5 am ordonat după câmpul "Cand" şi am afişat lotul respectiv.
Desigur, în numai 5 înregistrări s-ar putea să nu apară toate situaţiile posibile (de exemplu, în lotul redat mai sus nu apare cazul când nota iniţială este între 4.5 şi 4.99, nici cazul "≥ 9.5"); dar repetând execuţia secvenţei redate mai sus obţinem alte 5 înregistrări şi după două-trei repetări întâlnim de obicei mai toate cazurile (şi nici "5" nu-i bătut în cuie… am ales 5 fiindcă un lot de numai cinci înregistrări este uşor de analizat din ochi).
8. Învăţământul nostru difuzează mult prea multe "specializări"!
Tabelul CSV de la care am plecat avea 52 de coloane; multe serveau cerinţe de monitorizare (de exemplu, coloana "CONTESTATIE_EA" servea pentru a marca cererile de recorectare la proba A) şi deja le-am eliminat, nefiind utile pentru analiza statistică a rezultatelor.
Listăm numele şi indecşii câmpurilor (numite şi înregistrări, sau variabile, sau coloane) din "bac5" (cu menţiunea că deja am simplificat denumirile coloanelor 15:18):
> names(bac5)
[1] "Cand" "Sex" "Specie" "Profil" "Filiera" "Forma"
[7] "Mediu" "proba.A" "proba.B" "limba" "proba.C" "proba.D"
[13] "Promoție" "ITA" "ITC" "PMS" "PMO" "IO"
[19] "nota.A" "nota.B" "nota.C" "nota.D" "DIGITALE" "STATUS"
[25] "Medie" "jud"
Folosind numele sau indecşii, putem grupa variabilele cum dorim; de exemplu, bac5[ c(24, 5) ] este o structură de tip "data.frame" care conţine numai coloanele "STATUS" şi respectiv "Filiera" din "bac5" şi care putea fi exprimată mai clar - dar… mai lung - prin bac5[ c("STATUS", "Filiera") ]. Expunem o înregistrare (are numărul de ordine 78183), pentru a sugera conţinutul câmpurilor:
> t(bac5[sample(1:nrow(bac5), 1), ]) # extrage aleatoriu (şi transpune) o înregistrare 78183 Cand "256596" ITA "B2" Sex "F" ITC "B2" # în loc de SCRIS_ITC Specie "Liceu cu program sportiv" PMS "B1" # în loc de SCRIS_PMS Profil "Educație fizică și sport" PMO "B2" # în loc de ORAL_PMO Filiera "Vocationala" IO "B2" # în loc de ORAL_IO Forma "Zi" nota.A "7" Mediu "URBAN" nota.B NA proba.A "Limba română (REAL)" nota.C "5" proba.B "" nota.D "6.1" limba "Limba engleză" DIGITALE "18" proba.C "Istorie" STATUS "Promovat" proba.D "Geografie" Medie "6.03" Promoție "2014-2015" jud "Gorj"
Datele care ne-au rămas din tabelul iniţial, în structura de date "bac5", sunt suficiente (ba chiar - încă sunt prea multe!) pentru a elabora o analiză statistică de un nivel onorabil, a rezultatelor examenului. Sunt "prea multe", în sensul că unele atribute prezintă prea multe ramificaţii care mai degrabă sunt "neimportante" din punct de vedere statistic; de exemplu, "Specie" ramifică înregistrările (candidaţii) pe 96 de "specializări" - ceea ce este excesiv de amănunţit:
> table(bac5$Specie) -> spec # frecvenţa specializărilor > print(as.data.frame(sort(spec)), row.names=FALSE) Var1 Freq Bibliotecar documentarist 1 # ... urmează încă 2 "specializări" cu câte o singură înregistrare; apoi: Instructor pentru activități extrașcolare 11 # ... încă 45 "specializări" cu câte între 12 şi 314 înregistrări; apoi: Matematica-informatica 317 Tehnician instalator pentru construcții 317 # ... încă 37 "specializări" cu câte între 390 şi 3332 înregistrări; apoi: Tehnician ecolog și protecția calității mediului 3985 Liceu cu program sportiv 4493 Tehnician în turism 5226 # 3% din total Științe Sociale 11686 Tehnician în activități economice 12259 Științe ale Naturii 20376 Filologie 23768 Matematica-Informatica 32268
Statistica nu se ocupă de o singură înregistrare (cazul primelor trei "specializări" listate mai sus), ba chiar ignoră pe cât de poate, subseturile de proporţie neglijabilă; din tabelul de frecvenţe redat parţial mai sus rezultă că mai mult de 80% dintre candidaţi au "specializarea" acoperită de numai 16 dintre cele 96 de valori indicate pentru "Specie":
> subset( as.data.frame(spec), Freq > 2000 ) -> spec2000
> cat( nrow(spec2000), " specializări = ", sum(spec2000[, 2])/nrow(bac5), "%\n" )
16 specializări = 0.8053203 %
Şi de fapt trebuiau să fie nu 96, ci 95 de specializări: specializarea "Matematică Informatică" apare o dată ca "Matematica-informatica" pentru 317 candidaţi şi apoi ca "Matematica-Informatica" pentru 32268 candidaţi (greşeală de scriere specifică lucrului în Excel la nivelul de editare manuală a tabelului); cele două apariţii corespund indexului 14:15 în vectorul nivelelor factorului "Specie" şi le putem reuni astfel:
> levels(bac5$Specie)[14:15] # inspectează [1] "Matematica-informatica" "Matematica-Informatica" > levels(bac5$Specie)[14:15] <- "Matematică-Informatică" # comasează şi redenumeşte
Recalculând după această corectură frecvenţele specializărilor, vom obţine acum pe ultimul rând din listingul redat mai sus, "Matematică-Informatică 32585" (din 32268 + 317).
Până la micul experiment statistic expus mai sus, n-am conştientizat faptul că avem aşa de multe "specializări"; totuşi, 95 chiar sunt mult prea multe, măcar pentru motivul statistic evidenţiat mai sus, că marea majoritate a elevilor (80% din serie) acoperă numai 16 dintre acestea.
9. Ce spun datele?
Rezultatele examenului apar în coloanele "STATUS" şi "Medie" (de indecşi 24 şi 25 - vezi vectorul numelor variabilelor de la §8); dacă elevul a absentat la o probă, sau a fost eliminat din examen, atunci în coloana 24 avem valoarea "Absent", respectiv "Eliminat" - iar altfel, valorile acestor două variabile (numite "variabile dependente", sau "calculate") se determină pe baza valorilor înregistrate în coloanele 19-22 (numite variabile "independente").
Este drept că tot "rezultate" trebuie considerate şi coloanele 14-18 şi 23, pe care s-au înregistrat direct nivelele de competenţe lingvistice şi digitale; desigur, coloanele 14-18 (vezi înregistrarea exemplificată la §8) ar putea fi înlocuite printr-o singură coloană, având valori şiruri de caractere formate după şablonul "B2 B2 B1 B2 B2".
Coloanele 2-13 şi 26 reprezintă diverse atribute ale candidaţilor, sau ale notelor din coloanele 19-22 - permiţând diverse grupări şi clasificări ale rezultatelor. De exemplu, putem investiga repartiţia rezultatelor după Sex şi Mediu, sau după filieră, sau după judeţ - etc.
9.1. Sortimentul "Tehnologică" este păgubos ("STATUS" versus "Filiera")
Deja la §8 am văzut "ce spun" datele apropo de specializări: sunt de 5 ori mai multe decât s-ar cuveni pentru ca sistemul să rămână consistent. Cele 95 de "specializări" ţin de trei "filiere":
> levels(bac5$Filiera) # "Tehnologica" "Teoretica" "Vocationala" > levels(bac5$Filiera) <- c("Tehnologică", "Teoretică", "Vocaţională")
Bineînţeles că - fiind aşa de simplu de făcut, prin funcţia levels() - am corectat denumirile iniţiale de "filiere"; precizăm că în continuare vom omite promptul "> " când vom mai reda comenzile interactive pe care le folosim.
Funcţia table() produce un tabel de contingenţă: determină frecvenţa în cadrul setului de date, pentru fiecare combinaţie de nivele ale factorilor indicaţi; iar apoi, funcţia addmargins() adaugă tabelului totaluri marginale (însumând pe linii şi respectiv, pe coloane):
addmargins(table(bac5[c('STATUS', 'Filiera')])) -> STF Filiera STATUS Tehnologică Teoretică Vocaţională Sum Absent 6966 1922 335 9223 Eliminat 350 178 18 546 Nepromovat 31623 15470 3757 50850 Promovat 28360 70528 9432 108320 Sum 67299 88098 13542 168939
Împărţind toate valorile prin numărul de candidaţi, obţinem frecvenţele relative şi le exprimăm procentual (cu rotunjire la a doua zecimală):
nr <- STF[5, 4] # = 168939 (=nrow(bac5)) round(STF/nr*100, 2) # procente faţă de numărul total de candidaţi Filiera STATUS Tehnologică Teoretică Vocaţională Sum Absent 4.12 1.14 0.20 5.46 Eliminat 0.21 0.11 0.01 0.32 Nepromovat 18.72 9.16 2.22 30.10 Promovat 16.79 41.75 5.58 64.12 Sum 39.84 52.15 8.02 100.00
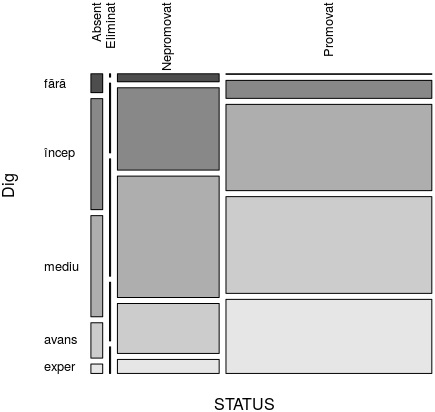
mosaicplot() transpune grafic liniile şi coloanele (excludem însă, marginile); aria fiecărui dreptunghi este proporţională cu frecvenţa categoriei reprezentate:
mosaicplot(STF[-5, -4], col=c(2:4), las=2, cex.axis=0.8, main="")
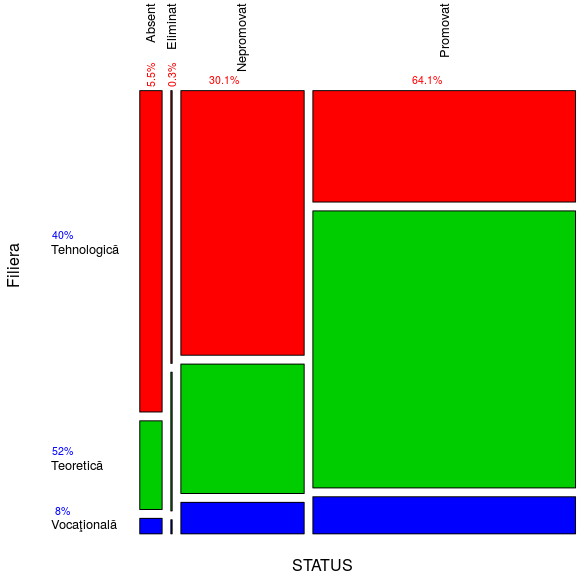
"col=c(2:4)" alege culorile de indecşi 2:4 din paleta standard, pentru zonele dreptunghiulare asociate celor trei filiere; "las=2" asigură scrierea numelor perpendicular pe axe. Am înscris pe grafic şi procentele marginale (rotunjite), folosind funcţia text() - de exemplu:
text(c(0), c(0.56, 0.13, 0.01), labels=c("40%", "52%", "8%"), cex=0.66, col="blue") text(0.17, 0.88, labels="5.5%", cex=0.66, col="red", srt=90)
srt=90 roteşte textul (indicat în parametrul "labels") cu 90°; prin "cex" se proporţionează mărimea de caracter a textului. Imaginea redată mai sus poate fi mărită: click-dreapta şi "View Image".
