Orar pe o școală fără profesori (II)
Ajustări ad-hoc
Încărcăm setul tuturor lecțiilor cls|zl|ora|obj (fără profesori) la care am ajuns în [1] și listăm disciplinele:
rm(list=ls()) library(tidyverse) ORR <- readRDS("orar-cl_3.RDS") # v. [1] ORR$obj %>% unique() %>% sort() %>% print() [1] "Biologie" "Chimie" [3] "Complemente de Programare\nInfo 2" "Desen" [5] "Dirigentie" "Dirigentie\nO" [7] "Economie" "Ed. Antreprenori ala" [9] "Ed. Antreprenorial a" "Educatie Sociala" [11] "Filosofie" "Fizica" [13] "Geografie" "Informatica Aplicatii" [15] "Informatica Aplicatii\nInfo 1" "Informatica Aplicatii\nInfo 2" [17] "Informatica Curs" "Informatica si TIC\nInfo 1" [19] "Informatica si TIC\nInfo 2" "Istoria Holocaustului" [21] "Istorie" "Latina" [23] "Lb. Engleza" "Lb. Franceza" [25] "Lb. Germana" "Lb. Romana" [27] "Lb. Romana\nO" "Lb. Spaniola" [29] "LFr/LGer" "Lit. Universala" [31] "Lit. Universala\nO" "Logica" [33] "Matematica" "Muz\nPopa Simona" [35] "Muz/Des" "Muzica" [37] "OF/LGer" "Optional Biologie" [39] "Optional Chimie" "Optional Latina" [41] "Optional Matematica" "Optional Romana" [43] "Optional Romana\nO" "Optional Socio-umane" [45] "Optional Sport" "Psihologie" [47] "Religie" "Sanitarii priceputi" [49] "Sociologie" "Sport" [51] "Tehnologie" "TIC" [53] "TIC\nInfo 1" "TIC\nInfo 2"
Vom avea de făcut multe „reparații” (că doar n-o să lăsăm "Ed. Antreprenori ala", nici "Ed. Antreprenorial a", etc.)… ((tot am zis să nu ne mai aiurim cu tabelele Excel…))
Dar înainte, ne sare în ochi "Muz\nPopa Simona" și avem de văzut dacă nu cumva am greșit anterior, când am simplificat notația lecțiilor "pe grupe":
> ORR %>% filter(obj == "Muz\nPopa Simona") cls zl ora obj 1 12E Lu 1 "Muz\nPopa Simona" # un singur caz, la clasa 12E
Ne uităm în fișierul PDF inițial, pe pagina clasei 12E:

Rădăcina răului este mereu (a vedea și situațiile întâmpinate în [1]) inconsecvența formulării fișierului original (în Excel, sau PDF): un același termen apare într-un fel într-un loc și în alt fel într-un alt loc.
Peste tot, lecțiile "pe grupe" apar însemnate sub "GR1" și respectiv "GR2" — cu excepția care ne-a scăpat, evidențiată mai sus; noi căutasem liniile care conțin în vreo coloană "GR1", am alipit conținutul de sub "GR1" cu cel aflat dedesubt sub "GR2" și apoi am șters liniile care conțineau "GR2" (v. [1]).
Dar iată că la 12E, "Muz\nPopa Simona" nu este sub "GR1"; iar "Des\n..." a fost șters, fiind pe aceeași linie Excel cu "LGer" (aflat sub "GR2").
Îndreptăm ad-hoc lucrurile (amintindu-ne și de versiunile de "Ed. Antrepre..." și observând deasemenea, pe cele de "TIC"):
> ORR$obj[grepl("Muz\n", ORR$obj)] <- "Muz/Des" > ORR$obj[grepl("Ed. Antrepr", ORR$obj)] <- "Ed. Antreprenorială" > ORR$obj[grepl("TIC", ORR$obj)] <- "TIC"
Deasemenea, observând că "OF/" apare pe o singură linie de date, înlocuim "OF/LGer" cu "LFr/LGer"; înlocuim toți termenii care încep cu "Informatica", cu "Informatică". Înlocuim toți termenii care conțin "Romana" (inclusiv, "Optional Lb. Romana") prin Română; analog, pentru ceilalți termeni care conțin "Optional". Înlocuim "Lb. Engleza" cu "Engleză" ș.a.m.d. În final, deocamdată salvăm ORR înapoi în "orar-cl_3.RDS".
