Recunoașterea textului și extragerea datelor unui orar școlar prezentat în format PDF (III)
[1] v. partea a II-a (…și I)
Redenumirea fișierelor, după clasă
În subdirectorul curent avem din [1], 27 de fișiere "CNS-01.png", ..., "CNS-27.png", indexate începând cu cele 5 clase a 9-a ("9ABDEF"), continuând de la "-06" cu cele câte 6 clase a 10-a, a 11-a și a 12-a și încheind de la indexul "-24" cu clasele 5..8. Următorul program Bash redenumește fișierele respective după clasa al cărei orar este conținut:
#!/bin/bash clase=( 9{A,B,D,E,F} {10..12}{A..F} {5..8}A ) # cele 27 de clase i=0 for file in `ls CNS-*` ; do # numele inițiale: CNS-01.png .. CNS-27.png mv $file ${clase[i]}.png let i=i+1 done # noile nume: 5A.png, 6A.png, ..., 10A.png, 10B.png, ..., 12E.png, 12F.png
Precizăm că "=(...)" definește un array iar "${clase[i]}" selectează al i-lea element din tabloul respectiv; "{5..8}A" va fi expandat la "5A 6A 7A 8A".
Decupări…
Inspectând prin "Image Viewer"-ul obișnuit, constatăm că imaginile respective au lățimea $3508px$ și înălțimea $1808px$:
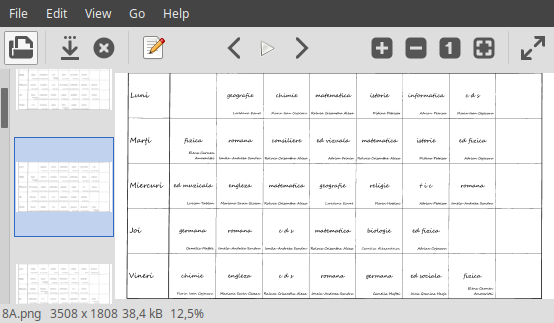
identify (cu opțiunea --verbose) ne arată că aceste imagini au "Resolution: 118.11x118.11" (pentru "Units: PixelsPerCentimeter") — confirmând setarea "-r 300" din comanda pdftocairo prin care au fost extrase (v. [1]) din fișierul inițial "CNS.pdf" (într-adevăr, avem: $118.11px/cm\times 2.54cm/in\approx 300dpi$ ("dots per inch")).
Acum… avem de muncit, cam după următorul plan. Maximizăm fereastra "Image Viewer" și mărim $100\%$ imaginea redată; urmează să folosim un instrument Screenshot, pentru a decupa din imaginea respectivă zone pe care este reprezentată câte o literă, sau eventual câte o secvență de litere „legate” una de alta.
Constituim întâi un subdirector "svt-ground-truth/", în care vom salva imaginile decupate (numit astfel după indicațiile din documentația Tesseract; ne-am asigurat totuși că "svt" nu apare între limbile afișate de tesseract --list-langs).
Vom denumi imaginile fie prin numele glifei reprezentate pe zona decupată (de exemplu, "a.png"), fie indexând de la "1.png" pentru zone care conțin câte o secvență de litere (sau care conțin câte o literă „cu accent”, precum "ț" sau "ă"); astfel, ne va fi mai ușor să alăturăm fișierelor salvate, fișierele ".gt.txt" care vor servi pentru recunoașterea imaginilor respective (de exemplu, în "a.gt.txt" vom putea înscrie automat, "a"; însă în "1.gt.txt" vom avea de înscris manual, secvența de litere sau litera cu accent, reprezentată în "1.png").
Din nefericire, pe imaginile respective avem totuși trei mărimi de caracter: una pentru numele zilelor, una ceva mai mică pentru numele disciplinelor și una mult mai mică (de fapt, prea mică) pentru numele profesorilor; pentru a mări șansele de recunoaștere corectă, ar trebui probabil să decupăm pentru câte o aceeași literă, două glife: una aferentă acelei litere, din liniile cu discipline sau din liniile cu zile (având mărimi apropiate) și una din liniile cu numele profesorilor.