Între filiera "Tehnologică" şi celelalte două avem o discrepanţă care sare în ochi: culoarea roşie este covârşitoare pe dreptunghiurile stărilor "Absent" şi "Nepromovat" (la fel şi pentru "Eliminat"), cu toate că proporţia ei în cadrul întregii populaţii este doar 40%. Făcând raportul dintre liniile numite "Promovat" şi "Sum" (a 4-a şi a 5-a linie) din tabelul frecvenţelor absolute redat mai sus, obţinem proporţia de promovaţi din cadrul fiecărei filiere:
round(STF[4, ] / STF[5, ] *100, 2) # nr. promovaţi / volum Filieră (*100) Tehnologică Teoretică Vocaţională Sum 42.14 80.06 69.65 64.12
Pe filiera "Tehnologică" procentul de respinşi este cu aproape 8% mai mare decât procentul de promovaţi, în timp ce la celelalte filiere procentul de respinşi este mult sub cel de promovaţi. N-ar fi greşit să concluzionăm că filiera "Tehnologică" - aşa cum este ea organizată şi structurată până în prezent - nu-şi justifică existenţa, în cadrul sistemului de învăţământ liceal (încheiat cu "examen de bacalaureat"); avem o analogie mai mult sau mai puţin forţată (dar astfel de analogii fac parte acum din discursul oficial obişnuit): ce face un manager când vede că unul dintre produse nu se vinde? - de obicei, se gândeşte să excludă sortimentul din cauza căruia iese în pierdere.
9.2. "STATUS" versus un criteriu de clasificare oarecare
Putem generaliza analiza din §9.1 pentru oricare alt factor existent sau adăugat în structura de date "bac5", prin funcţia următoare:
status_vs <- function(field) { # numele câmpului (de clasă "factor") addmargins(table(bac5[c('STATUS', field)])) -> status mosaicplot(status[-nrow(status), -ncol(status)], # exclude totalurile marginale col=TRUE, las=2, cex.axis=0.8, main="") return(round(status/nrow(bac5)*100, 3)) }
De exemplu, reobţinem tabelul de contingenţă şi graficul de la §9.1 prin comanda:
> status_vs("Filiera")
Poate ar fi interesante repartiţiile după "Sex", respectiv după "Mediu":
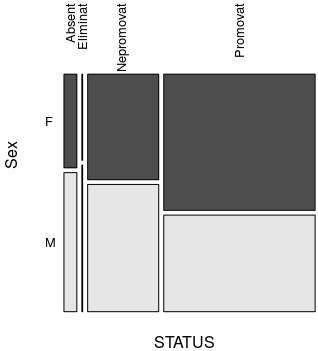
> status_vs("Sex") Sex STATUS F M Sum Absent 2.197 3.263 5.459 Eliminat 0.120 0.204 0.323 Nepromovat 13.639 16.461 30.100 Promovat 37.509 26.609 64.118 Sum 53.464 46.536 100.000
> status_vs("Mediu") Mediu STATUS RURAL URBAN Sum Absent 2.381 3.079 5.459 Eliminat 0.182 0.141 0.323 Nepromovat 12.162 17.938 30.100 Promovat 15.850 48.268 64.118 Sum 30.574 69.426 100.000
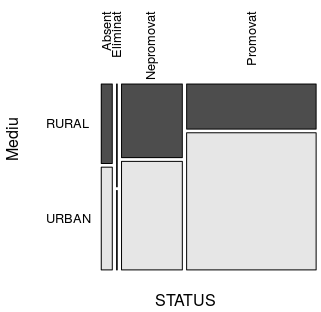
Dintre candidaţii de sex feminin au promovat 37.509 / 53.464 ≈ 70%, iar pentru sexul masculin avem doar 26.609 / 46.536 ≈ 57% promovaţi; putem semnala diferenţa (şi este mare), dar nu o putem explica. Analog, constatăm că procentul promovaţilor din rândul candidaţilor cu domiciliul în mediul rural este de 52% şi procentul promovaţilor din rândul celor domiciliaţi în mediul urban este de aproape 70% - iarăşi o diferenţă mare, care… se pretează la multe explicaţii.
Putem proceda la fel, pentru oricare alt criteriu de clasificare existent şi poate că am putea deduce nişte aspecte interesante pentru "proba.B", "proba.C", sau pentru "ITA", sau "ITC" etc.; însă de exemplu pentru "Forma" nu vom găsi nimic interesant, dat fiind că peste 97% dintre candidaţi provin de la forma de învăţământ "Zi" (şi putem ignora liniştit, "Frecvenţă redusă" şi "Seral").
Să înfiinţăm noi un criteriu de clasificare şi să folosim pentru acesta funcţia introdusă mai sus. Coloana bac5$DIGITALE înregistrează punctajele obţinute de candidaţi la proba de "competenţe digitale" - numere întregi 0..100 (dar şi valori NA); transformăm acest vector numeric într-un "factor" (folosind funcţia cut()), pe care îl adăugăm structurii de date "bac5":
bac5$Dig <- cut(bac5$DIGITALE, breaks=c(-1, 11, 31, 56, 75, 101), labels=c("fără", "încep", "mediu", "avans", "exper"), ordered_result=TRUE)
Intervalul (-1, 11) adică [0, 10] (inclusiv 0 şi 10) reprezintă nivelul numit "fără" al factorului tocmai creat, bac5$Dig (însemnând că pentru mai puţin de 11 puncte nu se va acorda nici un calificativ); intervalul de puncte [11, 30] corespunde nivelului "încep" (pentru calificativul de "începător"), ş.a.m.d. Aplicând funcţia definită mai sus obţinem:
> status_vs("Dig") Dig STATUS fără încep mediu avans exper Sum Absent 0.220 1.293 1.178 0.411 0.110 3.211 Eliminat 0.004 0.075 0.125 0.063 0.028 0.295 Nepromovat 0.803 8.272 12.187 5.019 1.409 27.689 Promovat 0.114 3.660 17.538 19.653 15.059 56.024 Sum 1.139 13.299 31.029 25.146 16.606 87.220
Faptul că suma finală este 87.22 şi nu 100 se explică prin aceea că în funcţia "status_vs()" am raportat în final prin nrow(bac5) (numărul tuturor candidaţilor), ori coloana bac5$DIGITALE conţinea şi valori NA - vedem acum că acestea sunt în procent de 100 - 87.22 = 12.18% - iar acestea sunt ignorate în funcţiile cut() şi table(). N-am vrut să înlocuiesc valorile respective cu 0 (de exemplu), fiindcă ele apar şi la unii promovaţi şi la unii nepromovaţi (putând însemna că a luat 0 puncte şi în final a promovat, dar la fel de bine - că nu s-a prezentat la proba respectivă); în plus, a înlocui 'NA' cu 0 (sau alt număr) ar afecta calculul de medii (s-ar număra şi aceste valori).
Să recuperăm tabelul de mai sus şi să raportăm linia 4 ("Promovat") la linia 5 (totalul pe fiecare nivel de competenţă digitală):
> stdg <- status_vs("Dig") > round(stdg[4, ] / stdg[5, ]*100, 3) fără încep mediu avans exper Sum 10.009 27.521 56.521 78.156 90.684 64.233
Rezultatele se citesc desigur astfel: dintre cei care au primit 0..10 puncte la "DIGITALE", au promovat 10%; printre cei cu 11..30 puncte ("începător"), 27.52% sunt promovaţi; competenţa de nivel "mediu" a atins o promovabilitate de 56.52%; ş.a.m.d. Fiindcă şi nivelele de competenţă şi procentele de promovare corespunzătoare, apar în ordinea crescătoare (a punctajelor, respectiv a procentelor), putem concluziona că şansele de promovare cresc sensibil, odată cu nivelul de competenţă digitală (probabil era de aşteptat…).
9.3 Promovabilitatea pe judeţe ("STATUS" versus "jud")
Pentru un factor care are multe nivele (cum este "jud"), va fi mai clară o reprezentare grafică prin bare asociate nivelelor, decât cea de tip "mozaic" produsă prin funcţia de mai sus status_vs(): barele - câte 4 pentru fiecare judeţ, corespuzătoare nivelelor "STATUS" - au toate o aceeaşi lăţime (distincţiile fiind date de înălţimea barelor, spre deosebire de "mozaic" unde avem de perceput arii de dreptunghiuri).
Pe de altă parte (mai ales că "jud" are 42 de nivele) este de judecat dacă toate cele 4 situaţii "STATUS", merită să fie reprezentate; dacă ponderea celor eliminaţi este foarte mică, în majoritatea judeţelor - atunci am putea renunţa să mai reprezentăm bara "Eliminat".
