Noul orar (partea a patra)
[1] Noul orar (partea a treia)
[2] V.Bazon - De la seturi de date și limbajul R, la orare școlare (Google Books)
[3] V. Bazon - Orare școlare echilibrate și limbajul R (Google Books)
O clasă cu o zi de 8 ore…
Pentru a repartiza pe orele zilei, lecțiile prof|cls ale unei aceleiași zile, aducem în directorul curent programul "mount_h1.R" din [2]; dar acesta asumă că fiecare clasă are cel mult 7 ore/zi, iar în cazul nostru avem o clasă care are 8 ore într-o zi:
> dcls <- table(R12[c('cls', 'zl')]) > apply(dcls, 1, function(L) if(sum(L) > 35) L) %>% compact() $`9B` Lu Ma Mi Jo Vi 7 7 8 7 7
Inspectând lecțiile clasei 9B constatăm că dintre cele 36 de ore ale sale, 10 sunt lecții ale lui In3 (unele fiind pe „discipline secundare”); așa că decidem să eliminăm din R12 una dintre lecțiile 9B|In3|Mi (chiar dacă Mi sunt numai două):
> wh <- with(R12, which(prof=="In3" & cls=="9B" & zl=="Mi")) # [1] 808 809 > R12 <- R12[-wh[1], ] > saveRDS(R12, "R12.RDS") # rămân 835 lecții cls|prof|zl
Vom adăuga înapoi lecția respectivă (ca a 8-a oră într-una din zile, nu neapărat Mi), pe orarul final — ceea ce este desigur mai ușor decât să fi complicat, pentru această singură excepție, programul "mount_h1.R" (e drept că am avea de făcut un singur lucru important: de inclus în matricea permutărilor de 1:7 ore, pe cele de 8 ore).
Lista repartițiilor pe zile
Înființăm programul următor, în care întâi formulăm lista ldz care asociază fiecărei zile, setul lecțiilor prof|cls din acea zi (aflate în repartiția curentă R12):
## x9.R ## rm(list=ls()) # elimină variabilele păstrate din sesiunea anterioară library(tidyverse) Zile <- c("Lu", "Ma", "Mi", "Jo", "Vi") R12 <- readRDS("R12.RDS") # repartiția curentă pe zile, a lecțiilor cls|prof ldz <- map(Zile, function(z) R12 %>% filter(zl == z) %>% select(prof, cls) ) %>% setNames(Zile) # lista distribuțiilor pe fiecare zi saveRDS(ldz, "R12_ldz.RDS")
De exemplu ldz[["Lu"]] conține cele 167 de lecții prof|cls repartizate în ziua Lu. De observat că am schimbat ordinea inițială a celor două câmpuri (bineînțeles că am omis câmpul inițial "zl"), adoptând pe cea vizată în "mount_h1.R".
Subliniem că dacă pe parcurs vom modifica repartiția curentă R12, atunci (în mod normal) va trebui să reconstituim "R12_ldz.RDS".
Cuplajele, pe fiecare zi în parte
În "Tw12.Rda" avem profesorii și cuplajele între lecțiile cărora, în oricare zi, va trebui să verificăm suplimentar că nu există suprapuneri orare; dar avem nevoie să le vedem pe fiecare zi în parte.