Specificarea disciplinelor; codificări
După ajustările convenite mai sus, vectorul Obj al denumirilor unice ale disciplinelor din ORR$obj, conține aceste 34 de valori:
[1] "Biologie" "Chimie" "Desen" [4] "Dirigentie" "Economie" "Ed. Antreprenorială" [7] "Educatie Sociala" "Engleză" "Filosofie" [10] "Fizică" "Franceză" "Geografie" [13] "Germană" "Informatică" "Istoria Holocaustului" [16] "Istorie" "Latină" "LFr/LGer" [19] "Lit-univ" "Logică" "Matematică" [22] "Muz/Des" "Muzică" "Programare" [25] "Psihologie" "Religie" "Română" [28] "Sanitarii" "Soc-uman" "Sociologie" [31] "Spaniolă" "Sport" "Tehnologie" [34] "TIC"
De fapt, denumirile în care apare '/' (de exemplu "Muz/Des") nu corespund unei discipline propriu-zise, ci indică faptul că lecția cls|zl|ora|obj respectivă se desfășoară "pe grupe". Să simplificăm disciplinele propriu-zise la câte două caractere, apelând întâi la funcția abbreviate() și apoi editând convenabil, rezultatele:
ORR <- readRDS("orar-cl_3.RDS") Obj <- ORR$obj %>% unique() %>% sort() Dsp <- Obj[! grepl("/", Obj)] # disciplinele propriu-zise abb <- abbreviate(Dsp, minlength = 2, strict = TRUE) Dab <- cbind(Dsp, unname(abb)) %>% as.data.frame() %>% edit() # deschide un editor de text, permițând modificări manuale names(Dab) <- c("discip", "cod") saveRDS(Dab, "objabb.RDS") discip cod discip cod 1 Biologie Bi 17 Latină La 2 Chimie Ch 18 Lit-univ LU 3 Desen Ds 19 Logică Lg 4 Dirigentie Di 20 Matematică Mt 5 Economie Ec 21 Muzică Mz 6 Ed. Antreprenorială EA 22 Programare Pg 7 Educatie Sociala ES 23 Psihologie Ph 8 Engleză En 24 Religie Rg 9 Filosofie Ff 25 Română Ro 10 Fizică Fi 26 Sanitarii Sa 11 Franceză Fr 27 Soc-uman SU 12 Geografie Gg 28 Sociologie Sg 13 Germană Gr 29 Spaniolă Sp 14 Informatică In 30 Sport SP 15 Istoria Holocaustului IH 31 Tehnologie Th 16 Istorie Is 32 TIC TI
Am preferat formatul tabelar fiindcă a fost mai convenabil pentru editare; dar în vederea înlocuirii prin abrevieri a tuturor valorilor din ORR$obj, va fi mai convenabil un simplu dicționar (valori cu nume):
fct <- Dab$cod %>% setNames(Dab$discip)
Dar în ORR$obj avem și notații pentru lecțiile "pe grupe" — să definim și pentru acestea, câte un cod (distinct de cele existente):
fct["Muz/Des"] <- "MD" fct["LFr/LGer"] <- "FG"
Factorizând ORR$obj — ceea ce înseamnă că denumirile existente se înlocuiesc cu indecșii acestora în vectorul de 34 denumiri unice — și modificând conform fct vectorul levels() asociat astfel, vom avea peste tot codurile de câte două caractere, în locul denumirilor inițiale:
ORR <- ORR %>% mutate(obj = factor(obj)) lev <- levels(ORR$obj) # cele 34 denumiri unice levels(Orr$obj) <- fct[lev]
Înainte de a salva ORR, să transformăm și zl în factor, pentru a avea zilele (când listăm linii de date) în ordinea obișnuită (și nu începând alfabetic, cu "Jo"):
Zile <- c("Lu", "Ma", "Mi", "Jo", "Vi") ORR <- ORR %>% mutate(zl = factor(zl, levels = Zile, ordered=TRUE)) saveRDS(ORR, "orar-cl_4.RDS")
Redăm un eșantion aleatoriu din setul ORR curent:
> slice_sample(ORR, n=4) # A tibble: 4 × 4 cls zl ora obj <chr> <ord> <chr> <fct> 1 08A Lu 2 Mt # Mt este fct("Matematică") 2 12B Lu 4 Ch 3 11A Mi 5 In 4 08D Mi 2 Mt
Inversând dicționarul fct (sau folosind "objabb.RDS"), vom putea reveni oricând ar fi cazul, la denumirile inițiale de discipline.