Folosim iarăşi funcţia table() pentru a obţine tabelul de contingenţă pentru "jud" şi "STATUS", apoi prop.table() pentru a relativiza valorile respective faţă de numărul de candidaţi din fiecare judeţ şi în final - ordonăm liniile matricei obţinute după procentul de promovabilitate:
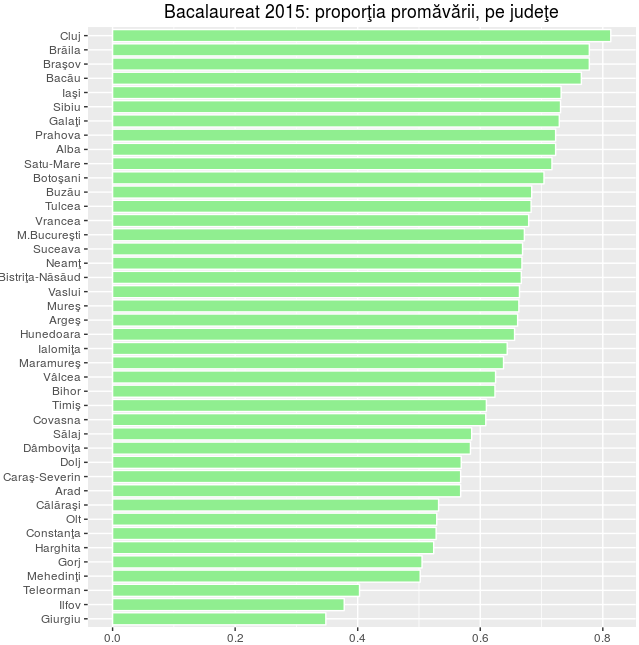
table(bac5[c('jud', 'STATUS')]) -> jud_status round(prop.table(jud_status, 1), 3) -> jud_sta ord_prom <- order(jud_sta[, 4]) jud_sta[ord_prom, ] -> jud_sta
> jud_sta # inspectăm rezultatul STATUS jud Absent Eliminat Nepromovat Promovat Giurgiu 0.066 0.002 0.583 0.348 Ilfov 0.096 0.001 0.524 0.378 Teleorman 0.091 0.003 0.504 0.403 Mehedinţi 0.087 0.000 0.411 0.502 Gorj 0.074 0.004 0.417 0.505 Harghita 0.062 0.001 0.413 0.524 Constanţa 0.066 0.004 0.402 0.528 Olt 0.088 0.001 0.382 0.529 Călăraşi 0.061 0.002 0.405 0.532 Arad 0.065 0.001 0.367 0.568 Caraş-Severin 0.087 0.003 0.343 0.568 Dolj 0.095 0.002 0.334 0.569 Dâmboviţa 0.054 0.001 0.361 0.584 Sălaj 0.072 0.001 0.341 0.586 Covasna 0.046 0.001 0.343 0.609 Timiş 0.061 0.029 0.300 0.610 Bihor 0.039 0.019 0.317 0.624 Vâlcea 0.057 0.001 0.317 0.625 Maramureş 0.068 0.002 0.293 0.638 Ialomiţa 0.063 0.002 0.291 0.644 Hunedoara 0.061 0.000 0.283 0.656 Argeş 0.034 0.001 0.304 0.661 Mureş 0.049 0.002 0.286 0.663 Vaslui 0.050 0.001 0.285 0.664 Bistriţa-Năsăud 0.069 0.000 0.264 0.667 Neamţ 0.048 0.021 0.263 0.668 Suceava 0.046 0.000 0.285 0.669 M.Bucureşti 0.043 0.001 0.283 0.672 Vrancea 0.048 0.000 0.272 0.679 Tulcea 0.068 0.000 0.249 0.683 Buzău 0.032 0.001 0.283 0.684 Botoşani 0.049 0.001 0.247 0.704 Satu-Mare 0.030 0.000 0.253 0.717 Alba 0.041 0.002 0.234 0.723 Prahova 0.043 0.001 0.234 0.723 Galaţi 0.045 0.001 0.224 0.729 Sibiu 0.059 0.001 0.210 0.731 Iaşi 0.057 0.001 0.210 0.732 Bacău 0.043 0.001 0.191 0.765 Braşov 0.034 0.001 0.187 0.778 Brăila 0.016 0.000 0.206 0.778 Cluj 0.026 0.000 0.161 0.813
În coloana "Eliminat" avem valori chiar neglijabile: aproape 3% în Timiş, 2% în Bihor şi Neamţ şi sub 0.4% în celelalte 39 de judeţe. Pentru "Absent", merită să vedem valorile statistice principale:
summary(jud_sta[, 1]) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.01600 0.04350 0.05700 0.05688 0.06750 0.09600
Jumătate dintre judeţe au procentul de absenţi între 4.35% (prima quartilă, "1st Qu.") şi 6.75% (a treia quartilă, "3st Qu."); cel mai mare procent de absenţi este 9.6% (judeţul Ilfov).
Am văzut mai sus că procentul de eliminaţi este nesemnificativ; pentru a vedea cât de semnificativ este procentul de absenţi, să-l raportăm la procentul de "Nepromovat":
jud_sta[, 1] / jud_sta[, 3] -> abs_nep # raportul între 'Absent' şi 'Nepromovat' summary(abs_nep) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.07767 0.15430 0.18020 0.18560 0.21460 0.28440
Prin urmare, absenteismul ar explica cel mult 3% din procentul celor respinşi - ceea ce înseamnă că putem simplifica fără îndoieli, lucrurile: vom viza numai statutul de "
"jud_sta" este o structură de date de clasă "table" (derivată în fond din "matrice"); o convertim la clasa "data.frame" (cum pretind de obicei funcţiile de reprezentare grafică prin bare):
class(jud_sta) [1] "table" as.data.frame(jud_sta) -> jud_sta_df str(jud_sta_df) # inspectăm structura de date 'data.frame': 168 obs. of 3 variables: $ jud : Factor w/ 42 levels "Giurgiu","Ilfov",..: 1 2 3 4 5 6 7 8 9 10 ... $ STATUS: Factor w/ 4 levels "Absent","Eliminat",..: 1 1 1 1 1 1 1 1 1 1 ... $ Freq : num 0.066 0.096 0.091 0.087 0.074 0.062 0.066 0.088 0.061 0.065 ...
Extragem numai înregistrările pentru "Promovat", excluzând desigur a doua coloană:
subset(jud_sta_df, STATUS=="Promovat", select=c(-2)) -> jud_prom
Putem sintetiza grafic datele astfel selectate, folosind funcţia ggplot() din pachetul ggplot2:
require(ggplot2) ggplot(jud_prom, aes(x=jud, y=Freq)) + geom_bar(stat='identity', col="white", fill="lightgreen", width=0.85) + labs(x="", y="", title="Bacalaureat 2015: proporţia promăvării, pe judeţe") + coord_flip()
Să vedem şi statisticile principale:
summary(jud_prom$Freq) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.3480 0.5682 0.6585 0.6294 0.6990 0.8130
Valoarea medie a procentului de promovaţi pe judeţ este de aproape 63%; pentru jumătate dintre judeţe, procentul de promovaţi este cuprins între 56.8% şi 69.9%. Pentru orice eventualitate - atenţionăm că procentul de promovaţi "pe ţară" este altceva decât media procentelor de promovaţi "pe judeţ"!
9.4 Nivelul competenţelor lingvistice într-o limbă străină
Proba de "evaluare a competenţelor lingvistice într-o limbă de circulaţie internaţională studiată pe parcursul învăţământului liceal" (sau "proba C") este reflectată în coloanele 14:18:
names(bac5)[14:18] "ITA" "ITC" # Înţelegerea Textului Audiat, respectiv Citit "PMS" "PMO" # Producerea de Mesaje Scrise, respectiv Orale "IO" # Interacţiune orală
Cele 5 coloane (de clasă factor) asociază fiecare, următoarele calificative:
levels(bac5$ITA) "-" # fără calificativ final (0..10 puncte) "A1" "A2" # Slab (11..30 puncte), respectiv Începător (31..60 puncte) "B1" "B2" # Mediu (61..80 puncte), respectiv Experimentat (81..100 puncte)
Listând câmpurile respective şi câmpul "STATUS" din diverse înregistrări, putem observa la un moment dat că apare totuşi, o dilemă:
bac5[sample(1:nrow(bac5), 5), c(14:18, 24)] ITA ITC PMS PMO IO STATUS ITA ITC PMS PMO IO STATUS 42087 A1 A1 - B1 B1 Promovat 46410 - - - - - Promovat 140263 A2 B1 - A2 A2 Nepromovat 18362 - - - - - Absent 92828 A1 A1 - B1 A1 Absent
Candidatul care are '-' (o dată sau de mai multe ori) şi apare ca "Promovat", cu siguranţă că a participat la "proba C" (neparticiparea ar fi atras "respins", în final) , iar "-" înseamnă punctaj 0..10; dar "Absent" în cazul a 5 de '-' poate însemna fie că a avut punctaje 0..10 şi a lipsit la o altă probă, fie că a lipsit chiar la "proba C".