Din păcate… abia acum vedem că puteam elimina (pe lângă antetele, subsolurile și capetele de tabel din fișierele inițiale; v.[1]) și coloana zilelor; într-adevăr, putem „recunoaște” zilele și fără a vedea numele acestora — știind doar faptul că datele zilelor apar în principiu (cu câteva excepții, de care n-ar fi greu să ținem seama) pe câte două linii: cea pentru discipline și dedesubtul acesteia, cea pentru profesori.
Prin urmare, înainte de a ne apuca de „decupări” prin Screenshot, conform planului schițat mai sus — s-ar cuveni să ne gândim la un alt soi de „decupare”…
Imaginea paginii, sau imaginea orarului clasei?
Prin scanare s-a obținut imaginea paginii care a fost introdusă în scanner — dar ne interesează de fapt, imaginea orarului reprezentat pe acea pagină (nu și marginile acesteia, exterioare zonei orarului); mai mult, (cum tocmai am observat ceva mai sus) n-are de ce să ne intereseze prima coloană — cea pe care sunt notate zilele de lucru.
Pentru a putea elimina coloana zilelor… avem nevoie de coordonatele zonei din imagine pe care figurează coloana respectivă; pentru vizualizarea coordonatelor putem folosi interfața grafică oferită, prin comanda display, de către ImageMagick:
display 8A.png # click în interior, pentru meniul "Commands"
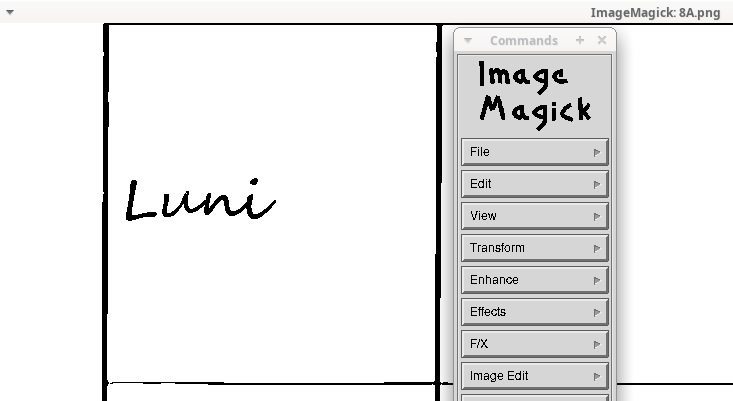
Din meniul de comenzi oferit punctăm "Image Edit / Region of Interest..."; ca urmare, într-o casetă "ROI" poziționată stânga-sus, sunt indicate coordonatele punctului curent indicat de mouse. Când punctăm cu mouse-ul colțul dreapta-sus al celulei în care este scris "Luni", în caseta ROI apare "+436+0" — adică acel punct este distanțat cu $436px$ față de marginea stângă a imaginii (marcată cu albastru, pe imaginea redată mai sus); iar când purtăm mouse-ul în colțul dreapta-sus al ultimei celule din primul rând de celule — ROI indică "+3412+0". Zona din imaginea inițială care ne interesează conține punctele cu abscisele cuprinse între 436 și 3412 (de pe toată înălțimea imaginii) — deci are lățimea de $3412-436=2976px$; pentru a exclude din imaginea inițială, zonele din afara zonei noastre de interes — putem folosi parametrul "-crop" sub una dintre comenzile convert (pentru un singur fișier) sau mogrify (care poate opera pe toate fișierele din directorul curent):
mkdir Crop mogrify -crop 2976x1808+436+0 -path ./Crop *.png
Fără parametrul "-path", mogrify ar fi transformat pe loc imaginile respective; pentru orice eventualitate, am păstrat fișierele inițiale — constituind subdirectorul Crop/ și indicându-l ca destinație pentru fișierele rezultate după decuparea efectuată prin "-crop".
