Orar pe o școală fără profesori (I)
[1] Deducerea încadrării, de pe "Orarul general clase"
[2] V.Bazon - De la seturi de date și limbajul R, la orare școlare (Google Books)
[3] V. Bazon - Orare școlare echilibrate și limbajul R (Google Books)
Peste tot… orare, fel de fel
Fapt comun: cabinetele medicale (probabil și altele) au câte un orar de funcționare, expus pe ușă sau chiar și pe Internet; ar fi cel mai simplu caz de orar: sunt doi-trei medici ("Dr. Nume Prenume", "Dr. Nume Prenume", etc.) care în anumite zile partajează cabinetul în intervale orare disjuncte.
Am auzit adesea, de pacienți nemulțumiți de faptul că medicii respectivi nu prea respectă orarul afișat; dar n-am aflat să fie vreun doctor, nemulțumit de faptul că "Nume Prenume"-le său este afișat public…
Școlile funcționează și ele, pe baza câte unui orar, dar mult mai complicat de constituit… În loc de doi-trei medici care să asigure consultații în cabinetul respectiv, avem profesori (și mulți) care trebuie să ofere lecții (sau "consultații") pe specialitatea fiecăruia, mai multor clase de elevi (aflați în câte un "cabinet" al școlii); medicii deservesc pacienții cam în ordinea în care aceștia ajung în sala de așteptare; profesorii încadrați în școală, pe diverse discipline, deservesc clasele școlii respective, dar în acest caz nu mai poate fi vorba de vreo coadă de așteptare: în fiecare interval orar, clasele trebuie "deservite" simultan, de câte unul dintre profesori, iar asigurarea nesuprapunerii lecțiilor devine foarte complicată (dar posibilă, datorită reglementărilor compatibile între ele, asupra numărului de ore pe discipline, pe clase și pe profesori).
În ultimul timp a mai apărut o nuanță de substanță (dar artificială), între cele două categorii de orar: spre deosebire de numele doctorilor, numele profesorilor se cer anonimizate — conform chipurile, cu "legea drepturilor personale"…
Iar orarele publicate pe site-urile unor școli deja nu mai sunt orare școlare propriu-zise, lipsindu-le ingredientul principal — profesorii; "anonimizarea" a fost dusă la extrem, confundând-o, în absența unei minime inspirații, cu eliminarea. Cu alte cuvinte… pe site-urile respective apar orare pentru școli fără profesori.
Restricția artificială apărută (dinafara lucrurilor) se poate totuși depăși, cu un minim efort inspirațional: profesorii ar putea fi anonimizați (fără a-i exclude), îmbinând o abreviere a disciplinei principale pe care au fost încadrați în școala respectivă, cu un număr de ordine în lista celor încadrați pe o aceeași disciplină; iar procedând astfel, se vor simplifica și procedurile de constituire a unui orar.
Am mai folosit anterior această idee (v. [2] de exemplu), iar acum o reluăm pentru a inventa profesorii care lipsesc de pe "orarul pe clase" prezentat pe site-ul unei anumite școli; bineînțeles, convenind asupra încadrării profesorilor (absentă inițial), vom fi conduși la un nou orar, dar acum unul "propriu-zis" (doar că nu pentru încadrarea reală a școlii, necunoscută, ci pentru o încadrare fictivă, dintre cele posibile).
Precizăm că ne-am ocupat și în [1], de "a inventa profesorii"; dar acum vom avea de-a face cu un "orar" (fără profesori) care chiar merită atenție — fiind unul dintre puținele exemple aflate, de orar (probabil) echilibrat: nu avem clasă cu 4 ore într-o zi și cu 7 sau 8 ore într-o altă zi; nu avem clasă care să-și înceapă programul de la a doua oră a zilei și nu de la prima; lecțiile pe o aceeași disciplină sunt alocate cam câte una pe zi, la fiecare clasă (în loc să fie înghesuite în două-trei zile). Dar despre profesori nu știm nimic: sunt echilibrate și orarele individuale ale lor?