Pregătim listele lTz1 și lTz2 care indică pe fiecare zi, dependențele între profesorii angajați în cuplaje pe acea zi (în plus, lPrz[[Z]] enumeră profesorii cu lecții în ziua Z):
twin_day <- function(ltw, prof_day) { # ltw: lista Tw1, sau Tw2 ltw[intersect(names(ltw), prof_day)] %>% map(., function(D) intersect(D, prof_day)) %>% compact() } # păstrează numai cuplajele existente în ziua curentă LSS <- readRDS("R12_ldz.RDS") # lista 'ldz' curentă load("Tw12.Rda") # [1] dicționarele Tw1 și Tw2 lPrz <- map(Zile, function(z) LSS[[z]] %>% pull(prof) %>% unique) %>% setNames(Zile) # Zi ==> toți profesorii cu lecții în acea Zi lTz1 <- map(Zile, function(zi) twin_day(Tw1, lPrz[[zi]])) %>% setNames(Zile) # angajarea/Zi în cuplaje, având și ore proprii lTz2 <- map(Zile, function(zi) twin_day(Tw2, lPrz[[zi]])) %>% setNames(Zile) # angajarea celor "fictivi", pe fiecare Zi save(lPrz, lTz1, lTz2, file="lPrTz.Rda")
În cursul alocării pe ore a lecțiilor zilei Zi, va trebui să evităm suprapunerea într-o aceeași oră a lecțiilor celor numiți în lTz1[[Zi]] și lTz2[[Zi]].
Precizăm că în general vom păstra denumirile de variabile din [2] și [3] (chiar dacă nu sunt tocmai bine alese).
Instrumentarea alocării pe ore a tuplajelor
Avem tuplaje (v. "partea întâia") pe lecțiile de "Viz/Muz" (care în orarul PDF inițial se desfășurau în cuplaj, despărțind fiecare clasă "pe grupe"); dar generasem tuplajele (v. [1]) prin funcția orar_partial_vm(), care împerechea ad-hoc clasele (în mod aleatoriu).
Ne-a scăpat din vedere să și salvăm undeva, setul tuplajelor generate; le reconstituim acum, pe zile, din R12, completându-le și cu un câmp "ora" (= 0):
tpl <- R12 %>% filter(prof %in% c("Ds1","Mz1"), grepl("[90]", cls)) %>% arrange(zl) %>% slice(-c(1, 4, 5)) %>% mutate(ora = 0L) %>% split(.$zl) %>% map(function(S) S %>% select(-zl)) > tpl # afișăm lista rezultată: $Lu $Ma $Mi $Jo $Vi cls prof ora cls prof ora cls prof ora cls prof ora cls prof ora 1 9D Ds1 0 3 10C Ds1 0 5 9A Ds1 0 7 10E Ds1 0 9 10A Ds1 0 2 9E Mz1 0 4 10D Mz1 0 6 9B Mz1 0 8 10F Mz1 0 10 10B Mz1 0 saveRDS(tpl, "tuplaje.RDS") # lista tuplajelor, pe fiecare zi
Precizări: "Viz/Muz" se face la clasele a 9-a și a 10-a, încât am putut identifica lecțiile respective folosind sub grepl() expresia regulată "[90]" (numele clasei conține "9" sau "0"); cu slice() am eliminat lecțiile (din liniile 1, 4, 5) ne-tuplate (astfel, Ds1 are o lecție pe obiect secundar la 10F, în plus față de cea din tuplajul (Ds1 Mz1)|(10E 10F); iar clasa 9F face "Desen" și "Muzică" separat, pe câte o oră (și nu pe jumătate de oră)).
Vrem să asigurăm ca lecțiile tuplate, de exemplu (Ds1 Mz1)|(9D 9E), să se desfășoare într-o aceeași oră a zilei: în ora respectivă, Ds1 intră la 9D și Mz1 intră la 9E și invers, în săptămâna următoare celei curente (însemnând că "Desen" și "Muzică" se fac pe câte „o oră la două săptămâni”, în loc de „o jumătate de oră pe săptămână”).
În momentul când, pentru ziua curentă Lu, vom ajunge să alocăm pe ore lecțiile clasei 9D, vom consulta întâi valoarea ora înscrisă în tpl$Lu clasei 9E (adică valoarea tpl$Lu[2,3]): dacă este 0, atunci putem aloca orice oră h=1..7 lecției Ds1|9D, înscriind totodată tpl$Lu[2,3]=h (încât Mz1 să intre la 9E tot în ora h a zilei Lu); iar dacă tpl$Lu[2,3] nu este 0, ci h (>0), atunci aceasta înseamnă că 9E a fost întâlnită în cursul procesului de alocare a lecțiilor pe ore, înaintea clasei curente 9D și lui Mz1 i s-a alocat deja o anumită oră h — tot ora h, trebuie alocată și lui Ds1, la clasa 9D.