Fișierele rezultate, Crop/*.png păstrează numele fișierelor inițiale și nu mai conțin coloana numelor de zile și nici zonele albe corespunzătoare marginilor laterale de pagină:
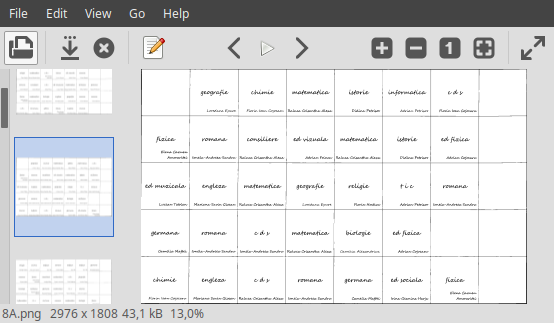
Toate cele 27 de fișiere rezultate au geometria 2976x1808 și păstrează celelalte proprietăți ale fișierelor inițiale (de exemplu, rezoluția $300dpi$) — dar contrar intuiției, au dimensiunea ceva mai mare (de exemplu "8A.png" avea $38.4kB$, dar acum măsoară $43.1kB$); aceasta, fiindcă sunt încorporate și informații asupra imaginii inițiale (de exemplu, "Page geometry: 3508x1808" și "Origin geometry: +436+0") — în ideea de a permite ulterior anumite operații de secvențiere a imaginilor. Dacă respectam recomandarea de a indica după "-crop" și "+repage", atunci am fi avut "Page geometry: 2976x1808" (acoperind exact imaginea decupată din cea inițială).
Dar oare nu puteam elimina și ultima coloană? Pe orarul "8A.png" redat mai sus, celulele acesteia sunt goale — deci nu poate fi decât bine, dacă eliminăm coloana respectivă…
Această ultimă coloană corespunde orei a 8-a din orarul zilei; dar în mod normal, orarul unei zile conține cel mult 7 ore. Inspectând fișierele PNG respective, constatăm că există o singură clasă care ajunge la 8 ore/zi (ba chiar, în două zile… Dar despre defectele orarului vom discuta mult mai încolo):
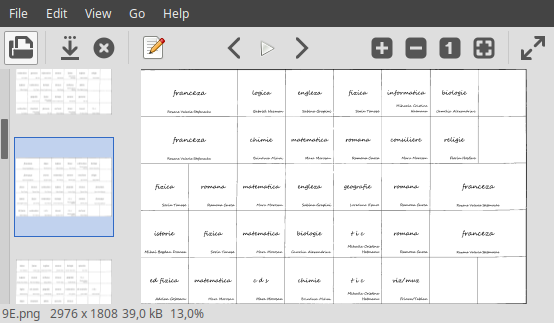
Pentru colțul dreapta-sus al celei de-a 7 coloane, "ROI" ne arată "+3044+0" (deci lățimea zonei de interes este acum $3044-436=2608$); eliminăm "9E.png" din directorul curent și reluăm comanda mogrify, pentru fișierele rămase:
mogrify -crop 2608x1808+436+0 +repage -path ./Crop *.png
Exceptând "9E.png" — pe care-l aveam în Crop/, cu 8 coloane — toate celelalte fișiere au fost rescrise și acum au câte 7 coloane:
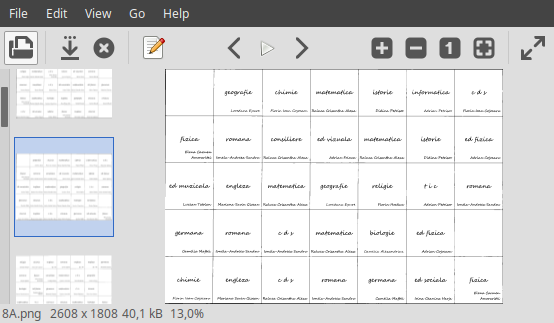
Păstrând din fișierele-imagine inițiale, numai ceea ce este necesar pentru deducerea datelor orarului — ne așteptăm ca operațiile de recunoaștere a textului să decurgă ceva mai rapid. Însă deocamdată, „câștigul” cert al experimentelor redate mai sus costă în descoperirea faptului că în loc să necăjim (cum anticipam inițial) cu instrumentul standard "Screenshot" (sau "Take a screenshot"), vom putea folosi programul interactiv display: prin "ROI" și meniul "Transform" vom putea decupa (foarte precis, moștenind rezoluția etc.) și salva una după alta (în svt-ground-truth/) diverse zone de interes de pe imaginea curentă.
vezi Cărţile mele (de programare)