Iar disciplinele sunt corect denumite (nu sunt scrise cu majuscule și nu sunt referite indecent prin jargonul "mate"). Singurul defect vizibil ar fi eludarea literelor românești: apare "Lb. Romana", dar singura formă corectă este "Română"…
Orarul școlii, ca „formă fără fond”
Pe site-rile școlilor găsim pe undeva și câte un link micuț intitulat "Orar"; urmându-l, ne așteptăm să vedem și să putem aprecia (din afara școlii) activitatea de bază care se desfășoară în școala respectivă. Să vedem…
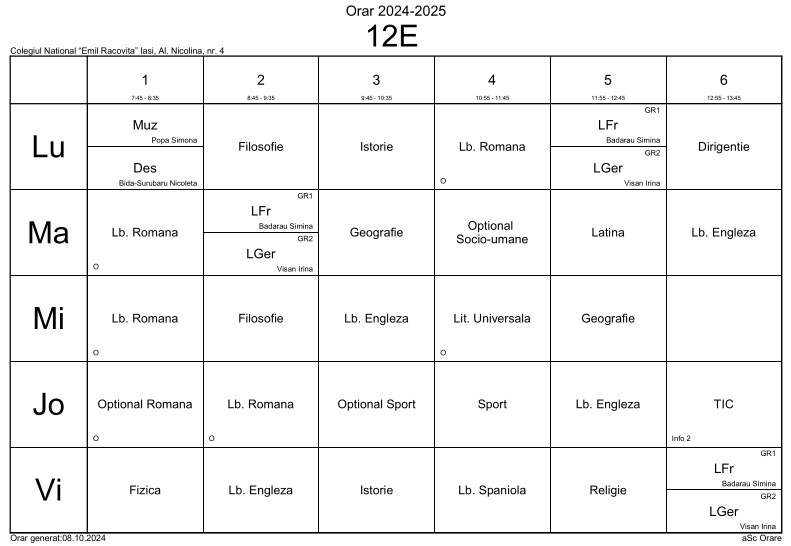
Am reprodus aici ultima dintre cele 34 de pagini ale fișierului PDF în care este redat "orarul școlii" (generat, cum vedem în subsolurile paginilor, prin "aSc Orare", adică folosind aplicația comercială de la ascTimetables).
Fiecare pagină explicitează ca "tabel Excel", orarul câte uneia dintre clasele școlii — într-o formă care este utilă elevilor clasei respective (dar numai acestora): vede fiecare obiectul fiecărei ore (de la prima, la ultima) din ziua curentă. Profesorii care fac lecțiile respective nu sunt menționați (elevii clasei își cunosc desigur, profesorii), cu excepția cazurilor când clasa este despărțită în "GR1" și "GR2" (vizualizate în tabel prin grupuri de două celule colapsate vertical; desigur, se putea nota mai simplu (dar mai bine), pe câte o singură celulă, "Muz / Des" și "Fr / Ger" — dar probabil că aceasta însemna să intervii direct asupra rezultatelor produse de ascTimetables…).
Dacă așa stau lucrurile, fără profesori și cu clase izolate între ele, atunci putem presupune că sunt oricâți profesori ar fi necesari și putem adăuga celor 34 de clase oricâte alte clase dorim, specificând în noi pagini PDF tabele Excel de aceeași formă cu cele existente, conținând pe zile și ore orice obiecte dintre cele existente deja… Fiind suficienți profesori, nu avem a ne face griji că două lecții pe un același obiect la clase diferite, s-ar suprapune în timp.
Însă lucrurile nu stau așa, într-un orar propriu-zis; orarul oricăreia dintre clase depinde de orarele altor clase. Profesorii nu sunt "oricât de mulți" și fiecare este încadrat pe disciplina respectivă la mai multe clase — astfel că dacă la una dintre acestea i s-a alocat ora 1 din ziua Vi, atunci la oricare dintre celelalte clase din încadrarea sa, nu se mai poate aloca tot Vi|1 pentru lecția respectivă (altfel ar însemna că profesorul respectiv intră în același timp la două clase distincte…).
