Expresii aritmetice în R (partea a III-a)
[1] Expresii aritmetice în R partea I şi partea a II-a
Pentru patru operanzi distincţi avem (v. [1]) 7680 de expresii aritmetice elementare; ele sunt distincte din punct de vedere sintactic, dar în privinţa valorii ele sunt distribuite într-un anumit număr de clase de echivalenţă. În majoritatea cazurilor, faptul că rezultă o aceeaşi valoare numerică se poate justifica imediat invocând comutativitatea şi asociativitatea pentru adunare şi înmulţire, sau reguli de calcul simple privitoare la opusul unei sume sau inversul unui produs de numere:
Expresie Valoare "(4+3)*(1-6)" -35 "(3+4)*(1-6)" -35 "(1-6)*(3+4)" -35 "(1-6)*(4+3)" -35
Expresie Valoare "1+(3+(4+6))" 14 "1+((3+4)+6)" 14 "1+(3+(6+4))" 14 "((1+3)+6)+4" 14
Expresie Valoare "((1-3)-6)*4" -32 "((1-6)-3)*4" -32 "(1-(3+6))*4" -32 "(1-(6+3))*4" -32
Expresie Valoare "((1/3)/6)*4" 0.2222222 "((1/6)/3)*4" 0.2222222 "(1/(3*6))*4" 0.2222222 "(1/(6*3))*4" 0.2222222
Rămân ca interesante acele expresii care au aceeaşi valoare, dar nu se pot reduce imediat una la alta prin comutarea sau asocierea operanzilor (sau prin alte reguli simple de calcul); iată un exemplu:
"((4/6)+1)/3" 0.555555555555555 "1-(4/(6+3))" 0.555555555555556 # tot 0.(5) dar reprezentarea internă diferă...
Cele două expresii de mai sus au aceeaşi valoare - fracţia 5/9=0.(5); dar reprezentarea internă (sau/şi afişarea) poate să difere (ca aici, la ultima zecimală) şi echivalarea lor trebuie eventual forţată.
Cum generăm expresiile aritmetice?
Ne-am procurat ceva motive pentru a relua lucrurile… În [2] (cu "ar_exp.h" şi void phrase() în C++) şi apoi în [1] (prin funcţia R all4expr()) am constituit şi am afişat rând pe rând, expresiile respective; acum le structurăm direct de la bun început, fără a mai implica vreun fişier intermediar. În plus, acum am avea un răspuns (dar negativ) la această întrebare practică: merită sau nu, să ţinem seama din start de unele proprietăţi elementare ale operaţiilor, încât să evităm generarea de expresii care se pot reduce una la alta aplicând reguli simple de calcul direct.
Numărul de expresii aritmetice corect formate cu un anumit număr de operatori binari este dat de numerele lui Catalan; cu trei operatori binari u, v, w avem următoarele 5 posibilităţi:
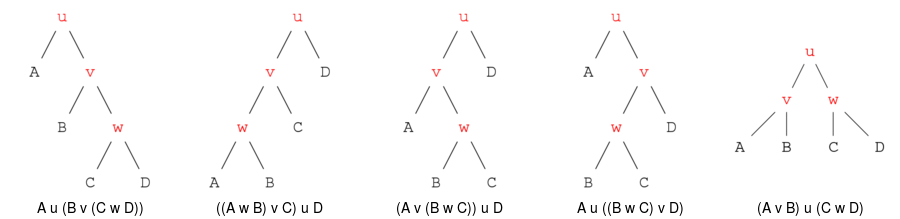
Permutând cei 4 operanzi, rezultă 5×4! = 120 de expresii. Desigur, în cazul particular când operatorii sunt toţi '+', sau sunt toţi '*' - operaţii care sunt asociative şi comutative - cele 120 de expresii se reduc în mod evident la un acelaşi lucru: 'A+B+C+D', respectiv 'A*B*C*D' (şi eventual, trebuie să impunem A<B<C<D, pentru a evita generarea expresiei pentru fiecare permutare de operanzi).
