Explorarea şi analiza datelor (partea I)
România apare înscrisă la OGP, aderând la principiile Open-source Governance (sigur inspirate de la mişcarea Open-sourse software); portalul oficial data.gov.ro transparentizează într-o anumită măsură datele proprii administraţiei publice şi guvernării (a compara totuşi, de exemplu cu gov.uk).
Intenţia de transparenţă este probată întâi de modul în care se pot extrage datele; dacă nu pot face altceva decât să descarc, să tipăresc şi doar să mă uit la datele pozate respective, atunci este vorba numai de falsă transparenţă - dar acesta şi este cazul obişnuit la noi: site-urile instituţiilor publice oferă "*.DOC" (documente Microsoft Word Document), sau PDF, sau SWF (cadre Adobe Flash) şi JPG, iar programele şcolare de la noi chiar nu au legături cu "Open-", fiind subjugate produselor comerciale Microsoft şi educaţiei funcţionăreşti asociate, "point-and-click".
data.gov.ro inspiră încredere, din acest prim punct de vedere; datele sunt emise în format machine-readable, încât şi utilizatorul poate să le investigheze (cu propriile instrumente) şi le poate eventual restructura şi integra în vreun context propriu.
Pentru diverse experimente sau exerciţii de explorare şi de analiză a datelor, ne-a interesat un set de date suficient de voluminos şi care să nu înglobeze adăugiri statistice semnificative asupra datelor propriu-zise; am evitat datele de natură financiară de la data.gov.ro, tocmai constatând că acestea sunt deja "gata de raportare" în vreo adunare de bilanţ trimestrial (sau lunar).
Vom folosi aici setul de date EVNAT-2015.csv, reprezentând rezultatele "Evaluării Naţionale". Am ales până la urmă acest set de date, fiindcă înregistrează suficient de multe observaţii individuale (linii de date), iar pe de altă parte - nu conţine decât datele brute respective (putem ignora că s-a intervenit asupra acestora pentru "anonimizare" şi probabil, pentru calculul câmpurilor de "notă finală" şi "medie"); în plus, acoperă o bună parte dintre greşelile tipice şi formatele defectuoase cu care ne-au obişnuit instituţiile noastre.
Corijări de format, folosind Sed şi Perl
Creem întâi un director de lucru /Evna şi ne facem aici o copie evna.csv a setului de date menţionat mai sus. Inspectând cu un editor de text (de exemplu gedit, preinstalat de obicei de către distribuţiile de Linux), găsim de schimbat (din start, cel puţin pentru gustul nostru) câteva caracteristici; redăm antetul fişierului (pe mai multe rânduri aici, pentru lizibilitate) şi prima linie de date:
COD UNIC CANDIDAT;SEX;DATA NASTERE;MEDIU;COD SIIIR; STATUS ROMANA; STATUS LIMBA MATERNA; STATUS MATEMATICA; NOTA ROMANA; NOTA LIMBA MATERNA; NOTA MATEMATICA; CONTESTATIE ROMANA; NOTA CONTESTATIE ROMANA; CONTESTATIE LIMBA MATERNA; NOTA CONTESTATIE LB MATERNA; CONTESTATIE MATEMATICA; NOTA CONTESTATIE MATEMATICA; NOTA FINALA ROMANA; NOTA FINALA LB MATERNA; NOTA FINALA MATEMATICA; MEDIA 11096387;F;11.03.2001;URBAN;4061103713;Prezent;;Prezent;1,75;;4;NU;;NU;;NU;;1,75;;4;2,87
Folosim sed pentru a restabili anumite standarde, plecând de la cerinţa CSV de a separa câmpurile prin virgulă; în plus - cu perl - rescriem data naşterii în format an-lună-zi:
sed -i -e 's/\./-/g' evna.csv # data 11.03.2001 devine 11-03-2001
sed -i -e 's/\,/\./g' evna.csv # nota 1,75 devine 1.75
sed -i -e 's/\;/\,/g' evna.csv # separatorul de câmpuri ; devine ,
perl -pi -e 's/(\d\d)-(\d\d)-(\d{4})/\3-\2-\1/g' evna.csv # 11-03-2001 devine 2001-03-11
Mai observând fişierul nostru şi la nivel hexazecimal (folosind de exemplu, programul xxd), constatăm încheierea rândurilor în maniera specifică DOS-ului (prin octeţii 0x0D, 0x0A); cu programul fromdos rezumăm caracterul '\n' la octetul 0x0A ("end-of-line" în Linux).
Mai schimbăm câte ceva şi în ceea ce priveşte denumirile variabilelor: eliminăm caracteristica ALL CAPS; înlocuim spaţiul interior cu "_" şi eliminăm spaţiul iniţial dacă există (începând de la " STATUS ROMANA", denumirile au câte un spaţiu iniţial inexplicabil). Cu head extragem antetul (prima linie) într-un fişier de lucru pe care (folosind iarăşi perl) operăm schimbările tocmai anunţate:
head -n1 evna.csv > HEAD.csv # extrage antetul în "HEAD.csv"
perl -pi -e 's/, /,/g' HEAD.csv # elimină spaţiul iniţial din denumiri
perl -pi -e 's/ /_/g' HEAD.csv # înlocuieşte spaţiul cu '_'
perl -pi -e 's/(\w+)/\u\L$1/g' HEAD.csv # trece de la "ALL CAPS" la "Proper_case"
Poate ar fi de dat o explicaţie (mai ales pentru ultima dintre comenzile de mai sus): mai întâi, s/Expr1/Expr2/g va asigura înlocuirea fiecărei apariţii a Expr1 cu Expr2, în cadrul fişierului indicat; expresia (\w+) colectează câte o denumire (de exemplu, "STATUS_LIMBA_MATERNA"), referită apoi prin $1 şi modificată prin operatorii Perl \u (corespunzător funcţiei ucfirst()) şi \L (care converteşte majusculele în litere mici) - rezultând (pentru exemplul dat) "Status_limba_materna".
