Grila coeficienţilor - introducere practică în XML şi XSLT
De obicei, în programele de prelucrare - aici o să vizăm aplicaţii de salarizare - avem nevoie de date, fără informaţii de context explicite. Dar - de exemplu, pentru actualizarea periodică a unor valori de configurare - este util să dispunem în cadrul aplicaţiei şi de posibilitatea reprezentării explicite (descriptiv şi asociativ) a datelor respective; în acest scop putem folosi limbajul XML (ridicând probleme de conversie, între "array" şi "document XML"), iar pentru prezentarea datelor XML - limbajul XSLT.
Contextul problemelor tratate
Pentru salarizarea personalului din sistemul bugetar, guvernul stabileşte periodic (se zicea şi se credea că anual) valoarea coeficientului de multiplicare 1.000, împreună cu tabelele cuprinzând coeficienţii de multiplicare (a valorii de referinţă) pentru diversele categorii de "bugetari".
Aplicaţiile de salarizare se bazează pe aceste tabele şi trebuie să şi le actualizeze când apar modificări de coeficienţi; de obicei ele folosesc baze de date, inclusiv pentru coeficienţii respectivi, sau folosesc fişiere de configurare (fişiere text de un anumit format, care sunt citite corespunzător formatului respectiv la iniţializarea aplicaţiei).
Din păcate, de obicei instituţiile nu oferă tabelele de coeficienţi într-un format care să permită reutilizarea datelor respective: dacă de exemplu, s-ar oferi spre download nişte spreadsheet-uri Excel conţinând coeficienţii, atunci înregistrarea noilor coeficienţi în baza de date a aplicaţiei (sau în fişierele de configurare) ar fi un act elementar; însă tabelele respective sunt tipărite în Monitorul Oficial, sau cel mult sunt oferite prin Internet în facsimil (imagine grafică a paginilor din Monitor) - astfel că devine obligatorie înscrierea manuală a coeficienţilor.
Desigur, se poate întâmpla "să găseşti la alţii": careva a înregistrat coeficienţii şi apoi a postat tabelele undeva pe Internet, într-un format care permite şi altora să preia şi să refolosească datele; zici "Mulţumesc!" persoanei respective, preiei datele şi-ţi actualizezi tabelele… Dar mai degrabă găseşti pe Internet obiecte legate chipurile de tabelele necesare, dar care sunt jenante dacă te gândeşti la scopul pe care-l au coeficienţii de salarizare: am găsit anul trecut, undeva pe la un Inspectorat Şcolar (Bucureşti) un film de vreo 10-20 MB, care-ţi arăta poze şi îţi cânta salariile de încadrare actuale!
Prin urmare, trebuie pregătite nişte instrumente care să-ţi permită să editezi cât mai simplu coeficienţii respectivi, în vederea reactualizării tabelelor sau fişierelor aplicaţiei de salarizare. Vom prezenta aici o metodă de lucru, pe care o şi folosim în practică pe "http://salar.sitsco.com".
Definirea termenilor
Termenii specifici se pot citi pe următoarea imagine, rezultată dintr-un fişier .DOC găsit pe site-ul Inspectoratului Şcolar:
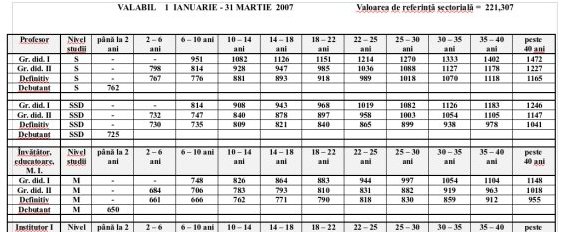
Pe acest tabel citim de exemplu, că pentru categoria [Profesor / grad="I" / studii="S" / vechime="30-35 ani"] corespundea (între timp, valoarea de referinţă s-a modificat) un salariu de încadrare de 1333.
Nu sunt indicaţi şi coeficienţii pe baza cărora s-au calculat salariile de încadrare (după formula: coeficient * valoarea de referinţă), încât datele respective pot fi utilizate numai în cazul în care aplicaţia de salarizare s-ar baza direct pe salariile de încadrare şi nu pe coeficienţi (e drept, coeficientul se poate determina - raportând salariul la valoarea de referinţă; dar aceasta ar fi în multe cazuri incorect, ca urmare a regulilor de rotunjire practicate).