Dar ideea de a ţine seama şi de proprietăţile operaţiilor în cursul generării expresiilor angajează o groază de cazuri particulare, însemnând până la urmă un program haotic. De exemplu, iată cum ar decurge analiza pe cei 5 arbori pentru cazurile cu două operaţii de adunare şi una de împărţire:
u = '+', v = '+', w = '/'
A + (B + (C / D)) se reduce la [1]: A + B + C/D cu A < B
((A / B) + C) + D A/B + C + D adică tot [1], cu permutarea (şi comutarea) operanzilor
(A + (B / C)) + D A + B/C + D adică tot [1], cu permutarea operanzilor
A + ((B / C) + D) tot [1]
(A + B) + (C / D)
u = '+', v = '/', w = '+'
A + (B / (C + D)) se reduce la [2]: A + B/(C + D) cu C < D
((A + B) / C) + D se reduce la [3]: (A + B)/C + D cu A < B
(A / (B + C)) + D A/(B + C) + D adică tot [2], cu permutarea (şi comutarea) operanzilor
A + ((B + C) / D) A + (B + C)/D adică tot [3], permutând şi comutând operanzii
(A / B) + (C + D) se reduce la [1]
u = '/', v = '+', w = '+'
A / (B + (C + D)) se reduce la [4]: A/(B + C + D) cu B < C < D
((A + B) + C) / D se reduce la [5]: (A + B + C)/D cu A < B < C
(A + (B + C)) / D tot [5]
A / ((B + C) + D) tot [4]
(A + B) / (C + D) [6]: (A + B)/(C + D) cu A < B şi C < D
Ar fi de făcut o asemenea analiză pentru fiecare 3 operatori, urmând ca în programul de generare să cumulăm expresiile reduse (precum cele marcate [1]..[6] mai sus), ţinând mereu cont şi de ordinea operanzilor; este de bănuit (dar jenant…) că am produs totuşi vreo zece pagini de analize, până să abandonăm liniştit această idee şi să revenim la un program generic, cât mai simplu.
Construcţia unui program R pentru generarea expresiilor aritmetice
Considerăm operatorii aritmetici obişnuiţi, introducându-i prin vectorul:
Pentru a genera toate tripletele (u, v, w) de operatori, constituim întâi o listă în care fiecare dintre cele trei componente este o copie a vectorului operatorilor:
Îmbinăm în toate modurile câte un element din cele trei liste, obţinând tripletele de operatori:
În următoarea funcţie se parcurg tripletele de operatori şi permutările operanzilor, constituind de fiecare dată (şi cumulând într-un vector final) cele câte 5 expresii aritmetice corespunzătoare:
Dar în principiu, am procedat ineficient: vectorul 'vexpr' cu lungimea iniţială 0 este extins prin funcţia append() cu câte 5 componente, pentru fiecare permutare a operanzilor (şi fiecare set de operatori) - ceea ce de fapt, înseamnă (de fiecare dată) realocarea memoriei şi copierea în noua zonă a valorilor existente la momentul respectiv (adăugând cele 5 noi valori şi eventual, ştergând vechiul vector).
Reformulăm, alocând din start memoria necesară vectorului de expresii şi gestionând apoi un index la care înscriem în vectorul respectiv cele câte 5 expresii curente (evitând astfel, crearea şi copierea repetată de vectori intermediari din ce în ce mai lungi):
Putem măsura şi compara timpii de execuţie, folosind pachetul microbenchmark:
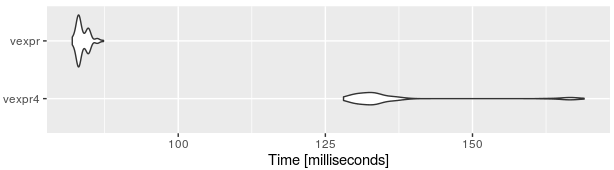
Constatăm astfel că varianta bazată pe prealocarea memoriei este cam de 1.5 ori mai rapidă decât cea bazată pe append().