În final, "pastăm" conţinutul lui "HEAD.csv" peste prima linie din fişierul nostru de date "evna.csv" (înlocuind vechiul antet al acestuia).
Obţinerea unor tabele de contingenţă
Putem folosi unele programe utilitare clasice, pentru a obţine imediat diverse statistici. Cu wc -l determinăm numărul de rânduri din fişier:
vb@Home:~/Evna$ wc -l evna.csv
163419 evna.csv
Rezultă că la examen au fost înscrişi 163418 elevi (am scăzut desigur, rândul de antet). Să stabilim şi provenienţa acestora, după mediu (urban/rural) şi după sex (M/F).
a) - folosind AWK (sau eventual, Python)
Mai general, am avea de găsit frecvenţele valorilor posibile ale unei variabile, într-o serie dată de observaţii asupra acesteia. Soluţionarea standard constă în instituirea unui tablou asociativ (sau hash în Perl, sau dicţionar în Python) având drept chei valorile posibile ale variabilei respective şi având 0 drept valoare iniţială (pe fiecare cheie); se parcurge lista observaţiilor şi se incrementează valoarea corespunzătoare cheii curent observate.
În cazul nostru, am considera un "dicţionar" sm[] având drept chei valorile posibile (sau combinaţii ale acestora, de exemplu F_RURAL) din coloanele "Sex" (a doua) şi "Mediu" (a patra); de fiecare dată când în aceste coloane linia curentă are (de exemplu) valorile "F" şi respectiv "URBAN", atunci incrementăm valorile sm["F"] şi sm["F_URBAN"] (analog în celelalte cazuri de chei). În limbajul AWK aceasta s-ar putea formula astfel, într-un fişier "sex_mediu.awk":
BEGIN { FS = "," } # câmpurile din fişierul de intrare sunt separate prin ","
NR > 1 { # execută pentru fiecare linie, începând cu a doua (ignoră antetul)
sm[$2] += 1 # contorizează valorile "M" şi "F" din câmpul al doilea ("Sex")
sm[$2"_"$4] += 1 # contorizează cele patru combinaţii "F|M_URBAN|RURAL"
}
END { OFS = "\t" # la afişare, separă câmpurile prin câte un caracter "\t" (TAB)
print "", "F", "M", "total"
print "Rural", sm["F_RURAL"], sm["M_RURAL"], sm["F_RURAL"]+sm["M_RURAL"]
print "Urban", sm["F_URBAN"], sm["M_URBAN"], sm["F_URBAN"]+sm["M_URBAN"]
print "total", sm["F"], sm["M"], sm["F"] + sm["M"]
}
Lansând interpretorul awk (pentru programul redat mai sus) obţinem imediat acest tabel de contingenţă, pentru variabilele "Mediu" şi "Sex" din fişierul "evna.csv":
vb@Home:~/Evna$ awk -f sex_mediu.awk evna.csv
F M total
Rural 39095 36885 75980
Urban 44206 43232 87438
total 83301 80117 163418
AWK este un limbaj (extrem de) specializat pentru operaţii pe fişiere de text delimitat (precum CSV) şi este încă, foarte concis - încât am putea fi siguri că programul redat mai sus este sensibil mai rapid decât un program similar în Perl, sau în Python. Dar iată şi o versiune în Pyton:
import csv
sm = dict.fromkeys(['F', 'M', 'F_RURAL', 'M_RURAL', 'F_URBAN', 'M_URBAN'], 0)
with open('evna.csv') as csvfile:
evna = csv.DictReader(csvfile)
for row in evna:
sm[row['Sex']] += 1
sm[row['Sex'] + '_' + row['Mediu']] += 1
print "\tF", "\tM", "\ttotal"
print "Rural\t", sm["F_RURAL"], '\t',sm["M_RURAL"], '\t',sm["F_RURAL"]+sm["M_RURAL"]
print "Urban\t", sm["F_URBAN"], '\t',sm["M_URBAN"], '\t',sm["F_URBAN"]+sm["M_URBAN"]
print "total\t", sm["F"], '\t',sm["M"], '\t',sm["F"] + sm["M"]
Acest program Python este cât se poate de asemănător celui în AWK, de mai sus - dar este mai puţin elegant; cele două linii de program AWK executate pentru fiecare linie de text din fişierul "evna.csv" au drept corespondent primele 7 linii din programul Pyton de mai sus. Iar timpul de execuţie al programului AWK este de 4-5 ori mai mic decât al programului Python redat mai sus - ceea ce se poate constata folosind programul utilitar time.
b) - folosind instrumentul Pivot Table dintr-o aplicaţie de calcul tabelar
Nu-i cazul să povestim cum ajungem la tabelul şi histograma din imaginea de mai jos: cum am încărcat "evna.csv" în OpenOffice Calc (sau în Excel), care coloane le-am selectat cu mouse-ul, ce meniuri am folosit (PivotTable), ce nume de coloane şi în care paneluri le-am tras cu mouse-ul, ce opţiuni am punctat în fereastrele de dialog; sunt multe operaţii "point-and-click" de făcut şi prima oară poate să-ţi ia şi 5 sau 10 minute ca să obţii tabelul - dar apoi, după ce "prinzi" operaţiile, totul devine banal de făcut (şi nu mai merită nicio explicaţie).