Desigur, încercarea curentă de alocare a orei h la clasa 9D sau la clasa 9E, pentru Ds1 sau Mz1, poate să eșueze: oricum s-ar alege h între 1 și 7, în acea oră h ar rezulta o suprapunere de lecții; în acest caz, se vor anula din nou, valorile câmpului "ora" corespunzătoare în tpl$Lu celor doi profesori (urmând ca alocarea pe ore a lecțiilor zilei curente să fie reluată de la capăt, într-o altă ordine a claselor și profesorilor).
Ordinea parcurgerii claselor
Vom aborda clasele, în vederea alocării pe ore a lecțiilor fiecăreia, într-o „ordine aleatorie” — schimbând ordinea și reluând parcurgerea, de fiecare dată când încercarea curentă nu reușește până la capăt; dar dacă n-am distinge cumva, între clase (considerând șanse egale de a fi alese, pe parcurs), numărul de reluări (până se nimerește o ordine în care alocarea nu se mai blochează la clasa curentă) ar crește cel mai probabil, prea mult (ceea ce am și constatat prin experimente, în [3]).
Constituim pe fiecare zi (folosind pachetul igraph) grafurile de profesori și de clase, care reflectă existența în acea zi, a unor clase comune, respectiv a unor profesori comuni — și reținem în BTW.rda coeficienții "betweenness" ai nodurilor (cu intuiția, justificată în [3], că parcurgând lecțiile în ordini „apropiate” celei crescătoare a acestor coeficienți, vom obține cel mai rapid, un orar complet al zilei).
Mai întâi, în cadrul unui nou program $\mathbf{R}$, prevedem o funcție prin care să obținem un „dicționar” necesar ulterior pentru a defini prin matricea de adiacență, graful profesorilor și respectiv, graful claselor: se asociază profesorilor câte un vector conținând clasele fiecăruia, respectiv se asociază claselor câte un vector conținând profesorii fiecăreia:
# between.R ("betweenness" în graful profesorilor şi graful claselor) rm(list=ls()) library(tidyverse) load("Tw12.Rda") # [1] Tw1 și Tw2 Zile <- c("Lu", "Ma", "Mi", "Jo", "Vi") library(igraph) dict_col <- function(LSS, col) { col1 <- enquo(col) col2 <- quo(setdiff(colnames(LSS), as_label(col1))) FxS <- LSS %>% distinct(!!col1) %>% pull() SxF <- map(FxS, function(X) LSS %>% filter(!!col1 == X) %>% select(!!col2) %>% distinct() %>% pull()) names(SxF) <- FxS SxF # dicţionar {profesor ==> vectorul claselor proprii}, sau # dicţionar {clasă ==> vectorul profesorilor clasei} } Z <- readRDS("R12_ldz.RDS") # lista distribuțiilor pe fiecare zi
dict_col() trebuie apelată furnizând ca argument 'col' fie prof (fără ghilimele), fie cls — variabile (nu șiruri de caractere) care referă câte una dintre coloanele setului LSS (de lecții ale zilei). În corpul funcției, enquo(col) asociază variabilei col primită ca argument, o anumită expresie funcțională care atunci când va fi citată sub operatorul ’!!’ într-un context în care există LSS (de exemplu, după ”LSS
%>% ...”), va produce valorile din coloana respectivă a lui LSS. De exemplu:
> source("between.R") > dict_col(Z[[1]], cls)[["11D"]] # profesorii clasei [1] "Bl3" "Mt4" "Fz1" "Ch2" "Gr2Gr1" "TI1" > dict_col(Z[[1]], prof)[["Gr2Gr1"]] # clasele profesorului (sau cuplajului) [1] "11D" "12D" "9D"
Următoarea funcție construiește „graful claselor”, considerate câte două ca adiacente, dacă au măcar un profesor comun (dar o să înscriem chiar numărul acestora):
graph_cls <- function(LSS) { lcp <- dict_col(LSS, cls) # {clasă ==> vectorul profesorilor clasei} Cls <- names(lcp) len <- length(Cls) adjm <- matrix(rep(0, len), nrow=len, ncol=len, byrow=TRUE, dimnames = list(Cls, Cls)) # matricea de adiacenţă adj2cls <- function(K1, K2) # numărul profesorilor comuni celor două clase length(intersect(lcp[[K1]], lcp[[K2]])) # > 0 pentru adiacență simplă for(K1 in Cls) for(K2 in Cls) if(K1 != K2) adjm[K1, K2] <- adj2cls(K1, K2) graph_from_adjacency_matrix(adjm, mode="undirected") }
Analog (dar v. [3]), avem funcția graph_prof() pentru graful în care doi profesori sunt adiacenți dacă au măcar o clasă în comun.