În tabelul iniţial exista o coloană "STATUS_C" pe care se înregistra situaţia de "Absent" la "proba C" şi pe care noi am considerat anterior că o putem omite (împreună cu alte coloane de bifare a prezenţei). Dilema evidenţiată mai sus (chit că nu este una importantă) se poate rezolva numai recuperând cumva, coloana "STATUS_C":
bac5_bis <- read.csv("bac15.csv") # recuperăm datele iniţiale levels(bac5_bis$STATUS_C) [1] "Absent" "Calificativ" "Certificat" "Eliminat"
Copiem "STATUS_C" în structura de date "bac5"; inspectând datele respective, constatăm că sunt foarte puţini eliminaţi şi decidem să unificăm nivelele "Absent" şi "Eliminat" - rămânând în final la două nivele ("resp" şi "ok"):
bac5$STATUS_C <- bac5_bis$STATUS_C subset(bac5, STATUS_C=="Absent") -> abs5; nrow(abs5) # 4282 "Absent" subset(bac5, STATUS_C=="Eliminat") -> elm5; nrow(elm5) # 15 "Eliminat" levels(bac5$STATUS_C)[c(1, 4)] <- "resp" # "resp" unifică "Absent" şi "Eliminat" levels(bac5$STATUS_C)[c(2, 3)] <- "ok"
Prin investigaţia desfăşurată mai sus, am creat unele structuri de date de care nu vom mai avea nevoie; să eliberăm memoria de obiectele respective:
ls() # listăm obiectele existente în memorie [1] "abs5" "bac5" "bac5_bis" "elm5" "resp" rm(list = ls()[-2]) # afară de al doilea ("bac5"), ştergem toate obiectele
Vrând să caracterizăm cumva, competenţa lingvistică reflectată de datele din "bac5" - putem ignora cele 4282+15 înregistrări pentru care avem "resp" în coloana "STATUS_C" (toate conţinând câte 5 valori '-' în coloanele 14:18):
lingv <- subset(bac5, STATUS_C != "resp", select=c(14:18))
În principiu, avem două posibilităţi de a obţine caracteristicile statistice elementare ale datelor respective: fie constituim tabele de frecvenţă pentru fiecare coloană în parte, fie constituim tabele de contingenţă, "încrucişând" câte doi dintre cei 5 factori. Putem obţine tabelele de frecvenţă folosind funcţia table(), dar cu summary() avem o redare mai concisă:
summary(lingv) ITA ITC PMS PMO IO - :12514 - :12250 - :49016 - :14206 - :14994 A1:19146 A1:19615 A1:26549 A1:29065 A1:28459 A2:62579 A2:74721 A2:28079 A2:31913 A2:31312 B1:40935 B1:45657 B1:26724 B1:31123 B1:30315 B2:29468 B2:12399 B2:34274 B2:58335 B2:59562
Însă astfel, am obţinut o matrice cu valori de tip caracter - greu de prelucrat pentru a obţine frecvenţele relative (de acestea am avea nevoie, dacă am vrea mai târziu să confruntăm rezultatele din 2015 cu cele din 2016, de exemplu). Funcţia table() returnează direct frecvenţele respective - fără a converti la caracter şi a prelucra pentru a afişa concis şi frumos, cum face summary() - încât este uşor să relativizăm în final rezultatele.
Imbricăm lapply() pentru a aplica table() fiecărei coloane din "lingv" şi apoi pentru a transforma rezultatul prin funcţia indicată în argumentul "FUN" - funcţie care foloseşte prop.table() pentru a proporţiona valorile din tabelul respectiv faţă de totalul acestora, rotunjind apoi la a patra zecimală şi returnând procentul respectiv:
lapply(lapply(lingv,table), FUN=function(t) 100*round(prop.table(t), 4))
$ITA # Înţelegerea Textului Audiat - A1 A2 B1 B2 7.60 11.63 38.01 24.86 17.90 # predomină calitatea A2 şi B1 (31-60, 61-80 puncte) $ITC # Înţelegerea Textului Citit - A1 A2 B1 B2 7.44 11.91 45.38 27.73 7.53 # predomină calitatea A2 (31-60 puncte) $PMS # Producere de Mesaje Scrise - A1 A2 B1 B2 29.77 16.13 17.05 16.23 20.82 # predomină calitatea '-' (0-10 puncte) $PMO # Producere de Mesaje Orale - A1 A2 B1 B2 8.63 17.65 19.38 18.90 35.43 # predomină calitatea B2 (81-100 puncte) $IO # Interacţiune Orală - A1 A2 B1 B2 9.11 17.29 19.02 18.41 36.18 # predomină calitatea B2 (81-100 puncte)
Cel mai vizibil aspect (probabil, binecunoscut) este faptul că lumea se descurcă cel mai greu cu mesajele scrise: la PMS avem aproape 30% de '-' (candidaţi cu punctaj 0-10), iar acest procent este mult mai mare decât toate celelalte de pe prima coloană (corespunzătoare calităţii '-').
Ar fi interesant să vedem (de exemplu) câţi au punctaj mic în primele două şi punctaj mare în ultimele două dintre cele cinci variabile (fiind de aşteptat că, dacă înţelegi greu ce zice altul atunci nu poţi interacţiona prea bine - deci, punctaj mic la primele ar trebui să însemne punctaj mic şi la ultimele); cerinţele de acest tip sunt modelate prin tabelul de contingenţă, în care avem frecvenţa fiecărei combinaţii de valori ale variabilelor respective:
table(lingv) -> lingv_contg lingv_contg[1, 1, 1, 1, 1] [1] 10110 # 10110 candidaţi (promovaţi sau nu) au '-' la toate cele 5 criterii lingvistice lingv_contg[5, 5, 5, 5, 5] [1] 4652 # 4652 candidaţi au 'B2' pe toate cele 5 nivele lingv_contg[1, 1, 2, 3, 1] [1] 0 # nici unul nu are '- - A1 A2 -' (respectiv pe 'ITA ITC PMS PMO IO')
Variabilele sunt indexate (de la 1) în mod implicit, în ordinea în care apar coloanele respective; valorile variabilelor sunt şi ele indexate în mod implicit (în ordinea punctajelor asociate); avem 5 variabile, fiecare cu câte 5 valori - astfel că avem 55 = 3125 combinaţii de valori, iar rezultatul "lingv_contg" exemplificat mai sus asociază fiecăreia dintre acestea frecvenţa de apariţie în "lingv" a combinaţiei respective.
Putem afişa mai compact (54=625 de linii, în loc de 3125) tabelul de contingenţă obţinut, folosind funcţia ftable() - dar nu afişarea, ne interesează; cel mai convenabil este să restructurăm tabelul în modul nativ "data.frame" (facilitând accesarea, ordonarea, sumarizarea şi reprezentarea grafică):
as.data.frame(lingv_contg) -> lingv_ctg str(lingv_ctg) 'data.frame': 3125 obs. of 6 variables: $ ITA : Factor w/ 5 levels "-","A1","A2",..: 1 2 3 4 5 1 2 3 4 5 ... $ ITC : Factor w/ 5 levels "-","A1","A2",..: 1 1 1 1 1 2 2 2 2 2 ... $ PMS : Factor w/ 5 levels "-","A1","A2",..: 1 1 1 1 1 1 1 1 1 1 ... $ PMO : Factor w/ 5 levels "-","A1","A2",..: 1 1 1 1 1 1 1 1 1 1 ... $ IO : Factor w/ 5 levels "-","A1","A2",..: 1 1 1 1 1 1 1 1 1 1 ... $ Freq: int 10110 28 29 4 2 75 299 368 51 8 ...
Ordonăm descrescător după frecvenţe, transformăm în procente faţă de numărul de prezenţi şi listăm înregistrările la care avem măcar 2% candidaţi:
lingv_ctg[order(-lingv_ctg$Freq), ] -> lingv_ctg lingv_ctg$Freq <- 100*round(lingv_ctg$Freq / nrow(lingv), 4) lingv_ctg[lingv_ctg$Freq > 2, ] ITA ITC PMS PMO IO Freq 1 - - - - - 6.14 3120 B2 B1 B2 B2 B2 4.53 3119 B1 B1 B2 B2 B2 3.49 3125 B2 B2 B2 B2 B2 2.83 763 A2 A2 - A1 A1 2.75
Avem de recunoscut că rezultatele ca atare sunt oarecum dezamăgitoare pentru noi, care am făcut investigaţia redată mai sus: am muncit mult şi am obţinut ce?! - procente de ordin cel mult 6%…
Însumând valorile din ultimele patru din cele cinci rânduri de rezultate redate mai sus, putem zice doar că 13-14% dintre candidaţi au obţinut rezultate bune (majoritare fiind 'B1' şi 'B2'), la cele cinci criterii de competenţă lingvistică.
9.5 Probele scrise; "informatică" versus "biologie"
Intenţionăm să ne ocupăm din punct de vedere statistic, de notele şi de mediile candidaţilor. Dar fiecare coloană de note corespunde la 2, 4, 10 sau chiar 18 obiecte de învăţământ; ne putem ocupa (din punct de vedere statistic) de fiecare obiect în parte - dar are sens aşa ceva?
Folosim iarăşi instrumentul lapply(), aplicând funcţia levels() fiecăreia dintre variabilele (de clasă "factor") corespunzătoare în "bac5" categoriilor de obiecte (probelor):
lapply(bac5[c(8:12)], levels) $proba.A # coloana 8 [1] "Limba română (REAL)" "Limba română (UMAN)" $proba.B # limba maternă (coloana 9) [1] "" "Limba croată" "Limba germană" [4] "Limba italiană" "Limba maghiară (REAL)" "Limba maghiară (UMAN)" [7] "Limba sârbă" "Limba slovacă" "Limba turcă" [10] "Limba ucraineană" $limba # limba străină - ţine de "competenţe lingvistice" (v. §9.4) [1] "Limba ebraică" "Limba engleză" "Limba franceză" [4] "Limba germană modernă" "Limba italiană" "Limba japoneză" [7] "Limba portugheză" "Limba rusă" "Limba spaniolă" [10] "Limba turcă modernă" $proba.C # coloana 11 [1] "Istorie" "Matematică MATE-INFO" "Matematică PED" [4] "Matematică ST-NAT" "Matematică TEHN" $proba.D # coloana 12 [1] "Anatomie și fiziologie umană. genetică și ecologie umană" [2] "Biologie vegetală și animală" [3] "Chimie anorganică TEH Nivel I/II " [4] "Chimie anorganică TEO Nivel I/II " [5] "Chimie organică TEH Nivel I/II" [6] "Chimie organică TEO Nivel I/II" [7] "Economie" [8] "Filosofie" [9] "Fizică TEH" [10] "Fizică TEO" [11] "Geografie" [12] "Informatică MI C/C++" [13] "Informatică MI Pascal" [14] "Informatică SN C/C++" [15] "Informatică SN Pascal" [16] "Logică. argumentare și comunicare" [17] "Psihologie" [18] "Sociologie"
Notele din coloana 'nota.A' (a 19-a din "bac5") corespund probei numite în mod standard "Limba şi literatura română"; însă factorul 'proba.A' separă notele respective în două secţiuni; am putea investiga în parte, fiecare secţiune - dar are sens această separare? Subiectele de rezolvat or fi ţinut ele cont de faptul că se adresează secţiunii 'REAL' şi respectiv 'UMAN', dar notele măsurate în final sunt în ambele cazuri, punctaje din intervalul [1, 10]; baremul după care se măsoară nota ţine cont desigur, de subiect (deci de secţiune), dar de fapt este cel corespunzător probei de "Limba română" (nu "Matematică", sau altă probă).