Fiind vorba de un fişier "DOC" (desigur, cu "Microsoft Office Word"), nu poate fi vorba de a calcula salariile de încadrare: cu siguranţă, după ce s-a folosit meniul sau iconiţa Word-ului pentru "Table", cineva calcula salariul de încadrare pe binecunoscutul calculator de birou şi dicta rezultatul altcuiva, să-l înscrie în tabelul Word respectiv…
Prin urmare, avem de-a face cu o structură de date ierarhizată pe mai multe nivele, în care nodurile terminale reprezintă coeficienţii (sau salariile de încadrare, în cazul redat mai sus); o schemă de definire a acesteia este redată în diagrama următoare:
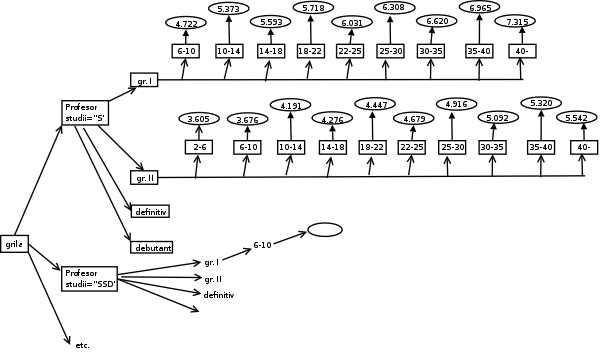
Aici 'grila' este rădăcina întregului arbore; pe calea 'grila' / 'Profesor'[studii='S'] / 'gr. I' / '30-35' obţinem coeficientul '6.620'. Înmulţindu-l cu valoarea de referinţă actuală (= 225.733) şi rotunjind (după regulile oficiale ale momentului), găsim salariul de încadrare.
Avem prevăzute şase categorii de personal didactic în învăţământul preuniversitar: 'Profesor', 'Institutor' (ambele cu 'Nivelul studiilor' fie 'S' fie 'SSD'), 'Învăţător, educatoare, educator, maistru-instructor' cu 'Nivelul studiilor' de valoare 'M' - care au fiecare, cele patru variante de 'grad' (pe diagramă 'gr. I', 'gr. II', 'definitiv' şi 'debutant'); numai a şasea categorie 'Profesor, învăţător, maistru-instructor, cu studii de nivel liceal, fără pregătire de specialitate' nu prevede variante de 'grad', ci subordonează direct cele 11 tranşe de vechime (de la '0-2 ani', '2-6 ani',..., până la 'peste 40 ani').

Figura alăturată descrie reprezentarea în XML a arborelui desenat mai sus (ea este un screenshot de pe prezentarea structurii documentului "grila.xml" de către browserul Amaya).
grila este elementul rădăcină a documentului şi el subordonează mai multe elemente coefi, având următoarea definiţie XML:
<!ELEMENT grila ( coefi+ )>
Fiecare element coefi are un atribut propriu obligatoriu (REQUIRED), denumit functie (cu valorile posibile "Profesor", "Institutor I", etc.) şi este constituit din mai multe grupuri {stu, mai multe gra} conform următoarei definiţii XML:
<!ELEMENT coefi ( stu, gra+ )+> <!ATTLIST coefi functie CDATA #REQUIRED>
Nu am fixat valorile atributului functie, ci am cerut doar să aibă tipul CDATA (secvenţă de caractere); astfel, vor putea fi adăugate eventual şi alte funcţii.