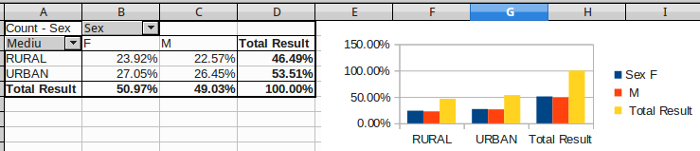
De data aceasta, pentru variaţie faţă de tabelul de mai înainte, am redat valorile ca procente faţă de total; de exemplu, din primul tabel avem F/(F+M) = 83301 / 163418 = 0.50974, ceea ce corespunde cu 50.97% de pe coloana F a rândului totalizator, din ultimul tabel.
c) - folosind SQL (sub MySQL)
Unele aplicaţii de calcul tabelar nu prevăd un instrument "Pivot Table" (de exemplu, Gnumeric şi până nu demult, Google Spreadsheet) - ceea ce îi nemulţumeşte eventual pe utilizatori…; în schimb, toate aplicaţiile sau sistemele care gestionerază şi procesează datele folosind limbajul SQL permit implicit (prin instrucţiuni SELECT cu clauza GROUP BY), generarea de tabele de contingenţă.
Avem deja instalat MySQL şi avem creată deja o bază de date lardoc, în care să putem adăuga acum un nou tabel - anume, tabelul care să aibă drept coloane câmpurile existente în fişierul evna.csv. N-ar fi dificil de preluat cele 21 de denumiri de câmpuri de pe prima linie din evna.csv, urmând a specifica pentru fiecare - în cadrul unei comenzi CREATE TABLE() - ce tip de valori MySQL va conţine coloana respectivă; dar preferăm să folosim csvkit - un excelent pachet de utilitare pentru formatul CSV, între care şi programul csvsql care ne oferă gratis exact comanda "create table" de care avem nevoie:
vb@Home:~/Evna$ csvsql -i mysql evna.csv > evna.sql
Execuţia nu este imediată: pentru a "ghici" cât mai corect ce tip de date MySQL are fiecare coloană, fişierul "evna.csv" (de 14.2 MB) a trebuit să fie parcurs în întregime (am omis o opţiune limitativă); în urma redirectării ieşirii comenzii, obţinem fişierul evna.sql, conţinând:
CREATE TABLE evna (
`Cod_unic_candidat` INTEGER NOT NULL,
`Sex` VARCHAR(1) NOT NULL,
`Data_nastere` DATE NOT NULL,
`Mediu` VARCHAR(5) NOT NULL,
`Cod_siiir` VARCHAR(10) NOT NULL,
`Status_romana` VARCHAR(18) NOT NULL,
`Status_limba_materna` VARCHAR(7),
`Status_matematica` VARCHAR(18) NOT NULL,
`Nota_romana` FLOAT,
`Nota_limba_materna` FLOAT,
`Nota_matematica` FLOAT,
`Contestatie_romana` VARCHAR(2) NOT NULL,
`Nota_contestatie_romana` FLOAT,
`Contestatie_limba_materna` VARCHAR(2) NOT NULL,
`Nota_contestatie_lb_materna` FLOAT,
`Contestatie_matematica` VARCHAR(2) NOT NULL,
`Nota_contestatie_matematica` FLOAT,
`Nota_finala_romana` FLOAT,
`Nota_finala_lb_materna` FLOAT,
`Nota_finala_matematica` FLOAT,
`Media` VARCHAR(6)
);
Următoarele două comenzi invocă interpretorul mysql pentru a crea în baza de date lardoc tabelul evna, conform specificaţiilor de câmpuri din fişierul evna.sql redat mai sus şi respectiv - pentru a încărca în tabelul tocmai creat, înregistrările găsite în fişierul "local" evna.csv (ignorând prima linie):
vb@Home:~/Evna$ mysql lardoc < evna.sql vb@Home:~/Evna$ mysql --local-infile -e > "LOAD DATA LOCAL INFILE 'evna.csv' INTO TABLE lardoc.evna > fields terminated by ',' lines terminated by '\n' > IGNORE 1 ROWS"
Obţinem tabelul de contingenţă pentru variabilele "sex" şi "mediu" selectând din tabel cele două coloane, cu gruparea şi contorizarea corespunzătoare a valorilor:
vb@Home:~/Evna$ mysql -e "SELECT IFNULL(Sex, 'total') AS Sex,
> IFNULL(Mediu, 'total') AS Mediu, COUNT(Sex) AS frequency
> FROM lardoc.evna GROUP BY Sex, Mediu WITH ROLLUP"
+-------+-------+-----------+
| Sex | Mediu | frequency |
+-------+-------+-----------+
| F | RURAL | 39095 |
| F | URBAN | 44206 |
| F | total | 83301 |
| M | RURAL | 36885 |
| M | URBAN | 43232 |
| M | total | 80117 |
| total | total | 163418 |
+-------+-------+-----------+
În mod implicit, clauza WITH ROLLUP adaugă totaluri parţiale sub numele NULL; folosind însă IFNULL(Mediu, 'total') - se vor tipări valorile variabilei "Mediu" ("URBAN" şi "RURAL") şi respectiv, "total" (în loc de "NULL") pentru suma frecvenţelor.
Probabil că limbajul SQL - dată fiind natura sa declarativă şi descriptivă - este cel mai potrivit pentru a formula (sau a explicita) cereri pentru tabele de contingenţă de oricâtă complexitate ar fi nevoie.
Investigarea datelor folosind limbajul R
R este un limbaj de programare de nivel înalt (www.r-project.org) şi totodată mediu de instrumente (rutine preprogramate, sau comenzi generice) pentru diverse necesităţi de cercetare ştiinţifică din varii domenii, dar în special pentru analiză statistică şi pentru vizualizarea datelor.