Înființăm dicționarele care dau pentru fiecare zi, coeficienții betweenness (în ordine crescătoare) pentru graful claselor din acea zi și respectiv, cel al profesorilor:
BTW_prof <- BTW_cls <- vector("list") for(zi in Zile) { LSS <- Z[[zi]] g1 <- graph_prof(LSS) BTW_prof[[zi]] <- sort(betweenness(g1, directed=FALSE, normalized=TRUE)) + 0.0001 g2 <- graph_cls(LSS) BTW_cls[[zi]] <- sort(betweenness(g2, directed=FALSE, normalized=TRUE)) + 0.0001 } save(BTW_prof, BTW_cls, file="BTW.rda")
betweenness() apreciază „importanța” unui nod al grafului după numărul de geodezice (cele mai scurte drumuri între două noduri date) care trec prin acel nod; dar este posibil să avem și noduri care nu se află pe nicio geodezică —
deci „importanța” asociată lor va fi 0.0 și pentru a avea numai valori pozitive, am mărit puțin (cu 0.0001) valorile respective; altfel (lăsând 0, în loc de 0.0001), încercarea sample(lstCls, prob=btw_cls) — prin care am ordona aleatoriu dar „cu preferințe”, lista claselor — ar fi eșuat: "too few positive probabilities".
Redăm aici grafurile claselor pentru zilele Lu și Ma; prin mărime, nodurile reflectă coeficienții betweenness ai claselor:
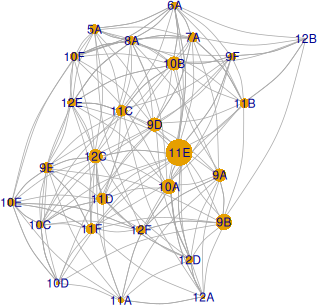
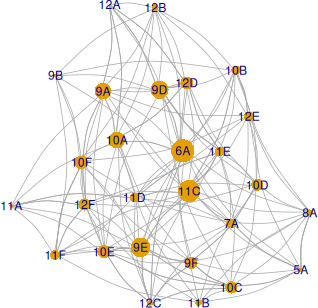
Pentru Lu, cea mai importantă clasă ar fi 11E (iar pentru Ma, clasele 11C și 6A): prin acest nod trec cel mai multe geodezice (care unesc clase cu câte măcar un profesor în comun). Fixarea orarului pentru clasa 11E (sau mai general, pentru o clasă care are coeficient betweenness mare) ar diminua posibilitățile de alocare ulterioară pentru mult mai multe clase (cele aflate pe câte o aceeași geodezică cu 11E), decât fixarea orarului clasei 12B de exemplu (al cărei coeficient este mult mai mic, decât pentru 11E).
De aceea, am ales să vizăm clasele și profesorii, în ordinea crescătoare a coeficienților betweenness (sau una apropiată cumva, de aceasta).