Fiecare stu are atributul obligatoriu studii şi are doar rolul de a grupa elemente gra (nu are "conţinut" propriu!):
<!ELEMENT stu EMPTY>
<!ATTLIST stu studii CDATA #REQUIRED>
Fiecare gra are atributul opţional grad şi grupează tranşele de vechime:
<!ELEMENT gra (vec+)>
<!ATTLIST gra grad CDATA #IMPLIED>
În sfârşit, fiecare coeficient este înregistrat (ca valoare de tip PCDATA) într-un element vec care are ca atribut tranşa de vechime respectivă:
<!ELEMENT vec (#PCDATA)>
<!ATTLIST vec tr CDATA #REQUIRED>
În coloana stângă se văd datele care fac obiectul documentului XML, câte un număr pe linie; coloana de coeficienţi respectivă nu are nici o structurare explicită, dar ordinea valorilor este aceeaşi cu ordinea lor în cadrul documentului XML. Va fi nevoie şi de un program care să convertească o asemenea coloană de valori (în orice caz, un fişier text nestructurat în mod explicit prin markup) într-un document XML care să respecte regulile de definiţie şi termenii descrişi mai sus.
Reunind aceste definiţii, avem toate regulile care vor trebui respectate pentru ca documentul XML să fie corect (well-formed); partea din documentul XML care prevede aceste reguli se numeşte DTD (Document Type Definition) şi se declară folosind <!DOCTYPE, astfel:
<!DOCTYPE grila [ <!ELEMENT grila ( coefi+ )> <!ELEMENT coefi (stu, gra+)+> <!ATTLIST coefi functie CDATA #REQUIRED> <!ELEMENT stu EMPTY> <!ATTLIST stu studii CDATA #REQUIRED> <!ELEMENT gra (vec+)> <!ATTLIST gra grad CDATA #IMPLIED> <!ELEMENT vec (#PCDATA)> <!ATTLIST vec tr CDATA #REQUIRED> ]>
Obs. În termenii "teoriei mulţimilor" am putea exprima DTD-ul de mai sus astfel: 'grila' (elementul 'root' al documentului) este o mulţime nevidă, ale cărei elemente sunt mulţimile 'coefi'; o mulţime 'coefi' are ca elemente un 'stu' şi cel puţin o mulţime 'gra', unde 'gra' are ca element tabloul coeficienţilor.
Conversii de text
Datele "brute" (vezi coloana coeficienţilor în figura de mai sus) nu au nici o relevanţă semantică (decât eventual de nivel implicit, girat de ordinea în care apar; poate doar cel care le-a înscris, să ştie şi "ce-i cu ele", care este semnificaţia lor); limbajul XML asigură memorarea descriptivă şi asociativă a datelor, implicând aspectele structurale şi semantice corespunzătoare lor.
Documentul XML conţine datele respective, marcate corespunzător prin termenii din DTD; astfel, corespunzător imaginii de mai sus:
<grila> <coefi functie="Profesor-S"> <stu studii="Superioare"> <gra grad="I"> <vec tr="0-2"></vec> <vec tr="2-6"></vec> <vec tr="6-10">4.722</vec> <vec tr="10-14">5.373</vec> <vec tr="14-18">5.593</vec> <vec tr="18-22">5.718</vec> <vec tr="22-25">6.031</vec> <vec tr="25-30">6.308</vec> <vec tr="30-35">6.620</vec> <vec tr="35-40">6.965</vec> <vec tr="40-">7.315</vec> </gra>
Observaţie. Iniţial (vezi mai sus, reproducerea de sub amaya) considerasem că "Profesor / studii=S" şi "Profesor / studii=SSD" sunt ambele, categorii subordonate aceluiaşi element <coefi functie="Profesor">. Dar pe parcurs am sesizat că procedând astfel, va trebui uneori să tratăm primele două categorii (Profesor-S şi Profesor-SSD) în mod diferit faţă de celelalte ("Institutor I" este un element <coefi> independent; la fel "Institutor II", etc.). Prin urmare, în scopul de a permite o tratare unitară a celor 6 categorii, am revenit şi am separat elementele <coefi functie="Profesor-S"> şi <coefi functie="Profesor-SSD"> (ceea ce nu a necesitat nici o modificare în DTD).