Lansăm R în directorul /Evna şi preluăm datele din fişierul "evna.csv", în variabila evna; inspectăm apoi obiectul obţinut, invocând funcţia str():
vb@Home:~/Evna$ R -q # Don't print startup message (--quiet) > evna <- read.csv("evna.csv") # "<-" este operatorul de atribuire > str(evna) # display the internal structure of an R object 'data.frame': 163418 obs. of 21 variables: $ Cod_unic_candidat : int 11096387 11096396 10870214 8818594 8820602 ... $ Sex : Factor w/ 2 levels "F","M": 1 1 1 2 2 1 1 2 2 1 ... $ Data_nastere : Factor w/ 1766 levels "1900-04-09","1900-10-12",..: 1451 1335 ... $ Mediu : Factor w/ 2 levels "RURAL","URBAN": 2 2 2 2 2 2 2 2 2 2 ... $ Cod_siiir : num 4.06e+09 4.06e+09 4.06e+09 4.06e+09 4.06e+09 ... $ Status_romana : Factor w/ 3 levels "Absent","Eliminat cu nota 1",..: 3 3 3 ... $ Status_limba_materna : Factor w/ 3 levels "","Absent","Prezent": 1 1 1 1 1 1 1 1 ... $ Status_matematica : Factor w/ 3 levels "Absent","Eliminat cu nota 1",..: 3 3 3 ... $ Nota_romana : num 1.75 5.4 5.4 7 7.35 6.85 4.9 6.45 8.3 3.8 ... $ Nota_limba_materna : num NA NA NA NA NA NA NA NA NA NA ... $ Nota_matematica : num 4 4.75 3.5 7 5.45 4.65 5 7.5 8.85 3.3 ... $ Contestatie_romana : Factor w/ 2 levels "DA","NU": 2 2 2 2 2 2 2 1 2 2 ... $ Nota_contestatie_romana : num NA NA NA NA NA NA NA 7.65 NA NA ... $ Contestatie_limba_materna : Factor w/ 2 levels "DA","NU": 2 2 2 2 2 2 2 2 2 2 ... $ Nota_contestatie_lb_materna: num NA NA NA NA NA NA NA NA NA NA ... $ Contestatie_matematica : Factor w/ 2 levels "DA","NU": 2 2 2 2 2 2 2 2 2 2 ... $ Nota_contestatie_matematica: num NA NA NA NA NA NA NA NA NA NA ... $ Nota_finala_romana : num 1.75 5.4 5.4 7 7.35 6.85 4.9 7.65 8.3 3.8 ... $ Nota_finala_lb_materna : num NA NA NA NA NA NA NA NA NA NA ... $ Nota_finala_matematica : num 4 4.75 3.5 7 5.45 4.65 5 7.5 8.85 3.3 ... $ Media : Factor w/ 705 levels "","1","10","1.02",..: 135 313 261 467 ... >
A rezultat un obiect de tip "data.frame", asemănător ca structură cu tabelele MySQL; sunt 163418 observaţii (sau înregistrări, sau rânduri) pentru 21 de variabile (sau câmpuri, sau coloane). Variabila (sau "câmpul", în MySQL) Sex poate fi accesată folosind sintaxa evna$Sex şi ca tip de date este un "Factor" cu două nivele (anume "F" şi "M").
Vedem deja în textul afişat mai sus, unele greşeli produse probabil pe parcursul procesului iniţial de înregistrare a datelor; de exemplu, apare "1900-04-09" drept data naşterii vreunuia dintre elevi (însemnând că avea vârsta de 115 ani, absurd). Pe de altă parte, cele opt variabile evna$Nota_ sunt de tip "num" (au valori numerice reprezentate în virgulă mobilă) - dar evna$Media este un "Factor" cu 705 nivele - oarecum contrar aşteptării de a fi şi ea, variabilă de tip "num".
Vom investiga mai jos inclusiv situaţiile tocmai semnalate, dar întâi să producem şi în R tabelul de contingenţă de care ne-am ocupat mai sus în AWK, în Office Calc şi în SQL.
Contingenţă şi vizualizare, pentru variabilele "Mediu" şi "Sex"
Putem folosi funcţia table() pentru a genera tabelul de frecvenţe corespunzător factorilor respectivi şi apoi funcţia addmargins(), pentru a-l completa (la dreapta şi dedesubt) cu totaluri marginale:
> mediuSex <- addmargins(table(evna[c('Mediu', 'Sex')]))
> mediuSex
Sex
Mediu F M Sum
RURAL 39095 36885 75980
URBAN 44206 43232 87438
Sum 83301 80117 163418
>
Dacă vrem, putem trece la procente: nr = mediuSex[3, 3] ne dă numărul total de elevi şi apoi obţinem cele 9 procente faţă de total prin round(mediuSex / nr * 100, 2).
Pentru vizualizare, putem folosi funcţia ggplot(), după ce transformăm tabelul într-un "data.frame" (pachetul ggplot2 trebuie să fi fost instalat deja şi încărcat în sesiunea R curentă):
> mediuSex.df <- as.data.frame(mediuSex) # a inspecta cu str(mediuSex.df)
> ggplot(mediuSex.df, aes(x=Mediu, y=log10(Freq), color=Sex)) + geom_point(size=3)
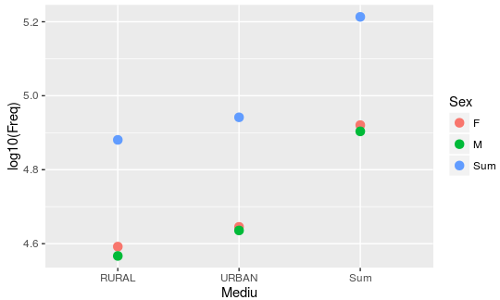
Cu aes() (de la "aestetics") se stabileşte cum să fie dispuse variabilele: pe axa orizontală sunt marcate intrările orizontale (numele de linii) din tabelul de mai sus; intrările verticale (denumirile coloanelor) sunt marcate prin trei culori; frecvenţele (cele 9 numere din tabel) sunt măsurate logaritmic pe axa verticală (de exemplu, log10(163418) este 5.2133 - nivelul maxim al variabilei "Sum" din imagine).