Montarea pe ore a lecțiilor zilei
Pentru fiecare clasă (într-o ordine aleatorie „preferențială”, urmărind crescător coeficienții betweenness) — se apelează funcția mountHtoCls() (internă funcției mount_hours()); aceasta etichetează lecțiile clasei curente cu o permutare de 1:N (unde N ≥ 4 este numărul de ore/zi ale clasei) — căutând una care nu are valori comune cu etichetări aplicate anterior altor clase, pe profesorii comuni cu cei din clasa respectivă (evitând astfel ca vreun profesor să intre în aceeași oră la două clase); se verifică deasemenea, ca prin etichetarea cu ore aplicată pe clasa curentă, niciunul dintre cei neimplicați în cuplaje să nu capete (cumulând cu alocările anterioare) mai mult de două ferestre (facilitând astfel, reducerea ulterioară a totalului de ferestre din orarul rezultat în final).
Funcția mount_hours() are ca argument setul lecțiilor prof|cls din ziua curentă și după ce instanțiază datele necesare pentru acea zi (coeficienții betweenness, dependențele induse de cuplaje și tuplaje pe ziua respectivă) — inițializează vectorul în care se vor înregistra (prin șabloane binare) alocările pe ore și începe să parcurgă lista claselor, aplicând fiecăreia funcția mountHtoCls(); dacă aceasta eșuează la clasa curentă, atunci se reinițializează vectorul alocărilor pe ore, se reordonează aleatoriu (ponderat totuși de coeficienți) lista claselor și se reia — până când se nimerește o ordine în care lista claselor este parcursă de la un capăt la celălalt (într-o singură trecere) — rezultând repartiția prof|cls|ora pentru toate lecțiile zilei, fără suprapuneri de lecții și astfel încât fiecare profesor (exceptând eventual, membrii cuplajelor) are cel mult două ferestre; iar clasele (toate) îsi încep programul de la prima oră a zilei.
Precizăm că funcțiile menționate sunt constituite în "mount_h1.R" (pe 117 linii de program obișnuite) și sunt documentate în [2] (unde le preluasem din [3] și le modificasem pentru a viza tuplajele); nu le mai reluăm aici, nefiind cazul unor modificări importante.
Dar în [2] întâlneam și tuplaje de trei profesori pe două sau trei clase, iar în cazul de față avem doar 10 tuplaje de cel mai simplu tip; dacă nu vrem să simplificăm mount_h1.R, atunci avem de făcut următoarele adaptări (de structuri și denumiri):
TUP <- readRDS("tuplaje.RDS") # tuplajele noastre, pe fiecare zi, cls|prof|ora for(zi in Zile) # adaptează la ordinea din [2], prof|cls|ora TUP[[zi]] <- TUP[[zi]] %>% select(prof, cls, ora) saveRDS(TUP, "tuplaje.RDS") zTP <- map(Zile, function(zi) TUP[[zi]]$prof) %>% # clasele din tuplaje setNames(Zile) # va fi important să referim prin Zile, nu indecși! zTC <- map(Zile, function(zi) TUP[[zi]]$cls) %>% # profesorii din tuplaje setNames(Zile) tup2 <- map(Zile, function(zi) data.frame(prof = paste0(TUP[[zi]]$prof, collapse=""), cls = paste0(TUP[[zi]]$cls, collapse=" "), ora = 0L) ) %>% setNames(Zile) saveRDS(tup2, "P23i.RDS") SPL <- "(?<=.{3})" # pentru a izola subșirurile de câte 3 caractere save(SPL, zTC, zTP, file="SPL_tupl.Rda")
În "P23i.RDS" a trebuit să înregistrăm tuplajele sub forma "Ds1Mz1 | 10A 10B | 0" (dedusă mai sus din "tuplaje.RDS", prin tup2); expresia din SPL servește în mount_h1.R pentru a extrage din șiruri ca "Ds1Mz1" (sau în [2], "Fr1Fr2Fr3Ge2"), numele profesorilor.