Cu alte cuvinte, lecțiile înregistrate într-un orar "propriu-zis" sunt tupluri cls | obj | prof (în care obj nu este obligatoriu), dispuse pe zile și ore sub condiția esențială ca oricare două tupluri distincte (pe cls sau pe prof) să nu se suprapună în timp.
La 12E avem Vi|1|fizica (și vedem pe imaginea redată mai sus că este singura oră „străină” să zicem, față de celelalte, aflate probabil în zona "umanistă"); dar filând celelalte pagini, găsim tuplajele 06C|Vi|1|fizica și 08D|Vi|1|fizica — ceea ce înseamnă (pentru a evita suprapunerea Vi|1) că sunt cel puțin trei profesori încadrați pe fizica (iar aceștia puteau fi indicați fără a încălca vreo lege, prin "Fi1", "Fi2" și "Fi3").
Cam așa, căutând suprapunerile, vom putea deduce numărul minim de profesori încadrați pe câte o aceeași disciplină… Desigur, excludem procedeul manual tocmai exemplificat, de a răsfoi paginile PDF pentru a găsi pentru fiecare dintre disciplinele existente, suprapunerile într-o aceeași zi și oră.
Setul "mot-à-mot" al datelor din orarele PDF
Datele vizualizate în cele 34 pagini PDF sunt valori ale variabilelor independente cls (numele claselor), obj (numele disciplinelor), zl (zilele de lucru) și ora (orele zilei, 1:7); deocamdată neglijăm variabila prof, fiindcă în PDF-ul respectiv numele profesorilor nu sunt vizualizate (decât pentru lecțiile "pe grupe").
Pentru a ajunge la datele respective, întâi transformăm fișierul PDF în fișier ".xlsx" (de exemplu prin serviciul oferit gratuit de Adobe, pdf-to-excel) și apoi în fișier-text "orar-24.csv" — pe care eliminăm (prin comenzi Perl / awk / sed, sau operând direct într-un editor de text) liniile corespunzătoare antetelor de pagină și pe cele pe care erau specificate pentru fiecare clasă, intervalele orare "7:45 - 8.35" etc.
În cel mai simplu caz (când nu există celule colapsate "GR1" / "GR2"), orarul uneia dintre clase arată astfel (pe exact 7 linii):
# Orarul clasei, în format Comma Separated Values (CSV) ,,,,,,05B,,,,,,,,,,,,,,,,, ,1,,,2,,,,3,,,4,,,,,5,,,,,6,, Lu,"Lb. Romana",,,"Optional Romana",,,,Sport,,,"Educatie Sociala",,,,,Matematica,,,,,,, Ma,Istorie,,,Sport,,,,Matematica,,,Religie,,,,,"Lb. Romana",,,,,,, Mi,"Lb. Romana",,,"Lb. Engleza",,,,Matematica,,,Dirigentie,,,,,Tehnologie,,,,,,, Jo,"Lb. Romana",,,Matematica,,,,Biologie,,,Istorie,,,,,Muzica,,,,,"Lb. Franceza",, Vi,"Lb. Franceza",,,Desen,,,,Geografie,,,"Informatica si TIC\nInfo 1",,,,,"Lb. Engleza",,,,,,,
Să observăm că numele clasei (aici, 05B) apare pe a 7-a coloană (sunt 6 virgule înainte, fiecare separând o valoare de cea următoare ei pe linie).
Între ora 1 și ora 2 (și analog, pentru celelalte coloane orare) avem 3 virgule (,1,,,2,) — reflectând faptul că în tabelul Excel, pentru lecțiile din prima oră s-au rezervat 3 celule consecutive (pe coloanele notate în Excel prin B, C și D), în scopul de a cuprinde și denumiri mai lungi (precum "Informatica Aplicatii", sau "Optional Matematica", apărute la alte clase, de-a lungul fișierului).