Cum am explicat deja, coeficienţii de multiplicare sunt necesari în aplicaţiile de salarizare. Pentru calculele specifice, o aplicaţie de salarizare are nevoie de valorile coeficienţilor (deci de un tabel în sensul obişnuit în programare, array), nu are nevoie de vreo formă de prezentare (tabel, etc.) a acestora; pe de altă parte însă, aplicaţia respectivă trebuie şi întreţinută (de exemplu, actualizând coeficienţii când este cazul), iar în acest scop este util pentru cel care o întreţine să-şi pună la dispoziţie şi o formă/instrument de vizualizare/editare a tabelului coeficienţilor. Mai mult, chiar şi celor care exploatează aplicaţia poate să le fie util să vadă/verifice tabelul coeficienţilor pe baza căruia se calculează salariile.
Extragerea datelor dintr-un document XML
Să presupunem că avem un document XML grila.xml, corespunzător coeficienţilor - deschideţi-l şi uitaţi-vă pe "sursă" (folosind meniul View al browserului, sau CTRL+U). Pentru a extrage coeficienţii din "grila.xml" putem folosi modulul perl XML::Twig, astfel:
#!/usr/bin/perl -w use strict; use XML::Twig; open(FH, ">", "grila-t.txt"); my $tw = new XML::Twig ( twig_handlers => { stu => sub { print FH "\n"; }, gra => sub { print FH "\n"; }, vec => sub { print FH $_->text || 0, "\t"; } } ); $tw->parsefile( "grila.xml");
Constructorul obiectului $tw asociază elementelor XML 'stu', 'gra' şi 'vec' câte o subrutină anonimă; prin invocarea metodei $tw->parsefile(), se traversează "grila.xml" şi atunci când se întâlneşte unul dintre aceste trei elemente, se şi execută "handlerul" asociat. Aceste subrutine asigură scrierea în fişierul-text grila.txt a coeficienţilor din 'vec' (separaţi pe linie prin '\t'), avansând pe linia următoare în cazul întâlnirii unui element 'stu' sau 'gra'.
Este uşor de modificat valorile din "grila.txt", dacă este cazul; odată actualizat, "grila.txt" poate fi imediat inclus în fişierul de configurare, încât aplicaţia va putea folosi noii coeficienţi. Pentru a permite acelaşi procedeu şi în cazul viitoarei reactualizări, mai rămâne să înregistrăm noii coeficienţi şi pe "grila.xml" (desigur, nu manual…).
Actualizarea datelor pe documentul XML
Presupunem că "grila.txt" conţine valorile acualizate ale coeficienţilor; pentru a le înscrie pe "grila.xml" (înlocuind vechii coeficienţi existenţi), putem folosi din nou XML::Twig:
#!/usr/bin/perl -w use strict; use XML::Twig; open(FH, "<", "grila.txt"); # după actualizarea coeficienţilor my @coef; # va înregistra coeficienţii liniar, în aceeaşi ordine ca în XML foreach my $cf (<FH>) { # $cf este şirul coeficienţilor de pe linia curentă chomp $cf; # elimină terminatorul de linie '\n', cuprins şi el în şir my @q = split /\s+/, $cf; # tabloul coeficienţilor de pe linia curentă push @coef, @q; # adaugă aceşti coeficienţi în tabloul liniar @coef } =head variabilele locale $cf şi @q sunt inutile, fiindcă se putea formula mai bine, aşa: while (<FH>) { # implică variabila specială $_ în loc de "my $cf" chomp; # toate operaţiile care n-au argument, se fac asupra $_ push @coef, ( split /\s+/ ); # desparte şirul din $_ la "spaţiu" şi adaugă } # lista de coeficienţi rezultată =cut my $i = 0; # va referi coeficientul curent din tabloul @coef my $tw= new XML::Twig ( twig_handlers => { vec => sub { $_->set_text($coef[$i++]); } } ); $tw->parsefile( "grila.xml"); $tw->print_to_file("grila.xml");
element->set_text($coef[$i++]) are ca efect înscrierea coeficientului al $i-lea din tabloul liniar @coef, drept conţinut al elementului vec curent (iar $i este avansat pentru a referi următorul coeficient, destinat următorului element vec din arborele XML).