Subseturi injective
Avem definită în mod tacit funcţia de evaluare, care asociază fiecărei expresii aritmetice câte un anumit număr raţional; din mulţimea celor 7680 de expresii generate ca mai sus (prin arithExpr()), vrem să extragem subsetul maximal pe care este injectivă restricţia corespunzătoare a funcţiei de evaluare. Dar nu ne putem baza pe ceea ce avem în mod obişnuit ca valoare numerică; de exemplu, pentru valori ca 0.(5), sau 0.0(5), sau -34/35, sau 1/24 şi destule altele - putem întâlni reprezentări numerice diferite:
"((4/3)-1)/6" 0.0555555555555555 "1/18" "1/((3*4)+6)" 0.0555555555555556 "1/18" # afişare (reprezentare?) cu rotunjire în sus "((6/5)-8)/7" -0.971428571428571 "-34/35" "((8/7)-6)/5" -0.971428571428572 "-34/35" "(7/8)-(5/6)" 0.0416666666666666 "1/24" "(7-5)/(6*8)" 0.0416666666666667 "1/24"
Pentru a obţine fracţia raţională (ca mai sus, "1/18") corespunzătoare unei reprezentări numerice obişnuite putem folosi funcţia MASS::fractions(). Următoarea funcţie primeşte ca argument vectorul celor 4 operanzi şi apelează arithExpr(), obţinând vectorul celor 7680 de expresii aritmetice; apoi, transformă vectorul expresiilor într-o structură 'data.frame', căreia îi adaugă coloana valorilor expresiilor (folosind o construcţie cu funcţiile parse() şi eval()) şi coloana reprezentărilor fracţionare ale valorilor respective; apoi, prin funcţia table() se obţine un tabel al frecvenţelor acestor fracţii, se marchează fracţiile întâlnite câte o singură dată şi se returnează subsetul expresiilor corespunzătoare acestei ultime situaţii, ordonându-l după coloana valorilor:
De exemplu, subsetul injectiv al operanzilor 1,2,3,5 conţine 11 expresii:
> print(exprInj( c(1, 2, 3, 5) ), row.names=FALSE) expr value fract expr value fract ((1-2)/5)-3 -3.2000000 -16/5 (1/5)-(2/3) -0.4666667 -7/15 ((2-1)/5)-3 -2.8000000 -14/5 2/((1/3)-5) -0.4285714 -3/7 (3/(1-5))-2 -2.7500000 -11/4 1/((2/5)-3) -0.3846154 -5/13 (1/3)-(5/2) -2.1666667 -13/6 1/((2/3)-5) -0.2307692 -3/13 (1/5)-(3/2) -1.3000000 -13/10 1/(5-(2/3)) 0.2307692 3/13 (1/2)-(5/3) -1.1666667 -7/6
Procedând acum cam la fel ca în [1] (partea a II-a), construim structura de date 'solo' conţinând unul după altul subseturile injective corespunzătoare submulţimilor de câte 4 operanzi luaţi din mulţimea cifrelor zecimale 1..9:
Execuţia acestei ultime secvenţe durează cam un minut, iar 'solo' conţine:
> str(solo) 'data.frame': 8633 obs. of 5 variables: $ operands: Factor w/ 126 levels "1234","1235",..: 126 126 126 126 ... $ expr : chr "9/(6-(7/8))" "8/(7-(9/6))" "7/(6-(9/8))" "7/(6-(8/9))" ... $ value : num 1.76 1.45 1.44 1.37 1.32 ... $ fract : chr "72/41" "16/11" "56/39" "63/46" ... $ frq : int 122 122 122 122 122 122 122 122 122 122 ...
În [1] (partea a II-a) obţinusem 8723 de "expresii injective" (nu 8633, ca acum); diferenţa de 90 de expresii faţă de ceea ce am obţinut acum are drept cauză faptul că în [1] ne bazam - dar greşit, cum am arătat deja mai sus - pe valoarea numerică a expresiei.