Inventarea profesorilor (partea întâia)
Vrem să „inventăm” profesorii, dar respectând alocarea cls|zl|ora|obj din ORR (unde nu avem și datele prof originale); de exemplu, dacă pentru două clase găsim în ORR pe un același zl|ora, aceeași disciplină obj — atunci trebuie inventați doi profesori (nu ajunge unul singur: ar intra simultan la două clase), cărora să le alocăm câte una dintre clase.
Preferăm să lucrăm în zona globală, pentru a beneficia direct de variabilele care intervin (în loc de cum s-ar cuveni, să definim o funcție care primind disciplina, să externalizeze numai lista finală pe care o găsește); mai precis, cerem ca variabila care definește "disciplina" să fie introdusă înainte de a încărca programul care o va folosi:
> rm(list = ls()) # elimină variabilele moștenite din sesiunea precedentă > Discip <- "Fi" # <- "Bi" # <- c("Ro", "LU", "La") > source("enframe.R") # încadrează clasele, profesorilor disciplinei date
Demarăm programul care va propune o listă de încadrări, astfel:
# enframe.R library(tidyverse) library(igraph) ORR <- readRDS("orar-cl_4.RDS") ZH <- ORR %>% filter(obj %in% Discip) %>% select(cls, zl, ora) %>% as.data.frame()
Având nevoie de anumite elemente de teoria grafurilor, am inclus pachetul igraph.
În definiția variabilei ZH am folosit "obj %in%" Discip" (și nu "== Discip"), pentru a permite ca Discip să fie eventual, un grup de discipline; de exemplu, când ar fi vorba de "Ro" am folosi "Discip <- c('Ro', 'LU', 'La')", ținând seama că pe Lit-univ și Latină sunt puține ore, iar acestea cad de obicei în seama celor de pe Română.
Următoarea funcție stabilește dacă două clase sunt adiacente, comparând valorile zl|ora de pe toate liniile asociate în ZH celor două clase; dacă există două linii pe aceeași zi și oră, atunci clasele respective trebuie repartizate la profesori diferiți — altfel, ele pot fi date unui aceluiași profesor:
could_same <- function(q1, q2) { or1 <- ZH %>% filter(cls == q1) or2 <- ZH %>% filter(cls == q2) for(i in 1:nrow(or1)) for(j in 1:nrow(or2)) if(or1[i,2] == or2[j,2] & or1[i,3] == or2[j,3]) return(FALSE) # q1, q2 NU pot sta la același profesor return(TRUE) # q1, q2 pot fi alocate unui aceluiași profesor }
Considerăm graful G al claselor la care se face disciplina respectivă, două clase fiind adiacente dacă ele nu pot sta la un același profesor:
CLS <- ZH$cls %>% unique() nrv <- length(CLS) ADJ <- matrix(rep(0L, nrv*nrv), nrow = nrv, byrow=TRUE, dimnames = list(CLS, CLS)) # matricea de adiacență for(i in 1:(nrv-1)) for(j in (i+1):nrv) ADJ[i,j] <- ADJ[j,i] <- ! could_same(CLS[i], CLS[j]) G <- graph_from_adjacency_matrix(ADJ, mode="undirected")
Clasele atribuite unui profesor trebuie să fie dintre cele neadiacente între ele, în graful G; prin urmare, orice încadrare vp pe clase a profesorilor corespunde unei colorări pe vârfuri a acestui graf:
gvc <- greedy_vertex_coloring(G) vp <- map(1:max(gvc), function(i) names(gvc[gvc == i])) %>% setNames(paste0(Discip, 1:max(gvc))) > vp # profesori încadrați pe "Fi" $Fi1 "06B" "06C" "07B" "07C" "09A" "10A" "11B" "12A" "12C" $Fi2 "07A" "07D" "08B" "08D" "09D" "09E" "12B" "12D" $Fi3 "06A" "09B" "10C" "10D" "11A" "11D" "12E" $Fi4 "08A" "08C" "10B" "10E" "11C" $Fi5 "09C"
În cazul de față, pentru disciplina "Fi", colorarea pe vârfuri returnată de greedy_vertex_coloring() este optimală (cu număr minim de culori), fiindcă subgrafurile complete ale lui G (mai numite "clici") au maximum 5 vârfuri:
> clique_num(G) # mărimea maximă a clicilor [1] 5 > max_cliques(G, min=5, max=5) # listează clicile maxime [1] 10E 07B 12B 11D 09C # există o singură clică de 5 noduri
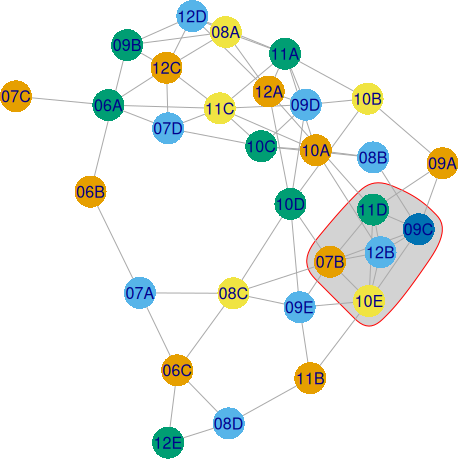
Oricare două clase dintre cele 5 evidențiate mai sus (inclusiv, pe desen) au în comun măcar câte un cuplu zl|ora (determinând un subgraf complet al lui G), încât ele trebuie atribuite câte una la 5 profesori (nu mai puțini).