Factorul "Judeţ" (şi… meritele unor documente oficiale)
În mod sigur, vom dori să facem şi o analiză pe judeţe a rezultatelor; ar fi două câmpuri dintre cele 21 redate mai sus, care ar putea eventual să codifice şi judeţul din care provine elevul respectiv: fie "Cod_unic_candidat", fie "Cod_siiir" (fie… amândouă). Despre "SIIIR" aflăm că înseamnă "Sistemul Informatic Integrat al Învăţământului din România", iar "COD SIIIR" este format din 10 cifre dintre care primele două reprezintă judeţul din care face parte localitatea din care face parte unitatea şcolară căreia îi corespunde codul respectiv.
Desigur, ştim că sunt 41 sau 42 de judeţe - dar nu ştim care este pentru fiecare, codul de câte două cifre care îi corespunde în SIIIR (ştim doar că există exact 100 de coduri de câte 2 cifre, "00".."99").
Căutăm pe Internet desigur… găsim aşa ceva retea_scolara_specializari_2014.pdf - un document PDF de 686 de pagini, reprezentând un tabel liniat pe rânduri şi coloane pe fiecare dintre primele 345 de pagini, cu antet scris pe prima pagină, primele două coloane fiind cele care ne-ar interesa "Judeţ" şi respectiv "Cod SIIIR" (paginile 346..686 sunt fie goale, fie conţin pe la mijloc câte un fragment de cuvânt sau de două-trei cuvinte…). Acest tabel uriaş în format PDF (conţinând într-adevăr toate profilele şi toate specializările din toate unităţile şcolare din toate judeţele) - cu siguranţă că nu foloseşte nimănui şi chiar este aberant să tipăreşti (că ăsta-i scopul principal pentru formatul PDF) 345 de pagini în care de exemplu, textul "Cu personalitate juridică" este scris pe fiecare rând (anume, în a cincea coloană a tabelului), exceptând 4 rânduri.
Documentul PDF de 686 de pagini tocmai citat - ar putea avea un singur merit (tocmai pentru că este şi în format PDF): l-ar scuti pe ministru de necesitatea vreunei explicaţii pentru demiterea fără jenă şi fără menajamente a "specialiştilor" care i-ar prezenta documentul respectiv; deasemenea - şi asta este deja revoluţionar - i-ar da de gândit: nu de funcţionari subsumaţi la Microsoft Word şi la "point-and-click" ducem noi lipsă, ci de persoane care înţeleg cum e cu datele, cu informaţiile şi cu reprezentările, care nu încep numele unui câmp de date cu spaţiu, care ştiu să verifice şi să corijeze datele (evitând de exemplu, cazul evidenţiat mai sus de elevi cu vârsta de 115 ani) şi care nu scriu nicăieri de 20000 de ori, un acelaşi lucru.
După căutări nereuşite pentru date privitoare la "cod SIIIR" (în format utilizabil, desigur) - mi-am amintit de "Open-source Governance"… (trecuse ceva timp de când descărcasem "EVNAT-2015.csv", iar "data.gov.ro" nu figura în primele vreo 5 pagini de rezultate ale căutării). Şi într-adevăr, la data.gov.ro am găsit "retea_scolara_specializari_2014" în format CSV (bineînţeles că este prezent şi documentul PDF de 686 pagini descris mai sus… mare-i grădina Domnului!). Am descărcat deci documentul CSV respectiv (în directorul de lucru /Evna) şi am încercat direct să-l preiau în sesiunea R curentă:
> retsco <- read.csv("retea_scolara_specializari_2014.csv")
Error in make.names(col.names, unique = TRUE) :
invalid multibyte string at '<ff><fe>J'
Aducerea pe Linux a unui fişier text creat pe un sistem Windows - de obicei atrage necazuri de conversie; să inspectăm la nivel hexazecimal (folosind xxd), începutul fişierului:
vb@Home:~/Evna$ xxd -g 1 -l 16 retea_scolara_specializari_2014.csv
0000000: ff fe 4a 00 75 00 64 00 65 00 1b 02 2c 00 43 00 ..J.u.d.e...,.C.
Fişierul respectiv are o codificare UTF-16: fiecare caracter este codificat pe câte 2 octeţi, aşezaţi în memorie în ordinea indicată de "prefixul" fişierului - primii doi octeţi #FF, #FE (care în această ordine, indică reprezentarea "little-endian": la adresa mai mică stă octetul cel mai puţin semnificativ). Astfel, cei doi octeţi care urmează imediat după "prefix" compun valoarea 0x004a, reprezentând astfel litera "J"; următorii doi 0x0075 dau litera "u"; iar codul 0x021b ("boldat", în linia de coduri redată mai sus) ne dă caracterul "LATIN SMALL LETTER T WITH COMMA BELOW" adică litera ț.
help(read.csv) ne-a arătat că - tocmai pentru cazul trecerii de pe un sistem pe altul - avem de explicitat codificarea fişierului (în argumentul "fileEncoding"):
> retsco <- read.csv("retea_scolara_specializari_2014.csv", fileEncoding="UTF-16")
> str(retsco) # inspectăm structura constituită prin preluarea datelor din fişier
'data.frame': 24089 obs. of 11 variables:
$ Județ : Factor w/ 42 levels "ALBA","ARAD",..: 1 1 1 1 1 ...
$ Cod.SIIIR : num 1.61e+08 1.61e+08 1.61e+08 1.61e+08 1.61e+08 ...