Variabila suplimentară 'frq' indică numărul de expresii pentru fiecare subset injectiv înglobat în 'solo' şi - prin funcţia transform() (plus reorder() şi rank()) - o folosim pentru a asigura unor reprezentări grafice parcurgerea subseturilor indicate de factorul 'operands' în ordinea mărimilor acestora:
solo <- transform(solo, operands=reorder(operands, rank(frq)))
Acum putem obţine statistici principale pentru subseturile înglobate în solo folosind:
De exemplu, subsetul injectiv corespunzător operanzilor "1235" conţine 11 expresii; valoarea mediană a valorilor numerice ale acestora este Q2=-1.1(6), iar 50% dintre valori sunt cuprinse în intervalul [Q1, Q3] (vezi help(boxplot)):
Dar bineînţeles că preferăm să vizualizăm grafic repartiţia valorilor expresiilor (în loc de a lista statisticile respective, cum am exemplificat mai sus pentru subsetul "1235"):
Am specificat outline=FALSE pentru a evita să mai încorporăm pe grafic şi punctele "extreme" - acele valori care sunt mai mici decât Q1 - 1.5*IQR sau care sunt mai mari decât Q3 + 1.5*IQR (unde IQR = Q3 - Q1); cu abline() şi text() am trasat şi am notat nişte linii orizontale de ghidare (de la -16 la 6, din 2 în 2), iar cu par() am specificat las=2 pentru înscrierea pe verticală, a etichetelor ("1235", "1234" etc. - la baza graficului; click-dreapta şi "View Image", pentru a mări imaginea):
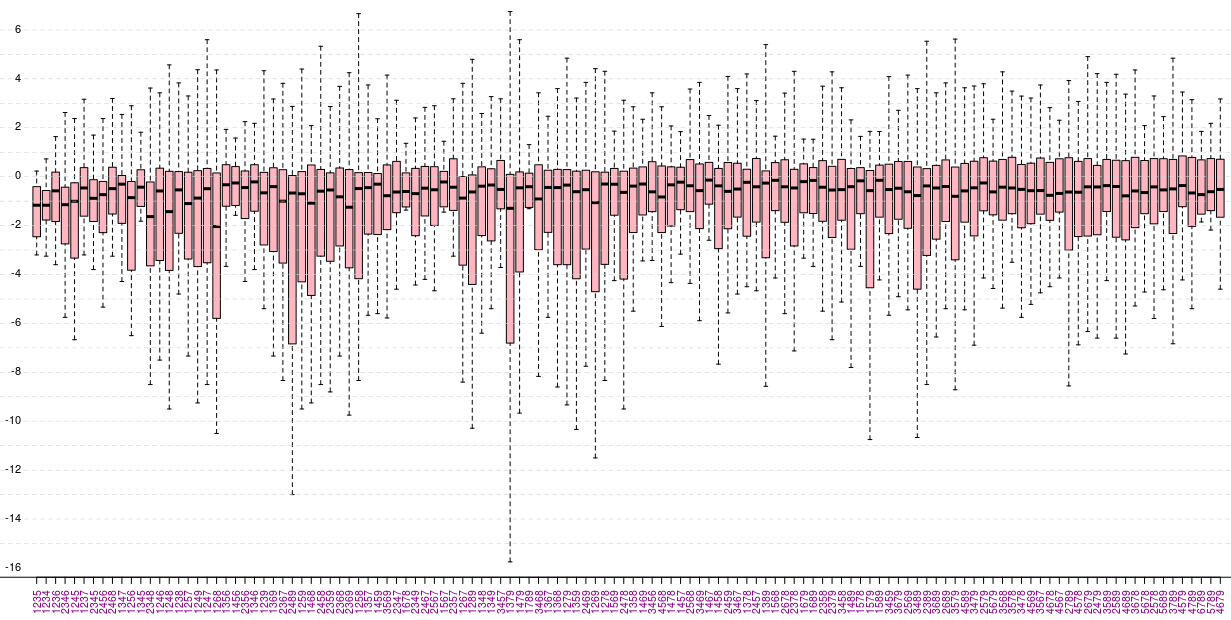
Nu-i vorba să deducem de pe grafic cum că valorile se grupează majoritar undeva între -3 şi puţin peste 0 - aşa ceva putem constata direct, mai simplu şi mai precis decât "citind" graficul:
Meritul reprezentării grafice (pe lângă conturarea eventuală a tendinţei lucrurilor) ar putea fi acela de a evidenţia situaţiile speciale, care altfel sunt greu de depistat. În cazul nostru, "sare în ochi" întâi subsetul etichetat cu "1379" - care pe grafic are cea mai mare amplitudine verticală, cuprinzând valori între aproximativ -16 şi 7; desigur că acum - odată semnalat ca fiind interesant - putem obţine informaţii mai precise, procedând ca şi la cazul "1235" de mai sus:
Subsetul "2489" are aproape aceleaşi quartile ca "1379" (mediana fiind totuşi ceva mai sus), dar pe o amplitudine ceva mai redusă (undeva între -13 şi 3). Putem sesiza pe grafic alte câteva proprietăţi ale subseturilor injective; însă şi cu şi fără mijlocire grafică - nu avem la îndemână vreo caracterizare semnificativă a valorilor respective.
Restricţia injectivă maximală a evaluării subseturilor injective
Câte şi care sunt expresiile ale căror valori se întâlnesc câte o singură dată în coloana 'solo$fract'? Cu alte cuvinte, vrem să evidenţiem restricţia injectivă maximală a funcţiei de evaluare pentru setul de 8633 expresii 'solo', obţinut mai sus.