Putem constata şi direct, că din punct de vedere statistic cele două secţiuni nu diferă semnificativ (având cam aceeaşi repartiţie a notelor):
bac5[bac5$proba.A == "Limba română (UMAN)", ] -> uman bac5[bac5$proba.A == "Limba română (REAL)", ] -> real summary(uman$nota.A) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.000 5.900 7.450 7.016 8.500 10.000 summary(real$nota.A) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.000 5.150 6.700 6.351 8.200 10.000
Nota minimă este "-2.000" (negativă) - am uitat de faptul că în coloanele de note avem şi valorile "-1" şi "-2" (pe lângă note obişnuite), semnificând "Absent" sau "Eliminat" (v. §.6); prin urmare, quartilele obţinute sunt ceva mai mici decât sunt în realitate (după ce vom fi exclus valorile negative). Oricum, se vede că diferenţele între cele două secţiuni (pe quartilele respective) sunt mai mici decât 1%.
Cu o secvenţă de comenzi similară celeia redate mai sus, putem obţine quartilele repartizării notelor pentru oricare dintre obiectele vizate de o probă sau alta. Ca şi în §9.4 putem obţine deasemenea, tabelul de contingenţă între probele respective (câţi candidaţi au susţinut cutare probe, alegând după caz cutare obiecte ale fiecăreia) - de exemplu:
table(bac5[c(8, 11, 12)]) -> scris.ctg # contingenţa probelor A, C şi D as.data.frame(scris.ctg) -> scris.df scris.df[scris.df$Freq != 0, ] -> scris.df # ignoră frecvenţa 0 str(scris.df) # inspectăm structura de date rezultată 'data.frame': 39 obs. of 4 variables: $ proba.A: Factor w/ 2 levels "Limba română (REAL)",..: 1 1 1 1 1 1 1 1 1 1 ... $ proba.C: Factor w/ 5 levels "Istorie","Matematică MATE-INFO",..: 2 4 5 2 ... $ proba.D: Factor w/ 18 levels "Anatomie și fiziologie umană. genetică și ecologie $ Freq : int 11742 12784 5101 6395 3808 28172 2264 885 609 711 ...
În acest exemplu, pentru cele trei probe avem 2×5×18 = 180 de combinaţii de obiecte ale acestora, dar îndepărtându-le pe cele de frecvenţă 0 (de exemplu, nu există niciun candidat cu "Limba română (REAL)" la prima probă, cu "Istorie" la a doua şi cu "Fizică TEO" la a treia probă) ne-au rămas 39 de înregistrări. Dacă vrem să afişăm rezultatele, putem folosi o funcţie precum abbreviate(), pentru a scurta denumirile obiectelor probei D:
levels(scris.df$proba.D) <- abbreviate(levels(scris.df$proba.D), minlength=20) print(scris.df[order(-scris.df$Freq), ], row.names=FALSE) proba.A proba.C proba.D Freq Limba română (REAL) Matematică TEHN Biologvegetalșanimal 28172 Limba română (REAL) Matematică TEHN Geografie 24967 Limba română (UMAN) Istorie Geografie 23139 Limba română (REAL) Matematică ST-NAT Antmșfzlgumngntcșecu 12784 Limba română (REAL) Matematică MATE-INFO Antmșfzlgumngntcșecu 11742 Limba română (REAL) Istorie Geografie 9445 Limba română (UMAN) Istorie Logicargumentrșcmncr 6496 Limba română (REAL) Matematică MATE-INFO Biologvegetalșanimal 6395 Limba română (REAL) Matematică MATE-INFO Informatică MI C/C++ 6029 Limba română (REAL) Matematică TEHN Antmșfzlgumngntcșecu 5101 Limba română (REAL) Matematică MATE-INFO Fizică TEO 4473 Limba română (REAL) Matematică ST-NAT Biologvegetalșanimal 3808 Limba română (UMAN) Istorie Sociologie 3457 Limba română (REAL) Matematică TEHN Fizică TEH 3144 Limba română (REAL) Matematică ST-NAT ChimorgancTEONvlI/II 2324 Limba română (REAL) Matematică TEHN ChimanrgncTEHNvlI/II 2264 Limba română (REAL) Matematică TEHN Logicargumentrșcmncr 1943 Limba română (REAL) Matematică MATE-INFO ChimorgancTEONvlI/II 1857 Limba română (UMAN) Matematică PED Geografie 1482 Limba română (REAL) Matematică MATE-INFO InformaticăMIPascal 1205 Limba română (REAL) Istorie Logicargumentrșcmncr 1143 Limba română (UMAN) Istorie Psihologie 1083 Limba română (REAL) Matematică MATE-INFO ChimanrgncTEONvlI/II 885 Limba română (UMAN) Istorie Economie 777 Limba română (REAL) Matematică TEHN ChimorgancTEHNvlI/II 711 Limba română (REAL) Matematică TEHN Economie 702 Limba română (REAL) Matematică ST-NAT Fizică TEO 701 Limba română (REAL) Matematică ST-NAT ChimanrgncTEONvlI/II 609 Limba română (UMAN) Istorie Filosofie 515 Limba română (UMAN) Matematică PED Logicargumentrșcmncr 444 Limba română (REAL) Matematică TEHN Psihologie 294 Limba română (REAL) Istorie Filosofie 267 Limba română (REAL) Istorie Psihologie 206 Limba română (UMAN) Matematică PED Psihologie 187 Limba română (REAL) Matematică ST-NAT Informatică SN C/C++ 135 Limba română (REAL) Istorie Economie 18 Limba română (REAL) Matematică ST-NAT InformaticăSNPascal 15 Limba română (UMAN) Matematică PED Economie 11 Limba română (UMAN) Matematică PED Filosofie 9
Iar acum putem extrage subtabele de contingenţă; de exemplu, dacă ne-ar interesa frecvenţa pe obiectele probei D între candidaţii de la "MATE-INFO":
subset(scris.df, proba.C=="Matematică MATE-INFO", select=c(3, 4)) proba.D Freq Antmșfzlgumngntcșecu 11742 # Anatomie și fiziologie umană. genetică și ecologie umană Biologvegetalșanimal 6395 Informatică MI C/C++ 6029 Fizică TEO 4473 ChimorgancTEONvlI/II 1857 InformaticăMIPascal 1205 ChimanrgncTEONvlI/II 885
Punctăm în treacăt, că proporţia celor de la "matematică-informatică" având "Anatomie" sau "Biologie" la proba D (primele două rânduri pe rezultatele redate mai sus) este de aproape trei ori mai mare decât pentru "Informatică" (linia 3 plus linia 6) - ceea ce ar trebui văzut că este cam pe dos de cum s-ar cuveni (pentru că volumul (chiar şi prestanţa) orelor de "Informatică" în ciclul liceal la "matematică-informatică" este mult mai mare decât al celor de "Biologie").
9.6 Clasificarea după nivelul notelor şi mediilor
Ne-am amintit ceva mai înainte, că în coloanele de note avem şi valori "-1" şi "-2"; înlocuim toate aceste valori prin "NA" (astfel, ele vor fi ignorate la calculul de medii):
bac5[, 19:22][bac5[, 19:22] < 0] <- NA
Acum putem obţine corect, quartilele corespunzătoare notelor pe fiecare probă în parte şi pe cele corespunzătoare mediilor finale; aplicăm summary() coloanelor respective, folosind sapply() (care simplifică rezultatele produse de lapply(), formând o matrice a acestora):
sapply(bac5[c(19:22, 25)], summary) nota.A nota.B nota.C nota.D Medie Min. 1.000 1.300 1.000 1.000 5.00 1st Qu. 5.400 6.300 5.150 5.650 6.73 Median 7.000 7.500 6.850 7.500 7.80 Mean 6.816 7.402 6.618 7.046 7.73 3rd Qu. 8.300 8.600 8.600 8.800 8.75 Max. 10.000 10.000 10.000 10.000 10.00 NA's 6100.000 160719.000 7144.000 7101.000 50638.00
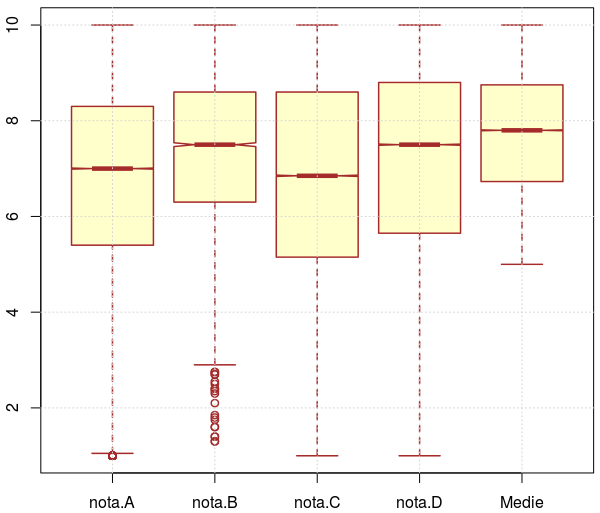
Corespunzător matricei redate, avem "boxplot"-ul alăturat mai sus (v. [2]; click-dreapta şi View Image pentru a mări imaginea), obţinut prin:
boxplot(bac5[c(19:22, 25)], notch=TRUE, col="#FFFFCC", border="brown", lwd=1.5)
În coloana 'nota.B' avem 160719 valori 'NA' (note neatribuite); aceasta înseamnă că proba de "Limba maternă" a fost susţinută de nrow(bac5) - 160719 = 8220 candidaţi şi fiindcă proporţia acestora (4.87% din numărul total de candidaţi) este aşa de mică, nu ne vom ocupa aici separat, de această categorie.
Ne interesează repartiţia notelor (şi mediilor) pe intervalele obişnuite [1, 5), [5, 6), etc., vizând toţi candidaţii, sau eventual numai o parte a acestora (satisfăcând un anumit criteriu - de exemplu să fie din acelaşi judeţ, sau să fie de acelaşi sex, din aceeaşi promoţie, etc.). Vom constitui o funcţie numită "pergaps()", care să ne obţină procentele de candidaţi pe fiecare interval de medii ("gap"), pentru un subset din "bac5" furnizat ca argument.