# ...
Dintre cele 11 coloane de date ne interesează numai primele două. Poate ne convine că "Judeţ" este structurat drept "factor" (cu 42 de valori, corespunzătoare judeţelor); dar "Cod.SIIIR" a fost citit ca "num", însemnând neplăcut eliminarea cifrei iniţiale în cazul în care aceasta ar fi zero (1.61e+08 este un număr care are 9 cifre, nu 10; codul judeţului nu este "16", ci "01" - dar cifra iniţială "0" lipseşte). Pentru îndreptarea lucrurilor, pur şi simplu repetăm comanda de citire din fişierul iniţial, adăugând acum şi parametrul colClasses prin care forţăm convenabil tipul coloanelor:
> retsco <- read.csv("retea_scolara_specializari_2014.csv",
fileEncoding="UTF-16",
colClasses=c("factor", "character"))
> retsco$Cod.SIIIR[1] # afişează prima valoare din coloană
[1] "0161102318" # codul judeţului este "01" (primele două dintre cele 10 cifre)
Observăm apoi că în fişier se foloseşte "ț" (cu virgulă dedesubt) - caracterul de cod 0x021B; dar pe sistemul propriu folosesc ţ cu "cedilla" - de cod 0x0163. Pentru comoditatea lucrului, preferăm să schimbăm denumirea "Județ" cu "Jud"; mai mult: reţinem numai primele câte două cifre ale valorilor (de câte 10 cifre) din coloana "Cod.SIIIR" şi chiar schimbăm şi denumirea, în "codJud". În final, folosim funcţia subset() pentru a păstra numai primele două coloane:
> colnames(retsco)[1] <- "Jud" # schimbă denumirea "Județ" cu "Jud" > retsco$Cod.SIIIR <- substr(retsco$Cod.SIIIR, 1, 2) # păstrează doar primele 2 cifre > colnames(retsco)[2] <- "codJud" # schimbă denumirea "Cod.SIIIR" cu "cod.Jud" > retsco <- subset(retsco, select = c(Jud, codJud)) # numai primele două coloane > str(retsco) 'data.frame': 24089 obs. of 2 variables: $ Jud : Factor w/ 42 levels "ALBA","ARAD",..: 1 1 1 1 1 1 1 1 1 1 ... $ codJud: chr "01" "01" "01" "01" ...
Fiindcă am păstrat numai primele două coloane din fişierul iniţial şi numai primele două cifre din codul SIIIR, rezultă că toate liniile care în fişierul iniţial corespundeau diverselor localităţi şi unităţi şcolare dintr-un acelaşi judeţ, acum au exact acelaşi conţinut (numele judeţului şi codul de două cifre corespunzător acestuia). Pentru a obţine lista judeţelor şi codurilor aferente, dar şi numărul unităţilor şcolare din fiecare judeţ cel mai comod este să folosim funcţia count din pachetul plyr:
> library(plyr) # <help(plyr)> > (jud42 <- count(retsco, c("Jud", "codJud"))) # de câte ori apare fiecare înregistrare Jud codJud freq 1 ALBA 01 537 # 537 unităţi şcolare înregistrate în judeţul Alba 2 ARAD 02 564 ... 10 BUZAU 10 514 11 CALARASI 51 364 # codul "51" (în loc de "11" - cel alfabetic) 12 CARAS-SEVERIN 11 492 ... 28 MUNICIPIUL BUCURESTI 40 1323 # De ce nu era suficient "Bucureşti"?! 29 MURES 26 657 ... 41 VASLUI 37 533 # 533 unităţi şcolare înregistrate în judeţul Vaslui 42 VRANCEA 39 385
Codurile de două cifre atribuite judeţelor urmează linia alfabetică a denumirilor fără diacritice, cu patru excepţii ("CALARASI" cu "51", "GIURGIU" cu "52", "MUNICIPIUL BUCURESTI" cu "40"; codurile pentru "SATU MARE" şi "SALAJ" sunt inversate faţă de ordinea alfabetică).
"DAMBOVITA" şi "Dâmboviţa", şcoli şi populaţie
Este oarecum firesc să ne întrebăm de ce în unele judeţe sunt (mult) mai multe şcoli decât în altele? De ce în SUCEAVA avem 818 şcoli, iar în IALOMITA 379? Probabil proporţia respectivă s-ar explica suficient, comparând densitatea populaţiei pentru judeţele respective? (a subînţelege totuşi natura didactică a demersurilor noastre). Sunt suficiente şcoli în Bucureşti? (sau în judeţul Buzău, ş.a.m.d.)
La data.gov.ro, în setul de date denumit "Demografie" am găsit fişierul Excel "populatia-romaniei-pe-judete.xls"; desigur, un document funcţionăresc - patru tabele aşezate pe orizontală unul după celălalt, având fiecare coloanele "Nr. crt." şi "Judeţul" şi apoi, pe diverşi ani, numărul de locuitori "rezidenţi" sau "cu domiciliul stabil" în judeţele respective. Am ales ultimul tabel, "13. POPULAŢIA DUPĂ DOMICILIU A ROMÂNIEI PE JUDEŢE LA 1 IULIE ÎN ANII 2002-2014" şi anume coloana Excel AR ("Judeţul") şi coloana ultimă BE ("2014") - pe care le-am copiat într-o foaie de calcul nouă, salvând în final datele respective într-un fişier CSV "judPop.csv".
Desigur că ar fi suficient să adăugăm coloana "freq" din obiectul "jud42" obţinut şi redat mai sus şi să vedem apoi cum corelăm între ele cele două variabile - numărul de locuitori şi respectiv, numărul de şcoli, pe judeţe. Dar parcă este cazul să vrem ceva mai mult…
Prima constatare (şi plăcută) este că judeţele sunt înregistrate corect (de exemplu "Dâmboviţa") şi nu funcţionăreşte ("DAMBOVITA"). Apoi, pentru ca în "judPop.csv" să avem judeţele în ordine alfabetică avem de făcut o singură modificare: ultima linie înregistrează "M.Bucureşti" şi o aducem la locul ei alfabetic, între "Mehedinţi" şi "Mureş".