Programul care antrenează după descrierea de mai sus mount_hours(), decurge astfel:
# bindHours.R rm(list = ls()) # elimină obiectele din sesiunea precedentă library(tidyverse) Zile <- c("Lu", "Ma", "Mi", "Jo", "Vi") PRMh <- readRDS("lstPerm47.RDS") # matricele de permutări cu 4..7 ore/zi prnTime <- function(NL = " ") cat(strftime(Sys.time(), format="%H:%M:%S"), NL) h2bin <- as.integer(c(1, 2, 4, 8, 16, 32, 64)) # măștile binare ale orelor 1:7 cnt_holes <- function(sb) { # sb: șablonul binar al orelor profesorului bits <- which(bitwAnd(sb, h2bin) > 0) # rangurile biților '1' n <- length(bits) # numărul de biți '1' bits[n] - bits[1] + 1 - n } # Numărul de biți '0' aflați între biți '1' ("ferestre") source("mount_h1.R") # încarcă funcția mount_hours() load("Tw12.Rda") # [1] Tw1 și Tw2 load("BTW.rda") # BTW_prof și BTW_cls ("betweenness", pe zile) load("lPrTz.Rda") # lTz1 și lTz2 (dependențele cuplajelor, pe zile) P23i <- readRDS("P23i.RDS") load("SPL_tupl.Rda") LSS <- readRDS("R12_ldz.RDS") # dicționar zi ==> lecțiile prof|cls ORR <- vector("list", 5) # vom salva aici orarul zilei curente names(ORR) <- Zile prnTime('\n') # afișează timpul inițial for(zi in Zile) { ORR[[zi]] <- mount_hours(LSS[[zi]], zi) # prof|cls|ora pe zi prnTime(' \n') # afișează timpul curent } saveRDS(ORR, file = "Orar1.RDS") # alocările finale pe orele zilelor
Orelor 1:7 li s-au asociat prin vectorul h2bin, biții de ranguri 0:6 ai unui octet; astfel, alocarea pe orele zilei a lecțiilor unui profesor este reprezentată printr-un „șablon binar” de lungime 8 și verificările necesare între alocările făcute revin la „operații pe biți”. Un bit '0' aflat între doi biți '1' înseamnă atunci fereastră, iar cnt_holes() furnizează numărul de ferestre din alocarea curentă a lecțiilor unui profesor (servind în mount_hours() pentru a verifica dacă profesorul nu capătă prin alocarea curentă, mai mult de două ferestre — ceea ce de fapt… n-ar mai fi de verificat pentru cei care au mai mult de 4 ore/zi).
În cazul de față — având un număr relativ mic de clase, profesori și tuplaje (și o repartizare pe zile echilibrată) — programul se execută în doar câteva secunde:
> source("bindHours.R") > source("bindHours.R") 20:31:08 20:35:02 Lu 4 încercări 20:31:08 Lu 6 încercări 20:35:03 Ma 0 încercări 20:31:08 Ma 19 încercări 20:35:05 Mi 12 încercări 20:31:10 Mi 1 încercări 20:35:05 Jo 2 încercări 20:31:11 Jo 15 încercări 20:35:07 Vi 6 încercări 20:31:12 Vi 27 încercări 20:35:11
Desigur (având în vedere aspectele aleatorii implicate), printr-o nouă execuție se obține un alt orar, cu alte numere de încercări și cu alți timpi (timpul total rămâne totuși sub 20 secunde). Precizăm că informații ca "4 încercări" sunt afișate din mount_hours(), contorizând numărul de reluări ale procesului de alocare.