Apar două probleme mai deosebite: valorile NA (ignorate de majoritatea funcţiilor statistice) sunt în număr diferit pe coloanele de note, încât avem de văzut cum putem obţine - într-o formulare unitară - numărul de candidaţi faţă de care vrem să obţinem procentele corespunzătoare intervalelor de medii (am folosit aici experienţa de prin [2] - vezi funcţia classify()); a doua problemă provine din faptul că pe coloana Medie nu avem valori din intervalul [1, 5) (metodologia închipuită pentru bacalaureat prevede calculul mediei numai în cazul când la toate probele s-a obţinut cel puţin 5) - ceea ce înseamnă că la clasificarea notelor pe intervale trebuie (neavând la îndemână o soluţie unitară) să tratăm separat cazul coloanelor de note (a 19-a, a 21-a şi a 22-a coloană) şi respectiv, cazul coloanei 25 (cea de "Medie").
pergaps <- function(set_bac, materna=FALSE) { # browser() # `set_bac`: subset din "bac5"; `materna`: include sau nu, notele din "Limba maternă" # Eroare ("no rows to aggregate") dacă o coloană de note din `set_bac` conţine numai `NA` cols <- c(19:22, 25) # indecşii coloanelor de note la probele A-D şi coloanei 'Medie' if(!materna) cols <- cols[-2] # exclude eventual, coloana notelor probei B ncl <- length(cols) sdf <- subset(set_bac, select=cols) # în "sdf" coloanele de note au rangurile 1..ncl proc <- data.frame(gap = c("[1,5)","[5,6)","[6,7)","[7,8)","[8,9)","[9,10]")) # în "proc" vom adăuga coloane cu procentele pe probe şi pe intervalele din "gap" breaks = c(1, 5:9, 10.01) # limitele standard ale intervalelor de medii for(k in 2:ncl) { lim <- cut(sdf[, k-1], breaks=breaks, right=FALSE) # clasifică notele proc[k] <- aggregate(sdf[, k-1] ~ lim, sdf, length)[2] # contorizează } # pentru coloana "Medie", exclude intervalul "[1, 5)" (s-au înscris numai mediile ≥ 5) m5 <- aggregate(sdf[, ncl] ~ cut(sdf[, ncl], breaks=breaks[-1], right=FALSE), sdf, length)[2] # contorizează pe intervalele rămase proc[ncl+1] <- c(0, m5[[1]]) # anexează 0 - elevi cu "Medie" < 5 names(proc)[2:(ncl+1)] <- names(bac5)[cols] # redenumeşte coloanele din 'proc' nelevi <- lapply(proc[2:(ncl+1)], sum) # numărul total de elevi, pe fiecare coloană proc[2:(ncl+1)] <- round(proc[2:(ncl+1)]/nelevi, 4)*100 # procent elevi pe interval list(proc, nelevi) # procentul de elevi pe intervale şi probe, total elevi pe probă }
Punerea la punct a acestei funcţii a fost un bun prilej de a clarifica vreo două aspecte "simple" (de limbaj R); dar a trebuit să folosesc funcţia browser(), pentru a urmări pas cu pas execuţia - am inserat "browser()" pe prima linie din corpul funcţiei şi am lansat pergaps(bac5):
Browse[2]> n # "next" - execută următoarea linie din corpul funcţiei debug at #17: proc[ncl + 1] <- c(0, m5[[1]]) # dar iniţial, pusesem GREŞIT m5[1] Browse[2]> m5[1] # m5 este o structură "data.frame", cu o singură coloană sdf[, ncl] 1 9981 # 9981 medii în intervalul [5, 6) 2 26059 # în intervalul [6, 7) 3 28731 # în intervalul [7, 8) 4 31515 # în intervalul [8, 9) 5 22015 # în intervalul [9, 10] Browse[2]> str(m5[1]) 'data.frame': 5 obs. of 1 variable: # COLOANA DE "data.frame" ESTE TOT "data.frame"! $ sdf[, ncl]: int 9981 26059 28731 31515 22015 Browse[2]> str(m5[[1]]) # m5[[1]] este VECTORul pe care-l voiam aici int [1:5] 9981 26059 28731 31515 22015
Secvenţa redată mai sus lămureşte distincţia dintre operatorii "[" şi "[["; făcând o analogie (reţinută de pe undeva) - cu "[ ]" poţi selecta unul sau mai multe vagoane ale unei garnituri de tren, în timp ce prin "[[ ]]" poţi obţine conţinutul unui anumit vagon. Am avut nevoie de cele 5 valori din structura de date "m5" (deci de m5[[1]]), pe care le-am completat cu 0 (numărul mediilor din intervalul [1, 5)), înscriind vectorul rezultat (cu 6 valori) în structura de date "proc" (în urma execuţiei liniei 17 din corpul funcţiei).
Al doilea aspect ţine de operatorul ":". Am fost neinspirat să folosesc repetat expresia "ncl + 1" (în penultimele patru linii din blocul funcţiei) - în loc de a considera o variabilă suplimentară (ncl1 <- ncl + 1; names(proc)[2:ncl1] ..., etc.) - şi iniţial am folosit "names(proc)[2 : ncl + 1]", ceea ce este greşit: ":" are prioritatea mai mare decât "+", încât de exemplu expresia "k=3; 1:k+1" va conduce la "2,3,4" şi nu la "1,2,3,4" (pentru care trebuiau paranteze "1: (k+1)").
Exemplificăm "pergaps()", comparând rezultatele a două categorii de elevi - cei care au susţinut "proba D" la "Informatică" (setul numit mai jos "matinf1") şi cei care au susţinut-o la "Biologie" sau "Anatomie" (setul "matinf2"), din rândul celor de la profilul "matematică-informatică":
matinf.1 <- subset(bac5, proba.C=="Matematică MATE-INFO" & startsWith(as.character(proba.D), "Infor")) pergaps(matinf.1) [[1]] # procente, pe intervale de medii [[2]] # total elevi gap nota.A nota.C nota.D Medie nota.A nota.C nota.D Medie 1 [1,5) 0.93 2.14 2.38 0.00 7211 7208 7212 6873 2 [5,6) 6.57 6.09 8.50 2.28 3 [6,7) 10.94 7.45 11.12 9.69 4 [7,8) 20.21 11.08 15.06 18.07 5 [8,9) 33.01 17.65 21.59 31.50 6 [9,10] 28.35 55.59 41.35 38.45 matinf.2 <- subset(bac5, proba.C=="Matematică MATE-INFO" & (startsWith(as.character(proba.D), "Biol") | startsWith(as.character(proba.D), "Anat"))) pergaps(matinf.2) [[1]] # procente, pe intervale de medii [[2]] # total elevi gap nota.A nota.C nota.D Medie nota.A nota.C nota.D Medie 1 [1,5) 4.51 14.94 8.24 0.00 17847 17739 17730 14269 2 [5,6) 15.61 18.50 11.21 6.69 3 [6,7) 15.49 12.73 13.25 18.14 4 [7,8) 19.16 14.63 16.07 22.50 5 [8,9) 25.79 16.81 21.46 29.39 6 [9,10] 19.44 22.39 29.77 23.29
Rezultatele celor care au susţinut proba D la "informatică" sunt clar mai bune decât ale celor care au susţinut-o la "biologie" sau "anatomie" (ignorând faptul că aceştia din urmă sunt de peste două ori mai mulţi): proporţia notelor între 8 şi 10 (rândurile 5 şi 6 din matricele de mai sus) este cu 16% mai mare la proba A, cu 34% mai mare la proba C şi cu 12% mai mare la proba D.
Lucrurile devin şi mai clare prin intermediul unui grafic, asociat matricelor de mai sus:
as.matrix(mtif1[-1]) -> mtif1.m # 'mtf1' este prima matrice (mtf1 <- pergaps(matinf1)[[1]]) dimnames(mtif1.m)[1] <- mtif1[1] # coloana 'gap' va denumi liniile noii matrice as.matrix(mtif2[-1]) -> mtif2.m # (mtf2 <- pergaps(matinf2)[[1]]) dimnames(mtif2.m)[1] <- mtif2[1] op <- par(mfrow = c(1, 2), # fereastra grafică va avea o linie şi două coloane font.main = 1, # text obişnuit (nu "bold", nici "italic") pentru titluri mar = c(5, 4, 4, 0.5)) # margine-dreapta de 0.5 rânduri, pentru prima coloană barplot(mtif1.m, # bare pe probe, pentru fiecare interval "gap" beside = TRUE, col = palette()[1:6], # coloane alăturate, colorate distinct ylim = c(0, 60), # procentele fiind între 0 şi 55.59 main="proba D: informatică", ylab="procente") grid(NA, NULL) # trasează numai linii orizontale, la valorile înscrise pe axa verticală par(mar=c(5, 0, 4, 2)) # fără margine-stânga, pentru graficul din a doua coloană barplot(mtif2.m, beside=TRUE, col=palette()[1:6], ylim=c(0, 60), axes = FALSE, # elimină axa verticală legend.text = TRUE, # adaugă o legendă, în dreapta sus args.legend = list(x="topright", cex=0.75), main = "proba D: biologie sau anatomie") # titlul graficului din a II-a coloană grid(NA, NULL) mtext("profilul 'Informatică-Matematică'", side=3, line=-1.1, outer=TRUE, cex=1.2) par(op) # reconstituie valorile implicite pentru parametrii grafici
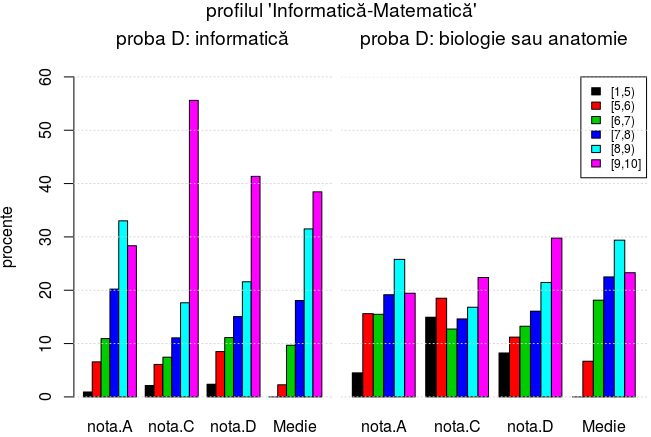
Probabil că acest grafic (sau ceva similar) se putea obţine mai simplu (şi fără a repeta comenzi, precum în secvenţa de mai sus) - dar a fost un bun prilej de a puncta elementele standard cele mai obişnuite în R, pentru formularea graficelor statistice.
Nu mai dăm aici alte exemplificări pentru funcţia "pergaps()", dar precizăm că la fel ca în cazul prezentat mai sus, putem compara subsetul celor care au susţinut proba C la "Matematică-TEHN", cu subsetul celor care au susţinut-o la "Istorie" şi putem obţine matricea procentelor pe intervale de medii pentru cei care au susţinut proba de "Limba maternă", sau pentru cei de sex "M" (versus "F"), sau pentru cei din mediul "Urban" (versus "Rural"), sau pentru cei dintr-un acelaşi judeţ, etc.