Dar pe "Fi" avem nrow(ZH)=75 de lecții, însemnând 4 norme întregi (de 18 ore) și o completare de 3 ore — adică 4 dintre cei 5 profesori ar trebui să aibă cam câte 18 ore, iar al 5-lea va rămâne cu foarte puține ore (completând până la normă, orele pe care ar fi încadrat într-o altă școală):
> frh <- table(ZH$cls) # câte lecții de 'Fi' are fiecare clasă > sapply(vp, function(P) sum(frh[P])) # distribuția orelor pe cei 5 profesori Fi1 Fi2 Fi3 Fi4 Fi5 23 19 18 12 3
O clasă ar putea fi mutată la un alt profesor (pentru a echilibra încadrările), dacă ea nu este adiacentă în G cu vreuna dintre clasele acestuia; următoarea funcție furnizează clasele din încadrarea unui profesor care ar putea fi mutate la alt profesor:
could_move <- function(i, j) { qls <- vector() for(q in vp[[i]]) if(all(sapply(vp[[j]], could_same, q))) qls <- c(qls, q) qls # clasele care pot fi mutate de la vp[[i]] la vp[[j]] }
Pentru încadrările pe "Fi", rezultate mai sus în vp, avem:
> could_move(2, 4) # 08B 08D (2×2 ore, de la Fi2 la Fi4) > could_move(1, 4) # 06B 07C (1×2 ore, de la Fi1 la Fi4) > could_move(1, 2) # 07C 09A (1×3 ore, de la Fi1 la Fi2)
Efectuând mutările indicate prin boldare mai sus, avem:
vp$Fi1 <- vp$Fi1[! vp$Fi1 %in% c("06B", "09A")] %>% sort() vp$Fi2 <- c(vp$Fi2[! vp$Fi2 %in% c("08B", "08D")], "09A") %>% sort() vp$Fi4 <- c(vp$Fi4, "08B", "08D", "06B") %>% sort() > vp # încadrarea finală (echilibrată) pe "Fi" $Fi1 "06C" "07B" "07C" "10A" "11B" "12A" "12C" $Fi2 "07A" "07D" "09A" "09D" "09E" "12B" "12D" $Fi3 "06A" "09B" "10C" "10D" "11A" "11D" "12E" $Fi4 "06B" "08A" "08B" "08C" "08D" "10B" "10E" "11C" $Fi5 "09C" > sapply(vp, function(P) sum(frh[P])) Fi1 Fi2 Fi3 Fi4 Fi5 18 18 18 18 3
Următoarea funcție furnizează profesorul pe Discip al clasei indicate (sau NULL, dacă în ORR acea clasă nu are disciplina respectivă):
prof_to <- function(q) { for(i in 1:length(vp)) if(q %in% vp[[i]]) return(names(vp)[i]) }
Acum, în sfârșit, putem înscrie profesorii propuși în vp, pe lecțiile din ORR la clasele care le-au fost repartizate pentru disciplina respectivă:
ORR <- ORR %>% rowwise() %>% mutate(prof = ifelse(obj %in% Discip, prof_to(cls), "")) %>% ungroup() > table(ORR$prof) # verificare Fi1 Fi2 Fi3 Fi4 Fi5 951 18 18 18 18 3 saveRDS(ORR, "orar-cl_5.RDS")
Am folosim rowwise() pentru a acționa pe fiecare linie de date în parte (în loc de, cum este obișnuit, pe o întreagă coloană), fiindcă prof_to() este o funcție "scalară" (acționează pe o singură clasă, nu pe un vector de clase).
În "orar-cl_5.RDS" ne-au rămas 951 de lecții, pe diverse discipline (altele decât Fi), cărora trebuie să le asociem niște profesori — repetând programul "enframe.R", împreună eventual, cu demersurile de echilibrare a încadrărilor produse de acesta.
vezi Cărţile mele (de programare)