În prima dintre cele două execuții evocate mai sus, n-am pus nicio condiție asupra numărului de ferestre ale profesorilor din tuplaje (încât în orarul rezultat, Ds1 și Mz1 au într-o aceeași zi, câte una sau două ferestre). În cursul celei de-a doua execuții, la sfârșitul procesului de alocare a lecțiilor zilei curente, am verificat ca suma dintre numărul de ferestre rezultat fiecăruia dintre cei doi membri ai tuplajului să fie cel mult 1 (provocând reluarea procesului de alocare, în cazul contrar); în orarul rezultat astfel, în fiecare zi a apărut cel mult o singură fereastră, numai la unul dintre cei doi.
Orarul obținut este în „forma normală” (167 sau 168 linii prof|cls|ora); pentru a-l reda într-o formă lizibilă, putem folosi funcția hourly_matrix() din [1]-"partea a doua".
Dar pe lângă matricea orară, vrem să afișăm separat și repartizarea pe ore a tuplajelor; să ne amintim că avem tuplajele, în formă explicită, în "tuplaje.RDS" și doar avem de înscris câmpul "ora" al acestora:
actual_tupl <- function() { tupl <- readRDS("tuplaje.RDS") for(zi in Zile) { Ora <- ORR[[zi]] %>% filter(prof %in% tupl[[zi]]$prof, cls %in% tupl[[zi]]$cls) %>% count(ora) %>% filter(n > 1) %>% pull(ora) tupl[[zi]]$ora <- Ora } tupl } actt <- actual_tupl()
Filtrarea după $prof și $cls include și eventualele ore proprii ale membrilor tuplajelor, așa că a trebuit (prin count(ora) și filter(n > 1)) să contorizăm valorile din câmpul ora, ignorând pe cele care apar o singură dată (pentru tuplaj, ora are o aceeași valoare, deci vom avea n=2).
Acum putem înscrie într-un fișier-text orarele respective (în format lizibil), astfel:
sink("mOrar1.txt") for(zi in Zile) { print(zi) print(actt[[zi]]) hm <- hourly_matrix(ORR[[zi]]) hm <- hm[order(rownames(hm)), ] print.table(hm) cat("\n") } sink()
Redăm aici un fragment al unuia dintre orarele rezultate:
[1] "Lu" prof cls ora # orarul tuplajului 1 Ds1 9D 2 # în săptămâna următoare: 9E 2 Mz1 9E 2 # în săptămâna următoare: 9D 1 2 3 4 5 6 7 Bl1 11E - 12D - 9B 12A - Bl2 6A 8A 10F - - - - Bl3 12C 11D 10C - - - - CD1 11C 12A - - - - - Ch1 - - 11C 8A 9A 12E 10B Ch2 - 11E 10A 11D 12D 12C - Ds1 - 9D - 10F 7A - - Ec1 - - 10D 11E 11F 10C - En1 - - - 10D - 9B 9E En2 - - 11B - - 12B 7A En3 5A 6A - 11C - - - En4 10A - - - - - - En4En2 - - - - 10A - - En4En3 - - 9A - - - - En5 - - 10B - 9F - - En5En1 11A 11A - - - - - Fl1 12D 12F - - - - -
Fiindcă am ordonat matricea orară după numele profesorilor, cuplajele și membrii acestora apar pe linii vecine, încât este ușor de socotit ferestrele acestora.
En1 are 5 ore (primele două în cuplajul En5En1), cu două ferestre (una „ascunsă” în ora a 3-a și una în ora a 5-a).
En2 are 4 ore, cu o singură fereastră (în ora a 4-a; ora a 5-a este acoperită de cuplajul En4En2). En3 are o fereastră „falsă”, fiind acoperită de cuplajul En4En3.
En4 intră la 10A de două ori (prima oră singur, apoi în ora 5 "pe grupe", împreună cu En2) și în ora a 3-a intră la 9A în cuplajul En4En3 — deci are fereastră în orele 2 și 4.
Socotind și ferestrele celor neangajați în cuplaje, pe orarele rezultate (în oricare execuție) avem cam câte 30 de ferestre — ceea ce este desigur, prea mult…
Reducerea numărului de ferestre
vezi Cărţile mele (de programare)