9.7 Nivelul notelor şi mediilor, pe judeţe
Putem obţine imediat (cu o singură comandă) o structură "data.frame" conţinând pentru fiecare judeţ, valorile medii pentru coloanele de note şi de "Medie" din "bac5":
aggregate(cbind(nota.A, nota.C, nota.D, Medie) ~ jud, data = bac5, FUN = mean) -> judACDM print(judACDM, digits = 3) jud nota.A nota.C nota.D Medie 1 Alba 7.74 7.96 8.12 7.94 2 Arad 7.36 7.35 7.76 7.49 3 Argeş 7.22 7.76 7.98 7.65 4 Bacău 7.68 7.78 8.06 7.84 5 Bihor 7.21 7.50 8.05 7.61 6 Bistriţa-Năsăud 7.80 7.48 7.90 7.73 7 Botoşani 7.70 7.53 8.22 7.81 8 Braşov 7.81 7.80 7.97 7.84 9 Brăila 7.55 7.75 7.96 7.75 10 Buzău 7.54 7.64 8.03 7.73 11 Caraş-Severin 7.54 7.32 7.72 7.53 12 Cluj 7.73 7.89 8.03 7.89 13 Constanţa 7.34 7.64 7.90 7.63 14 Covasna 7.15 7.64 7.81 7.66 15 Dâmboviţa 7.80 7.47 8.01 7.76 16 Dolj 7.28 7.56 7.97 7.60 17 Galaţi 7.37 7.85 8.02 7.74 18 Gorj 7.83 7.41 7.82 7.68 19 Harghita 6.55 7.53 7.98 7.46 20 Hunedoara 7.66 7.51 7.88 7.68 21 Ialomiţa 7.38 7.56 7.95 7.63 22 Iaşi 7.76 8.00 8.11 7.95 23 Ilfov 7.03 6.69 7.35 7.02 24 Maramureş 7.42 7.70 7.94 7.68 25 Mehedinţi 7.69 7.52 8.04 7.75 26 Mureş 7.35 7.70 7.96 7.71 27 Neamţ 7.51 7.90 8.10 7.83 28 Olt 7.61 7.35 8.11 7.69 29 Prahova 7.76 7.91 8.03 7.90 30 Satu-Mare 7.60 7.66 7.87 7.71 31 Sălaj 7.46 7.67 7.95 7.72 32 Sibiu 7.69 7.78 8.06 7.83 33 Suceava 7.54 7.63 8.08 7.75 34 Teleorman 7.21 7.15 7.89 7.41 35 Timiş 7.80 7.50 7.87 7.72 36 Tulcea 7.84 7.69 7.92 7.81 37 Vaslui 7.18 7.71 8.05 7.64 38 Vâlcea 7.63 7.66 8.02 7.77 39 Vrancea 7.64 7.90 8.01 7.84 40 M.Bucureşti 7.66 7.75 7.92 7.77 41 Călăraşi 7.37 7.27 7.76 7.46 42 Giurgiu 6.85 7.20 7.75 7.26
Dar oare sunt corecte aceste rezultate?! În coloanele 'nota.A' şi 'nota.C' avem câte o singură valoare sub 7; ar reieşi că mediile pe ţară la probele A şi respectiv C sunt peste 7 - ori boxplot-ul redat în §9.6 ne-a arătat că acestea sunt totuşi sub 7 (media la A este 6.816, iar la C este 6.618)! În treacăt să observăm că se cuvine să ne dăm seama că nu are sens să modelăm şi grafic, mediile judeţene redate mai sus: marea majoritate a acestora, pe toate coloanele sunt între 7 şi 8 (dacă toate barele au cam aceeaşi înălţime - ce sens are să le desenezi pe toate?).
Rezultatele sunt corecte, dar nu pentru ceea ce ni se părea că am vrea să obţinem. Funcţia aggregate() ignoră (în mod implicit) valorile 'NA'; pentru formule cu o singură coloană, rezultatul va fi cel aşteptat - dar aici avem patru coloane şi vor fi păstrate pentru calcul numai înregistrările care nu conţin niciun 'NA' în coloanele respective (de exemplu, (2.50, 5.50, 8.25, NA) va fi exclusă, deşi ea ar conta la calculul mediei pe primele trei coloane).
În coloana 'Medie' avem 'NA' în acele înregistrări pentru care măcar în una dintre coloanele de note la probele respective avem sau 'NA', sau o notă mai mică decât 5. Prin urmare, ceea ce am obţinut mai sus reprezintă mediile judeţene pentru 'nota.A', 'nota.C', 'nota.D' şi 'Medie' luând în consideraţie numai acele valori de pe coloanele respective din "bac5" care sunt cel puţin egale cu 5 (dat fiind că metodologia oficială prevede calculul de 'Medie' numai în cazul când la toate probele s-a obţinut cel puţin 5); în "judACDM", coloana 'Medie' este chiar media aritmetică a celor trei coloane de note.
Dacă totuşi, am vrea să luăm în consideraţie toate notele (inclusiv cele mai mici de 5, excluse mai sus) - cum putem proceda? Cel mai comod este să folosim pachetul dplyr:
require(dplyr) judACDMw <- bac5 %>% group_by( jud ) %>% summarise_at( c(19, 21, 22, 25), mean, na.rm = TRUE )
Operatorul "%>%" comunică obiectul din partea stângă a sa, funcţiei din dreapta - permiţând înlănţuirea unor comenzi, fiecare prelucrând rezultatul celei precedente (de exemplu, în loc de formularea obişnuită head(judACDM) - prin care afişăm primele 6 linii din 'judACDM' - putem folosi bac5 %>% head). Prin comanda "compusă" redată mai sus, se grupează înregistrările din "bac5" după valorile câmpului 'jud' şi apoi se determină pentru fiecare grup valoarea medie pentru fiecare dintre coloanele de note şi medii ('nota.A' este coloana de rang 19 din "bac5", ş.a.m.d.), excluzând de fiecare dată (prin specificarea 'na.rm=TRUE') valorile 'NA' (pe fiecare coloană în parte, nu ca în cazul folosirii funcţiei aggregate(), mai sus).
Pe coloana 'Medie' avem aceleaşi valori ca în "judACDM", fiindcă în ambele cazuri s-au exclus exact aceleaşi valori 'NA'; dar pe celelalte coloane avem acum valori mai mici (fiindcă acum s-au considerat şi notele sub 5), iar 'Medie' nu mai este media aritmetică a coloanelor de note:
print(as.data.frame(judACDMw), digits=3) jud nota.A nota.C nota.D Medie 1 Alba 7.20 7.16 7.35 7.94 2 Arad 6.54 6.12 6.79 7.49 3 Argeş 6.60 6.77 7.04 7.65 4 Bacău 7.30 7.21 7.56 7.84 5 Bihor 6.33 6.61 7.32 7.61 6 Bistriţa-Năsăud 7.17 6.66 7.19 7.73 7 Botoşani 7.21 6.74 7.63 7.81 8 Braşov 7.46 7.31 7.48 7.84 9 Brăila 7.20 7.25 7.52 7.75 10 Buzău 6.97 6.65 7.14 7.73 11 Caraş-Severin 6.78 6.02 6.57 7.53 12 Cluj 7.43 7.47 7.59 7.89 13 Constanţa 6.28 6.14 6.49 7.63 14 Covasna 6.07 6.55 6.95 7.66 15 Dâmboviţa 6.87 6.05 6.80 7.76 16 Dolj 6.45 6.29 6.78 7.60 17 Galaţi 6.94 7.20 7.43 7.74 18 Gorj 6.64 5.76 6.19 7.68 19 Harghita 5.25 6.34 6.96 7.46 20 Hunedoara 7.03 6.51 7.05 7.68 21 Ialomiţa 6.83 6.64 7.14 7.63 22 Iaşi 7.32 7.32 7.46 7.95 23 Ilfov 5.84 5.13 6.05 7.02 24 Maramureş 6.67 6.76 7.16 7.68 25 Mehedinţi 6.44 5.63 6.32 7.75 26 Mureş 6.65 6.82 7.22 7.71 27 Neamţ 6.90 7.01 7.25 7.83 28 Olt 6.59 5.73 6.64 7.69 29 Prahova 7.29 7.15 7.29 7.90 30 Satu-Mare 7.06 6.99 7.25 7.71 31 Sălaj 6.60 6.33 6.78 7.72 32 Sibiu 7.27 7.22 7.42 7.83 33 Suceava 6.89 6.68 7.28 7.75 34 Teleorman 5.78 5.07 6.17 7.41 35 Timiş 7.07 6.44 6.95 7.72 36 Tulcea 7.20 6.74 7.17 7.81 37 Vaslui 6.65 6.83 7.26 7.64 38 Vâlcea 6.86 6.40 6.91 7.77 39 Vrancea 7.04 6.94 7.25 7.84 40 M.Bucureşti 7.00 6.81 7.04 7.77 41 Călăraşi 6.44 5.85 6.46 7.46 42 Giurgiu 5.51 5.04 5.83 7.26
Diferenţele coloanelor de acelaşi nume din cele două tabele produc indirect unele informaţii referitoare la notele mai mici ca 5, pentru judeţele respective; de exemplu:
range(judACDM$nota.A - judACDMw$nota.A) [1] 0.3020285 1.4211119
range() ne dă valoarea minimă şi pe cea maximă din vectorul primit (în cazul de faţă, din vectorul diferenţă a celor două coloane); diferenţa minimă 0.30 corespunde judeţului Cluj şi ar însemna că dintre toate judeţele, în Cluj au fost cele mai puţine sau/şi cele mai mari note sub 5, la proba A; diferenţa maximă 1.42 corespunde judeţului Teleorman - deci aici au fost cele mai multe sau/şi cele mai mici note sub 5 la proba A, dintre toate judeţele.