Constituim un prim set de date, deocamdată reflectând mot-à-mot datele înregistrate în orarele claselor:
library(tidyverse) Ocl <- read.csv("orar-24.csv", header = FALSE) > str(Ocl) ## 'data.frame': 296 obs. of 24 variables: $ V1 : chr "" "" "Lu" "Ma" ... $ V2 : chr "" "1" "Matematica" "Tehnologie" ... $ V3 : chr "" "" "" "" ... $ V4 : chr "" "" "" "" ... $ V5 : chr "" "2" "Biologie" "Matematica" ... $ V6 : chr "" "" "" "" ... $ V7 : chr "Clasa 05A" "" "" "" "" "" "" "05B" "" "" ... $ V8 : chr "" "" "" "" ... $ V9 : chr "" "3" "Lb. Romana" "Lb. Engleza" ... $ V10: chr "" "" "" "" ... $ V11: chr "" "" "" "" ... $ V12: chr "" "4" "Educatie Sociala" "Lb. Engleza" ... $ V13: chr "" "" "" "" ... $ V14: chr "" "" "" "" ... $ V15: logi NA NA NA NA NA NA ... $ V16: chr "" "" "" "" ... $ V17: chr "" "5" "Sport" "Istorie" ... $ V18: chr "" "" "" "" ... $ V19: chr "" "" "" "" ... $ V20: chr "" "" "" "" ... $ V21: logi NA NA NA NA NA NA ... $ V22: chr "" "6" "Dirigentie" "" ... $ V23: chr "" "" "" "" ... $ V24: chr "" "" "" "" ...
Cele 296 observații pentru cele 24 de variabile reflectă de fapt cele 296 de rânduri și coloanele A-X ale fișierului Excel:
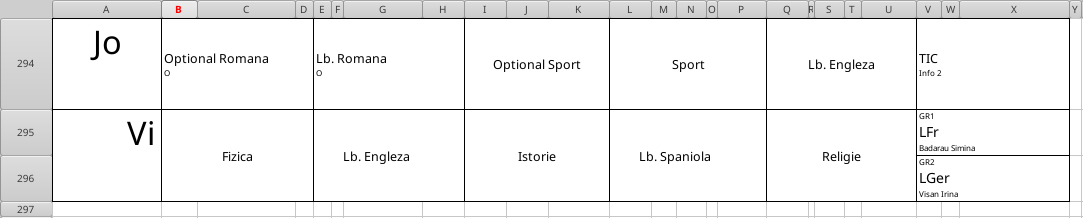
Am redat ultimele 3 rânduri Excel, pentru a evidenția că pentru lecțiile "pe grupe" există câte două rânduri: pe rândul 295 se înregistrează "Vi fizica ... Religie" și în coloana V (a 22-a) "GR1\nLFr", iar pe rândul 296 se înregistrează numai "GR2\nLGer", în coloana 22 (analog, pentru celelalte cazuri "GR1 / GR2").
Nu avem de ce să păstrăm rândurile care conțin "GR2", într-o coloană sau alta (avem și cazuri când există două astfel de coloane); pentru exemplul de mai sus, pe linia 295 o să înlocuim valoarea din coloana 22 cu "LFr/LGer" și o să eliminăm apoi, linia 296.
Având nevoie și de indicele de linie și de cel de coloană din setul Ocl, cel mai prudent este să operăm linie cu linie și coloană după coloană; când pe linia curentă i găsim "GR1" în coloana j, reținem disciplina (conținutul „din mijloc”, cuprins între '\n' și '\n'), aflăm și disciplina din linia următoare i+1 și aceeași coloană j, apoi alipim cele două discipline (separându-le prin '/') ca nouă valoare a câmpului Ocl[i,j]:
i <- 1 nc <- ncol(Ocl) while(i < nrow(Ocl)) { for(j in 1:nc) { if(grepl("GR1", Ocl[i, j])) { ob1 <- str_extract(Ocl[i, j], ".*\\n(.*)\\n", group=1) ob2 <- str_extract(Ocl[i + 1, j], ".*\\n(.*)\\n", group=1) Ocl[i, j] <- paste0(ob1, "/", ob2) } } i <- i + 1 }
Iar acum excludem liniile care conțin în vreun câmp, "GR2":
Ocl <- Ocl %>% filter(if_all(everything(), ~ !grepl("GR2", .x)))
(precizăm că everything() selectează toate coloanele, iar ".x" desemnează coloana curentă; '~' este o „scurtătură” pentru o funcție anonimă, care în cazul de față returnează TRUE dacă în coloana respectivă nu apare "GR2")
Acum ar trebui ca pentru fiecare clasă (dintre cele 34) să avem câte exact 7 linii (linia pe care în coloana 7 se află numele clasei, linia pe care figurează orele 1:7 și cele 5 linii care conțin lecțiile fiecărei zile); dar… nu este așa:
> nrow(Ocl) [1] 249
Trebuiau să fie $34\times7=238$ linii, nu $249$… Apar 11 linii în plus și este interesant de văzut, de ce.