Stabilim frecvenţa valorilor şi extragem (prin funcţia subset(), în 'kern') liniile de date corespunzătoare frecvenţei 1; apoi, recreem coloana 'operands' plecând de la coloana 'expr' - cu gsub(), apoi strsplit() şi sort() se extrag, se separă şi se ordonează cifrele din expresia curentă, apoi cu paste0() se realipesc şi în final se înscrie eticheta rezultată pe locul curent din vectorul kern$operands; în final, instituim coloana 'kern$frq' cu valori corespunzătoare frecvenţei operanzilor tocmai creaţi şi o folosim imediat în transform() pentru a reordona 'kern' după aceste frecvenţe:
'kern' conţine 995 dintre cele 8633 de expresii din 'solo', acoperind numai 97 categorii de operanzi (dintre cele 126 existente iniţial); expresiile din 'solo' corespunzătoare operanzilor '1234' (şi la fel în alte 29 de cazuri, '1235'..'1238', '1245'..'1248', '1256', etc.) apăreau fiecare şi la alte subseturi injective alipite în 'solo', încât ele au fost ignorate în cursul extragerii din 'solo' în 'kern' a acelora de frecvenţă 1.
Am obţinut graficul următor, adaptând comanda boxplot() pe care am folosit-o (vezi mai sus) în cazul setului de date 'solo' şi completând prin funcţia legend() cu o "legendă" conţinând rezultatul întors de comanda summary(kern$value):
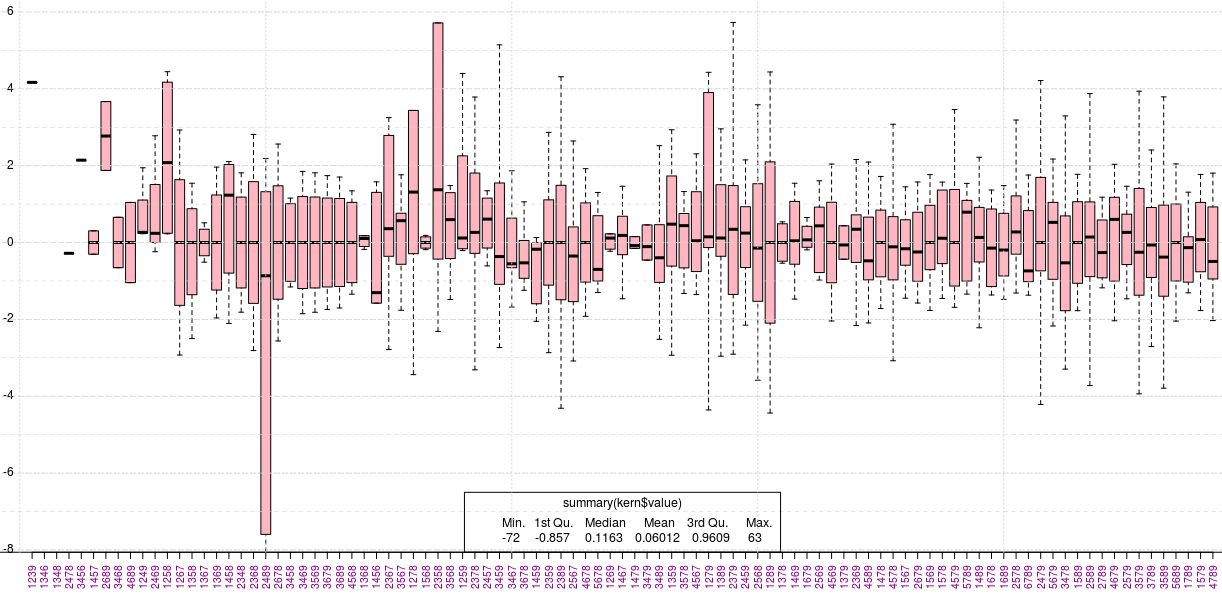
Cele 97 de boxplot-uri apar în ordinea dată de rank(frq) (prin reordonarea întreprinsă în finalul secvenţei de comenzi redate mai sus), începând cu următoarele 5 seturi de operanzi (pentru care 'frq' este 1):
Privind graficul în ansamblu, am putea spune că "variabilitatea" cea mai mare o are setul etichetat cu "2489" (cu boxplot-ul cel mai amplu, dintre toate); de fapt putem vedea uşor că este vorba de numai 4 expresii, cu valoarea minimă -13 (omisă pe grafic) şi cu mediana apropiată de -1:
Un aspect interesant pe care îl sugerează graficul redat mai sus vizează simetria faţă de zero a valorilor. De exemplu, pentru "2678" avem valorile -41/16 şi -16/41, iar apoi simetric: 16/41 şi respectiv 41/16; analog avem pentru fiecare dintre următoarele şase boxplot-uri (de la dreapta lui "2678") şi pe grafic este vizibil că "regula" simetriei faţă de zero a boxplot-urilor se respectă - cu câteva excepţii sau imperfecţiuni - până la capătul din dreapta.
vezi Cărţile mele (de programare)