Vrem să îmbinăm datele din "jud42" şi din "judPop.csv", încât în final să avem un obiect "data frame" care să conţină în ordine alfabetică denumirile corecte ale judeţelor, codurile SIIIR corespunzătoare judeţelor, numărul de şcoli şi respectiv, populaţia fiecăruia (vom avea de reutilizat acest obiect când ne vom ocupa eventual de mediile elevilor).
În "jud42" avem de făcut patru inversări de linii ("BRAILA" cu "BRASOV", "CALARASI" cu "CARAS-SEVERIN", "SALAJ" cu "SATU MARE" şi "VALCEA" cu "VASLUI") şi cel mai simplu este să folosim funcţia write.csv() pentru a salva datele respective într-un fişier "42jud.csv" pe care să-l edităm manual; ca urmare, în final acest fişier va avea judeţele în exact aceeaşi ordine în care apar în fişierul judPop.csv. Următoarea secvenţă de comenzi construieşte structura de date indicată mai sus:
În plus, n-am rezistat tentaţiei de a schimba denumirile coloanelor ("Jud", "codJud", "freq" şi "pop"), editând linia de antet (prima) din fişierul "42jud.csv" obţinut mai sus - încât acum vechea structură "jud42" devine:
> ( jud42 <- read.csv("42jud.csv") ) judeţ cod şcoli populaţie 1 Alba 1 537 383252 2 Arad 2 564 475841 # ... 11 Caraş-Severin 11 492 332267 12 Călăraşi 51 364 320302 # ... 28 M.Bucureşti 40 1323 2110752 29 Mureş 26 657 597849 # ... 40 Vaslui 37 533 476406 41 Vâlcea 38 513 406314 42 Vrancea 39 385 393303
Dacă ordonăm după numărul de şcoli, putem vedea uşor anumite posibile discrepanţe:
> jud42[ order(jud42$şcoli), ]
judeţ cod şcoli populaţie
39 Tulcea 36 272 247111
# ...
34 Sălaj 31 378 248794 # 100 şcoli (şi 1700 locuitori) mai mult ca Tulcea
# ...
21 Harghita 19 513 334586
41 Vâlcea 38 513 406314
10 Buzău 10 514 484524 # 150000 locuitori mai mult ca Harghita
# ...
De exemplu, judeţele Tulcea şi Sălaj au cam acelaşi număr de locuitori, dar 100 de şcoli diferenţă; iar Harghita şi Buzău au cam acelaşi număr de şcoli, dar diferă cu aproape 150000 de locuitori. Aceasta evidenţiază faptul că numărul de şcoli are şi alte determinări (de un grad sau altul) decât numărul de locuitori; dar în general, cele două variabile cresc într-un acelaşi sens iar norul de puncte format pe scatterplot-ul corespunzător lor sugerează (eventual prin analogie cu situaţii tipice întâlnite altădată) posibilitatea unei relaţionări liniare:
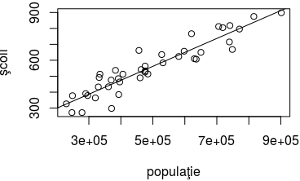
> jud41 <- subset(jud42, cod != 40) > with(jud41, plot(şcoli ~ populaţie)) > with(jud41, cor(şcoli, populaţie)) [1] 0.9324982 coeficientul de corelaţie > linie <- with(jud41, lm(şcoli ~ populaţie)) Coefficients: 1.247e+02 8.744e-04 dreapta de regresie: Y = 0.00087*X + 125 > abline(linie) # adaugă dreapta pe scatterplot
jud41 obţinut mai sus prin funcţia subset(), reprezintă cele 41 de judeţe propriu-zise; am lăsat deoparte "M.Bucureşti" (cu cod=40), pentru că are "populaţie" mult peste media celorlalte.
Cu plot() am vizualizat "norul" de puncte al valorilor celor două variabile; dâra punctelor ne sugerează o linie dreaptă. Folosind with() ne-am scutit de notaţia completă jud41$şcoli şi jud41$populaţie.
Coeficientul de corelaţie - obţinut prin funcţia cor() - este foarte aproape de 1, ceea ce sprijină ideea unui model liniar al relaţiei dintre cele două variabile; funcţia lm() ne-a dat apoi cei doi coeficienţi pentru dreapta de regresie a punctelor respective, marcată (prin funcţia abline()) peste norul de puncte, în imaginea redată mai sus.
Folosind pachetul ggplot2 putem îmbunătăţi spectaculos vizualizarea grafică a datelor noastre:
Prin funcţia aes() am specificat ca variabilele "populaţie" şi "şcoli" să fie asociate axei orizontale X şi respectiv celei verticale Y, iar "judeţ" să aibă valorile redate prin "puncte" de diferite culori şi mărimi. Astfel, coordonatele X şi Y ale fiecărui "punct" indică numărul de locuitori şi respectiv numărul de şcoli din judeţul respectiv; punctele sunt de fapt, buline colorate - dar este greu de stabilit un set de 41 de culori inconfundabile; de aceea, am încercat şi o a doua sugestie pentru recunoaşterea judeţului: mărimea bulinei este "proporţională" (dar nu tocmai precis) cu locul în ordinea alfabetică a judeţelor (de fapt, prin specificaţia size= cod - cu locul în ordinea indusă de codul SIIIR).