După ce am obținut fișierul "orar-24.csv", am eliminat liniile „pe care erau specificate pentru fiecare clasă, intervalele orare "7:45 - 8.35" etc.” (citând de undeva mai sus); de fapt (și corect, la prima vedere), nu liniile am eliminat, ci doar textele de forma "7:45 - 8.35" — folosind comanda de substituire din Perl:
perl -p -i -e 's/\d{1,2}:\d{1,2} - \d{1,2}:\d{1,2}/""/g' orar-24.csv
Trebuia să fie corect așa, fiindcă pe liniile aferente primelor câteva clase am văzut că textele menționate "7:45 - 8.35" etc. nu formează un rând propriu-zis al fișierului Excel, ci sunt așezate fiecare în celulele care conțin numărul de ordine al orei zilei, dedesubtul acestuia:
,"1\n7:45 - 8:35",,,"2\n8:45 - 9:35", etc. (deci nu linia trebuie eliminată, ci doar textele de după 1, 2, etc., păstrând numărul orei)…
Nu ne-am putut închipui că totuși, la unele clase, intervalele orare au fost specificate pe câte o linie Excel de sine stătătoare:

Pentru aceste cazuri nu ajunge că am șters textele din celule, trebuia ștearsă și linia care le conține (și care acum conține fie, majoritar, "", fie constanta NA)…
Îndreptăm lucrurile, reținând din Ocl numai liniile care conțin măcar un câmp cu text propriu-zis (diferit de șirul vid ""):
Ocl <- Ocl %>% filter(if_any(everything(), ~ nchar(.x) > 0))
Salvăm Ocl în "orar-cl_0.RDS"; avem 238 linii, câte 7 pentru fiecare clasă.
Ajustări (partea întâia)
Secvența $(7(i-1)+1):(7i)$ indică liniile celei de-a $i$-a dintre cele 34 de clase. De exemplu, pentru ultima clasă (afișând numai coloanele V1 și V5 : V12):
> Ocl[232:238, c(1, 5:12)] V1 V5 V6 V7 V8 V9 V10 V11 V12 232 12E 233 2 3 4 234 Lu Filosofie Istorie Lb. Romana\nO 235 Ma LFr/LGer Geografie Optional Socio-umane 236 Mi Filosofie Lb. Engleza Lit. Universala\nO 237 Jo Lb. Romana\nO Optional Sport Sport 238 Vi Lb. Engleza Istorie Lb. Spaniola
Am evidențiat aici și ajustarea făcută mai sus pentru lecțiile "pe grupe" (precum "LFR/LGer"); vedem deasemenea, alte ajustări de făcut — precum "Lb. Romana" (sau mai bine, "Română") pentru "Lb. Romana\nO" (unde "O" dedesubt, o fi însemnând poate "Opțional", dar nu are de ce să ne intereseze).
Dar prima ajustare importantă de făcut, se referă la numele claselor; când inițial, a fost vorba numai de vizualizarea orarului clasei printr-un tabel Excel, s-a înscris numele clasei ca "titlu" al orarului clasei, undeva în mijlocul primei linii, colapsând toate celulele acesteia (în Ocl "titlul" respectiv a fost preluat în coloana V7).
Într-un set de date propriu-zis nu au ce căuta asemenea "linii-titlu"… Numele claselor sunt și ele, valori ale unei anumite variabile, să-i zicem "cls", și se cuvine ca aceasta să fie alipită celorlalte variabile (coloane) din setul Ocl.