9.8 Intervalele de note şi de medii, pe judeţe
Desigur, cel mai firesc ar fi să vizăm numai mediile finale, clasificându-le pe intervalele [5, 6), [6, 7), etc. (pe fiecare judeţ); totuşi, complicăm lucrurile - vizând şi coloanele de note (considerând pentru ele şi intervalul [1, 5), exclus la 'Medie'). Pentru un judeţ, putem găsi procentele notelor şi mediilor pe fiecare interval folosind funcţia "pergaps()" din §9.6 - de exemplu:
cluj <- subset(bac5, jud == "Cluj") pergaps(cluj, materna = TRUE) [[1]] # procente, pe intervale de medii [[2]] # numărul de participanţi gap nota.A nota.B nota.C nota.D Medie nota.A nota.B nota.C nota.D Medie 1 [1,5) 3.34 0.73 5.98 7.31 0.00 4884 550 4881 4873 4287 2 [5,6) 15.60 9.82 15.63 11.68 5.97 3 [6,7) 15.38 13.27 13.91 12.64 18.36 4 [7,8) 20.76 23.64 17.78 17.24 24.45 5 [8,9) 26.88 24.55 20.67 23.27 31.26 6 [9,10] 18.04 28.00 26.02 27.87 19.97
Am ales aici judeţul Cluj, pentru că acolo s-a susţinut şi proba de "Limba maternă" (oferindu-ne prilejul de a folosi parametrul 'materna', în apelul funcţiei pergaps()).
Să încercăm să iterăm pergaps() pentru toate cele 42 de judeţe. Teama firească este aceea de a avea o durata excesivă a execuţiei; în plus, rezultatele de la fiecare iteraţie (pentru fiecare judeţ) având o aceeaşi structură - se cuvine să le reunim într-un unic obiect (care va servi şi pentru o eventuală sinteză grafică). Ţinând cont de aceste aspecte, rescriem vechea funcţie pergaps() - încorporând iterarea pe judeţe şi reunirea rezultatelor:
perJudGaps <- function() { require(dplyr) # facilitează gruparea, selectarea coloanelor, ordonarea după judeţe cols <- c(19, 21, 22, 25, 26) # coloanele de note (A, C, D), 'Medie' şi 'jud' sjdf <- bac5 %>% group_by(jud) %>% select(cols) %>% arrange(jud) %>% as.data.frame lsdf <- split(sjdf, sjdf$jud) # listă cu 42 de 'data.frame' (câte una pe judeţ) breaks = c(1, 5:9, 10.01) # limitele standard ale intervalelor de note nume <- c("A", "C", "D", "mb") # denumiri simplificate faţă de 'names(bac5)[cols[-5]]' for(j in 1:42) { sdf <- lsdf[[j]] proc <- data.frame(gap = c("[1,5)","[5,6)","[6,7)","[7,8)","[8,9)","[9,10]")) # în "proc" vom adăuga coloane cu procentele pe probe şi pe intervalele "gap" for(k in 1:3) { # fără coloana 'Medie' (unde nu avem intervalul [1, 5)) lim <- cut(sdf[, k], breaks=breaks, right=FALSE) # clasifică notele pe intervale proc[k+1] <- aggregate(sdf[, k] ~ lim, sdf, length)[2] # contorizează pe intervale } # pentru coloana "Medie", exclude intervalul "[1, 5)" m5 <- aggregate(sdf[, 4] ~ cut(sdf[, 4], breaks=breaks[-1], right=FALSE), sdf, length)[2] proc[5] <- c(0, m5[[1]]) # pune 0 pentru procent elevi cu "Medie" < 5 names(proc)[2:5] <- nume # redenumeşte coloanele din 'proc' nelevi <- lapply(proc[2:5], sum) # numărul total de elevi, pe fiecare coloană proc[2:5] <- round(proc[2:5]/nelevi, 4)*100 # procentul elevilor, pe interval de medii lsdf[[j]] <- proc # înlocuim în lista iniţială } return(lsdf) # pe fiecare judeţ - procentele pe intervalele de note şi medii }
Funcţia "perJudGaps()" constituie şi returnează un obiect de clasă 'list' cu 42 de componente de clasă 'data.frame', fiecare conţinând procentele de note la probe şi de medii corespunzătoare câte unui interval de medii, pentru judeţul respectiv:
lpjg <- perJudGaps() lpjg[1] # prima componentă din listă $Alba # names(lpjg)[1] (numele elementelor listei - aici, numele judeţelor) # "data.frame" pentru procentele de note la probe şi de medie finală, pe intervale de medii: gap A C D mb 1 [1,5) 6.87 12.60 12.57 0.00 2 [5,6) 19.39 16.53 9.97 6.09 3 [6,7) 16.23 11.78 13.35 18.63 4 [7,8) 16.30 14.82 15.68 23.30 5 [8,9) 22.49 17.62 21.28 27.77 6 [9,10] 18.71 26.64 27.15 24.21
Să transformăm această listă într-un 'data.frame' (cum cer de obicei funcţiile de reprezentare grafică), în care să mai adăugăm o coloană 'factor' pentru judeţele de care ţin înregistrările:
do.call("rbind", lpjg) -> pjg.df pjg.df$jud <- as.factor( c( rep(names(lpjg), each = 6) ) ) str(pjg.df) 'data.frame': 252 obs. of 6 variables: $ gap : Factor w/ 6 levels "[1,5)","[5,6)",..: 1 2 3 4 5 6 1 2 3 4 ... $ A : num 6.87 19.39 16.23 16.3 22.49 ... $ C : num 12.6 16.5 11.8 14.8 17.6 ... $ D : num 12.57 9.97 13.35 15.68 21.28 ... $ mb : num 0 6.09 18.63 23.3 27.77 ... $ jud : Factor w/ 42 levels "Alba","Arad",..: 1 1 1 1 1 1 2 2 2 2 ...
Cu rbind() putem concatena mai multe obiecte data.frame; numai că în cazul de faţă, aceste obiecte sunt ambalate împreună într-un obiect 'list' - de aceea am folosit funcţia do.call(): aceasta primeşte numele unei funcţii (aici, "rbind") şi o listă de argumente (cum avem aici, lista "lpjg") şi pune în execuţie funcţia indicată, transferându-i componentele listei de argumente (adică tocmai obiectele 'data.frame' pe care voiam să le alipim).
Pentru adăugarea coloanei pjg.df$jud am folosit numele de componente existente în structura de listă "lpjg" şi - prin funcţia rep() - am repetat fiecare nume de câte 6 ori (câte corespund în "lpjg" fiecărui judeţ), transformând apoi vectorul rezultat într-un obiect de clasă factor.
Dar la ce folosesc datele obţinute mai sus? Cel mai adesea, servesc pentru comparaţii ("a... stăm bine - uite că sunt şi judeţe mai slabe ca noi!", etc.) - iar compararea după diverse criterii este mult facilitată prin vizualizarea grafică a datelor (cu minimum de detalii). Vom folosi mai jos câteva funcţii din pachetul ggplot2.
Avem aici de reprezentat valorile din mai multe coloane de numere, pe intervale de medii, pentru fiecare judeţ; în special pentru acest caz (când sunt de reprezentat mai mult de o singură coloană de valori), funcţia ggplot2::ggplot() pretinde ca structura 'data.frame' să-i fie transmisă în format "lung" - în care fiecare înregistrare are forma generică "cheie - variabilă - valoare", unde "cheie - variabilă" o identifică unic în setul de date respectiv, iar "valoare" este valoarea acelei variabile pentru linia corespunzătoare câmpurilor constitutive ale cheii.
De exemplu în cazul nostru, "Alba [1, 5) A" identifică unic valoarea 6.87 din tabelul cu 5 coloane lpjg[[1]] redat mai sus (avem "cheie formată de coloanele 'jud' şi 'gap' şi "variabilă='A').
Pentru a transforma structura 'pjg.df' în format lung, folosim funcţia reshape2::melt():
require(reshape2) pjg.long <- melt(pjg.df) # implicit, 'jud' şi 'gap' sunt utilizate ca "ID" (identifică) head(pjg.long) jud gap variable value 1 Alba [1,5) A 6.87 2 Alba [5,6) A 19.39 # ş.a.m.d.
După ce receptează setul de date ('pjg.long' în cazul de faţă), ggplot() operează stratificat: mai întâi, vede din parametrii funcţiei aes() - numele vine de la cuvântul "aesthetic" - cărei variabile trebuie să-i reprezinte valorile (numerice) şi deasemenea, cărei variabile (de regulă, de clasă "factor") trebuie să-i reprezinte valorile prin culori diferite, sau prin simboluri şi mărimi diferite; apoi (pe următorul nivel de operare, montat celui precedent prin operatorul "+") se stabileşte "geometria" reprezentării (prin bare, sau ca histogramă, prin linii, puncte, etc.) şi eventual, se calculează anumite statistici de reprezentat (după valorile indicate în parametrul "stat" al funcţiei geom_bar()); pe următoarele straturi se stabilesc "detalii" precum titluri şi inscripţionări, ce paletă de culori să fie folosită, etc., iar dacă este cazul se constituie mai multe panouri grafice (printr-o funcţie ca facet_wrap()) şi eventual, se "răstoarnă" axele de coordonate (prin coord_flip()):
require(ggplot2) require(RColorBrewer) # "Creates nice looking color palettes" - help(RColorBrewer) ggplot(pjg.long, aes(variable, value, fill = gap)) + geom_bar(stat = "identity") + ggtitle("Bacalaureat 2015") + xlab("Probele A, C, D şi media finală") + ylab("Procente") + scale_fill_brewer(palette = "Set1") + facet_wrap(~ jud, nrow = 7) + # câte un panou pentru fiecare judeţ coord_flip()

Vedem că procentul de note [1, 5) - culoarea roşie - la proba "A" este cel mai mic la Braşov, Cluj şi Sibiu (cam în această ordine) şi este cel mai mare - de multe ori mai mare - la Harghita, Giurgiu şi Teleorman; la proba "C" este cel mai mic la Cluj, Braşov şi Brăila şi este cel mai mare la Giurgiu, Teleorman şi Ilfov; iar la proba "D" culoarea roşie ocupă cel mai puţin la Brăila, Cluj şi Bacău şi cel mai mult la Giurgiu, Gorj şi Mehedinţi.
Observând culorile respective pe rândurile şi coloanele imaginii de mai sus, putem face uşor diverse alte constatări asupra procentelor pe fiecare interval de note şi de medii. Sare în ochi de exemplu, că la Ilfov şi Giurgiu culoarea galbenă ocupă cel mai puţin - adică în acestea avem cel mai mic procent de note (la cele trei probe) şi de medii în intervalul [9, 10] (cel mai mare fiind la Iaşi, Alba, Braşov, Cluj).
vezi Cărţile mele (de programare)