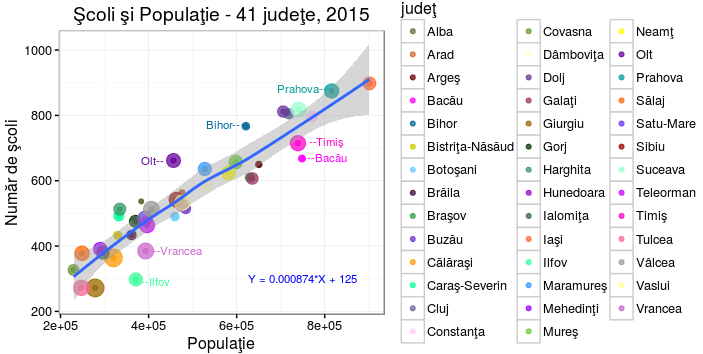
Am invocat geom_smooth() fără a explicita vreun argument şi ca urmare, s-a folosit metoda de "netezire" implicită - anume "method= loess"; în cazul "method= lm" s-ar căuta acea dreaptă care este cel mai apropiată de punctele date (pentru care suma pătratelor abaterilor pe verticală ale punctelor faţă de dreaptă este minimă) - în schimb, modelul "loess" caută să facă şi o netezire "locală", ţinând cont şi de punctele aflate în imediata vecinătate a fiecărui punct. A rezultat cum se vede pe figură, o "linie de regresie" care este foarte apropiată de o dreaptă propriu-zisă (dar nu este o dreaptă); zona marcată gri din jurul acestei linii reprezintă intervalul de încredere (sau poate, "banda de predicţie").
În Bucureşti (exclus în reprezentarea de mai sus) sunt 1323 de şcoli, dar "prezicerea" bazată acum pe dreapta de regresie găsită mai sus este cu cel puţin 400 de şcoli mai mare:
> fit <- with(jud41, lm(şcoli ~ populaţie)) # reconstituie regresia de mai sus > pop.40 <- data.frame(populaţie=jud42[jud42$cod == 40, ]$populaţie) # 2110752 locuitori > round(predict(fit, pop.40, interval="predict")) fit lwr upr 1970 1754 2187 # Y = 0.000874*2110752 + 125 = 1970; între 1754 şi 2187 şcoli
Dar nu-i cazul să fi greşit pe undeva; este îndeobşte clar că numărul de şcoli depinde (în primul rând) de numărul de locuitori, dar depinde cu siguranţă şi de alte variabile (iar pe de altă parte, Bucureşti este mult peste media celorlalte, ca număr de locuitori). Putem vedea pentru fiecare judeţ, "prezicerea" conform dreptei de regresie găsite mai sus şi diferenţa faţă de valoarea reală a numărului de şcoli:
> jud41$fitted <- round(fitted(fit)) # adaugă o coloană pentru valorile de regresie > jud41$resid <- round(resid(fit)) # coloana diferenţelor valorilor reale faţă de regresie > jud41 judeţ cod şcoli populaţie fitted resid 1 Alba 1 537 383252 460 77 # 77 şcoli "mai mult decât s-ar cuveni" 2 Arad 2 564 475841 541 23 3 Argeş 3 650 650332 693 -43 # 43 şcoli "mai puţin decât s-ar cuveni" 4 Bacău 4 668 748402 779 -111 5 Bihor 5 767 620866 668 99 6 Bistriţa-Năsăud 6 433 329592 413 20 7 Botoşani 7 490 460065 527 -37 8 Braşov 8 610 629814 675 -65 9 Brăila 9 434 361218 441 -7 10 Buzău 10 514 484524 548 -34 11 Caraş-Severin 11 492 332267 415 77 12 Călăraşi 51 364 320302 405 -41 13 Cluj 12 805 718633 753 52 14 Constanţa 13 796 770783 799 -3 15 Covasna 14 327 229563 325 2 16 Dâmboviţa 15 584 531715 590 -6 17 Dolj 16 812 705760 742 70 18 Galaţi 17 607 635559 680 -73 19 Giurgiu 52 272 278630 368 -96 20 Gorj 18 476 369857 448 28 21 Harghita 19 513 334586 417 96 22 Hunedoara 20 526 475542 541 -15 23 Ialomiţa 21 379 296162 384 -5 24 Iaşi 22 898 901590 913 -15 25 Ilfov 23 298 371037 449 -151 26 Maramureş 24 636 527663 586 50 27 Mehedinţi 25 391 290253 378 13 29 Mureş 26 657 597849 647 10 # 28 a rămas rezervat "M.Bucureşti", exclus aici 30 Neamţ 27 624 580933 633 -9 31 Olt 28 662 456554 524 138 32 Prahova 29 875 815741 838 37 33 Satu-Mare 30 485 392129 468 17 34 Sălaj 31 378 248794 342 36 35 Sibiu 32 542 463436 530 12 36 Suceava 33 818 740861 773 45 37 Teleorman 34 464 396522 471 -7 38 Timiş 35 715 739217 771 -56 39 Tulcea 36 272 247111 341 -69 40 Vaslui 37 533 476406 541 -8 41 Vâlcea 38 513 406314 480 33 42 Vrancea 39 385 393303 469 -84
Dacă am considera că numărul de locuitori este într-adevăr factorul determinant (principal) pentru numărul de şcoli, atunci rezultatele redate mai sus spun că 8 judeţe au cu cel puţin 50 de şcoli mai mult decât s-ar cuveni (cel mai mult 138, la judeţul Olt) şi un număr de 8 judeţe au cu cel puţin 50 de şcoli mai puţin decât s-ar cuveni (la Ilfov avem minus 151 de şcoli); iar un număr de 9 judeţe au cam cât s-ar cuveni, plus sau minus maximum 10 şcoli (Neamţ -9, Mureş +10).
vezi Cărţile mele (de programare)