Decupăm valorile din coloana V7 și reținem într-un vector cls pe cele nenule (numele claselor); în plus, înlocuim primul nume "Clasa 05A", cu "05A":
col7 <- Ocl$V7 Cls <- col7[col7 != ""] > Cls [1] "Clasa 05A" "05B" "05C" "06A" "06B" "06C" [7] "07A" "07B" "07C" "07D" "08A" "08B" ... [31] "12B" "12C" "12D" "12E" Cls[1] <- "05A"
Eliminăm "liniile-titlu" (reținând numai liniile care în coloana V7 au "") și adăugăm setului Ocl ca primă coloană, vectorul rezultat din vectorul Cls prin repetarea de câte 6 ori a fiecăreia dintre valorile sale:
Ocl <- Ocl %>% filter(V7 == "") %>% mutate(cls = rep(Cls, each = 6), .before = 1)
Acum orarul fiecărei clase conține câte 6 linii, iar numele clasei este explicitat în coloana cls — redundant într-adevăr (pe fiecare linie), dar acum putem găsi orarul clasei folosind filter() (în loc de a calcula numerele de linie):
> Ocl %>% filter(cls=="12E") %>% select(c(1:3, 6, 10)) cls V1 V2 V5 V9 1 12E 1 2 3 2 12E Lu Muz\nPopa Simona Filosofie Istorie 3 12E Ma Lb. Romana\nO LFr/LGer Geografie 4 12E Mi Lb. Romana\nO Filosofie Lb. Engleza 5 12E Jo Optional Romana\nO Lb. Romana\nO Optional Sport 6 12E Vi Fizica Lb. Engleza Istorie
O altă categorie importantă de ajustări vizează numărul de coloane; ar trebui să avem 9 coloane: cls, coloana zilelor și câte o coloană pentru cele 7 ore ale zilei. Avem însă 25 de coloane, urmare a transferării mot-à-mot din fișierul Excel inițial (în care se ajunsese la 24 de coloane din cauza ghidușiilor vizuale aplicate ad-hoc pe celule). Iată un exemplu semnificativ:

În loc de a înscrie într-o singură celulă "Tic\nInfo 1" (ca în cazurile relevate mai sus), când numele disciplinei trebuia (chipurile) acompaniată de vreo informație prețioasă — s-au comasat orizontal două sau trei celule scriind în prima "Info 1" și în a doua "TIC", mărind artificial numărul coloanelor:
> Ocl[161:162, 13:25]
V12 V13 V14 V15 V16 V17 V18 V19 V20 V21 V22 V23 V24
161 Lb. Romana NA LFr/LGer NA Biologie
162 Geografie NA Info 1 TIC NA Info 2 TIC
Numele disciplinei nu este "Info 1" și nici "Info 2" (numele unor săli de "Laborator", probabil), ci este "TIC" și acest termen trebuia înscris în coloanele Excel 'Q' și 'V' (adică pentru Ocl, coloanele V17 și V22).
Dacă listăm coloanele V19 și V24 (prin print(Ocl$V19)) — constatăm că acestea conțin câte un singur element nenul, anume "TIC", al 162-lea (de unde și comanda de listare a celor două linii de mai sus); înscriem "TIC" pe linia 162 în coloanele cu numele disciplinelor V17 și V22, apoi eliminăm coloanele absolut inutile V19 și V24:
> Ocl[162, c("V17", "V22")] <- "TIC" > Ocl$V19 <- NULL; Ocl$V24 <- NULL
Există vreo două coloane în care toate valorile sunt "" sau NA; le eliminăm indirect, selectând pe cele care conțin măcar o valoare nenulă:
> Ocl <- Ocl %>% select(where(~ any(. != "", na.rm=TRUE)))
Ne-au rămas 20 de coloane… Să investigăm pe rând, printre coloanele respective:
> which(Ocl$V10 != "") [1] 87 99 # singurele linii pe care V10 are valoare nenulă > which(Ocl$V13 != "") [1] 87 99 # pe aceleași linii (și numai pe ele), V13 are valoare nenulă > Ocl[c(86:87, 98:99), c("V9", "V10", "V12", "V13")] V9 V10 V12 V13 86 Lb. Romana LFr/LGer 87 Info 2 TIC Info 2 TIC 98 Matematica LFr/LGer 99 Info 1 TIC Info 1 TIC
Deci V10 și V13 sunt în aceeași situație ca mai sus pentru V19 și V24. Găsim la fel:
> Ocl[109:111, c("V14", "V16", "V18", "V20")] V14 V16 V18 V20 109 5 6 110 Info 1 TIC Info 1 TIC 111 Lb. Romana Optional Romana
Dar n-am terminat cu această situație (și… rămâne de apreciat consecvența cu care autorul Excel-ului notează în coloana disciplinelor numele sălii de clasă, înființând câte o nouă coloană, special pentru linia respectivă, pentru a înregistra totuși disciplina):
> Ocl[c(88:90, 94:96, 104:106), c("V2", "V3", "V4", "V6")] V2 V3 V4 V6 88 Matematica 89 Info 2 Informatica Aplicatii 90 Dirigentie 94 Lb. Engleza Fizica 95 Info 1 TIC Info 1 TIC 96 Logica Matematica 104 Matematica Muz/Des 105 Info 1 TIC Info 1 TIC 106 Lb. Engleza Lb. Romana
Desigur că, la fel ca în primul caz întâlnit mai sus (pentru linia 162, V19 și V24), înlocuim "Info 1" și "Info 2" prin "TIC", pe liniile bifate mai sus:
Ocl[c(87, 99), c("V9", "V12")] <- "TIC" Ocl[110, c("V14", "V18")] <- "TIC" Ocl[c(95, 105), c("V2", "V4")] <- "TIC" Ocl[89, "V2"] <- Ocl[89, "V3"] # Nu scriem așa ceva: "Informatica Aplicatii"...
Eliminăm în sfârșit, coloanele inutile și salvăm setul de date rămas:
Ocl <- Ocl %>% select(-c("V3", "V6", "V10", "V13", "V16", "V20")) saveRDS(Ocl, "orar-cl_1.RDS")
Deocamdată, în Ocl avem 204 linii (câte 6 pe fiecare clasă), pe 14 coloane…
Ajustări (partea a doua)
Avem 6 linii de fiecare clasă (și nu 5, cât ar trebui în mod normal), din cauza faptului că inițial, în Excel, clasele au fost văzute ca fiind izolate între ele — încât s-a înființat pentru fiecare clasă câte un rând în celulele căruia (cu diverse grupări orizontale) s-au înscris numerele de ordine ale orelor (1..6 sau 1..7, după caz).
De exemplu, la unele clase lecțiile din ora 2 apar în coloana V5. iar la alte clase apar în coloana V4 (analog, pentru ora 3, ora 4, etc.):
> Ocl %>% filter(cls=="09A") %>% select(c("cls","V4", "V5")) cls V4 V5 1 09A 2 2 09A Chimie 3 09A Religie 4 09A Lb. Romana 5 09A Complemente de Programare\nInfo 2 6 09A Matematica > Ocl %>% filter(cls=="07A") %>% select(c("cls","V4", "V5")) cls V4 V5 1 07A 2 2 07A Matematica 3 07A Lb. Romana 4 07A Tehnologie 5 07A Muzica 6 07A Lb. Engleza
În orarul clasei 09A, coloana V4 este vidă, iar în cel al clasei 07A coloana V5 este vidă; astfel se explică faptul că în Ocl au rezultat 14 coloane, în loc de 9.
Pentru a îndrepta lucrurile, considerăm întâi o funcție care pentru clasa indicată, extrage din Ocl subsetul (cu 6 linii) corespunzător acelei clase, reține doar coloanele nevide ale acestuia, elimină prima linie (care înregistra numerele de ordine ale orelor) și instituie drept nume ale coloanelor pe cele uzuale ("cls", "zl" și rangurile orelor):
adjust_cls <- function(Q) { orr <- Ocl %>% filter(cls == Q) %>% select(where(~ any(. != "", na.rm=TRUE))) orr <- orr[2:6, ] names(orr) <- c("cls", "zl", 1:(ncol(orr)-2)) orr # orarul ajustat la 5 linii și (după caz) 8 sau 9 coloane }
Iterăm adjust_cls() pe toate clasele și îmbinăm rezultatele:
Cls <- Ocl$cls %>% unique() # vectorul claselor ORR <- map_dfr(Cls, adjust_cls)
Cu aceasta, am terminat de făcut ajustările importante:
> str(ORR) 'data.frame': 170 obs. of 9 variables: $ cls: chr "05A" "05A" "05A" "05A" ... $ zl : chr "Lu" "Ma" "Mi" "Jo" ... $ 1 : chr "Matematica" "Tehnologie" "Sport" "Lb. Germana" ... $ 2 : chr "Biologie" "Matematica" "Lb. Romana" "Lb. Romana" ... $ 3 : chr "Lb. Romana" "Lb. Engleza" "Lb. Engleza" "Matematica" ... $ 4 : chr "Educatie Sociala" "Lb. Engleza" "Matematica" "Lb. Engleza" ... $ 5 : chr "Sport" "Istorie" "Lb. Germana" "Istorie" ... $ 6 : chr "Dirigentie" "" "" "Geografie" ... $ 7 : chr NA NA NA NA ...
Acum avem câte 5 linii de fiecare clasă ($5\times34=170$ linii), pe 9 coloane (clasele cu 6 ore/zi au în coloana '7' numai valori NA sau ""). Salvăm ORR în "orar-cl_2.RDS".
Setul tuturor lecțiilor
'1'..'7' au devenit nume de coloană ale setului ORR, dar de fapt sunt valori ale unei variabile "ora"; numele disciplinelor sunt răspândite în cele 7 coloane orare, dar de fapt sunt valori ale unei variabile "obj". Cam 10% dintre cele 170×9=1530 valori, sunt valori inutile fiind "", sau NA (ele apar pe ultimele coloane orare, la clasele care au numai 5, sau numai 6 ore, într-o zi sau alta):
> colSums(is.na(ORR) | ORR == "") cls zl 1 2 3 4 5 6 7 0 0 0 0 0 0 0 17 147 # 164 înregistrări inutile (pe ultimele ore)
Rezultă că în ORR avem în total (170×7_ore/zi = 1190 ore, minus 164 "inutile") = 1026 lecții propriu-zise, cls|zl|ora|obj.
Reorganizăm ORR ca set al tuturor acestor 1026 lecții:
ORR <- ORR %>% pivot_longer( cols = 3:9, names_to = "ora", values_to = "obj", values_drop_na = TRUE ) %>% filter(obj != "") > str(ORR) tibble [1,026 × 4] (S3: tbl_df/tbl/data.frame) $ cls: chr [1:1026] "05A" "05A" "05A" "05A" ... $ zl : chr [1:1026] "Lu" "Lu" "Lu" "Lu" ... $ ora: chr [1:1026] "1" "2" "3" "4" ... $ obj: chr [1:1026] "Matematica" "Biologie" "Lb. Romana" "Educatie Sociala" ...
pivot_longer() a preluat numele coloanelor 3:9 într-o nouă variabilă ora, iar valorile existente în coloanele 3:9 (dar diferite de NA) într-o nouă variabilă "obj"; am reținut apoi numai valorile diferite de "", rezultând cele 1026 lecții cls|zl|ora|obj.
Avantajul acestui "format lung" constă în faptul că permite o exploatare (investigare, prelucrare) unitară a datelor respective; liniile de date au un același format, pe variabile independente și avem de folosit filter(), pentru a filtra datele după vreun criteriu de restricționare a valorilor variabilelor; prin mutate() putem modifica valorile dintr-o coloană, sau putem adăuga alte variabile; prin group_by() putem grupa liniile de date, după un criteriu sau altul și putem apoi lucra pe fiecare grup în parte; prin split() putem despărți în subseturi; prin arrange() putem ordona liniile de date (iar dacă este cazul, putem înlănțui operațiile folosind operatorul "%>%").
Salvăm ORR în "orar-cl_3.RDS".
Specificarea disciplinelor
vezi Cărţile mele (de programare)