Prezentarea datelor (XSLT)
Deschizând grila.xml, vedeţi că datele sunt prezentate sub forma a şase diviziuni (bordate); fiecare diviziune conţine tabelul coeficienţilor uneia dintre cele şase categorii de funcţii. Dacă vizualizaţi sursa paginii (cu CTRL+U în Firefox; sau prin meniul View/Page Source), nu veţi vedea decât documentul XML (DTD şi elementele constitutive) - nu şi elementele HTML (precum <div>, <table>, etc.) implicate pentru prezentarea cu diviziuni, tabele, etc. Însă observaţi la începutul sursei, rândul:
<?xml-stylesheet type="text/xsl" href="grila.xsl"?>
Această instrucţiune de procesare este destinată browserului: când va încărca "grila.xml", va încărca şi programul "grila.xsl" (menţionat prin atributul href în instrucţiune) şi acesta va fi pus imediat în execuţie; programul ".xsl" operează asupra documentului ".xml" şi-l transformă într-o formă de prezentare sau alta (de exemplu, în HTML) - pe care în final, o va "afişa" browserul.
Programul ".xsl" este scris în limbajul XSLT ("T" de la "transform") şi este executat de către procesorul XSLT încorporat în browser. XSLT diferă de limbajele de programare "obişnuite"; în limbajele procedurale execuţia programului decurge conform specificaţiilor explicite conţinute în program: do this, then this, then this; XSLT este un limbaj funcţional: ordinea execuţiei instrucţiunilor nu mai este descrisă în mod explicit, de către programul respectiv.
Procesorul XSLT vede datele XML sub forma unui arbore; elementele din documentul XML şi atributele acestora devin noduri în acest arbore. Un program XSLT reprezintă o asociere între nodurile arborelui XML şi nişte funcţii de transformare a nodurilor respective; procesorul XSLT "execută" acest program prin următorul mecanism: după ce s-a constituit arborele de intrare corespunzător documentului XML, se realizează o parcurgere în adâncime a acestui arbore (procesorul vizitează toţi fiii unui nod, recursiv, începând de la rădăcina arborelui, până la epuizarea nodurilor) şi asupra fiecărui nod vizitat se aplică funcţia de transformare menţionată în program pentru acea categorie de nod; fiecare funcţie de transformare arată procesorului cum să creeze eventual noi noduri în arborele de ieşire (corespunzător transformării documentului iniţial); la terminarea parcurgerii, procesorul a constituit un arbore de ieşire final pe care îl serializează şi îl returnează astfel drept răspuns final (în formă HTML, sau text, sau XML după cum s-a optat în program - de exemplu <xsl:output method="html"/>).
O "funcţie" de transformare a nodurilor este deci, un şablon (sau template) de modificări care vor trebui aplicate oricărui nod din categoria de noduri precizată, atunci când acel nod este vizitat de către procesorul XSLT; sintaxa corespunzătoare este:
<xsl:template
name = "nume_apel_functie"
match = "criteriu_selecţie_Listă_Noduri">
<!-- "corpul funcţiei:" -->
apelează (recursiv) funcţii de transformare asupra "Listă_Noduri",
sau specifică direct transformările de aplicat nodurilor
</xsl:template> <!-- marchează sfârşitul funcţiei -->
Desigur, având prevăzut un "name" -funcţia va putea fi apelată din cadrul altor "şabloane".
Redăm aici (incluzând comentarii explicative) programul grila.xsl conceput pentru a produce forma de prezentare descrisă mai sus.
<?xml version="1.0" encoding="utf-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output method="html"/> <!-- creează variabila globală "valref" = valoarea de referinţă --> <xsl:variable name="valref" select = "225.733"/> <!-- aplică pe rădăcina ("/") arborelui XML (elementul 'grila') transformarea: --> <xsl:template match="/"> <!-- inserează în arborele de ieşire elementele <html>, <body>, <h1>, <p>: --> <html><body> <h1 style="text-align:center;">Coeficienţi-grilă şi Salarii-încadrare</h1> <p style="text-align:center;"> valoarea de referinţă = <b><xsl:value-of select="$valref"/></b> </p> <!-- aplică recursiv şabloanele corespunzătoare nodurilor ('coefi', etc.): --> <xsl:apply-templates/> </body></html> </xsl:template> <!-- aplică oricărui nod 'coefi' transformarea: --> <xsl:template match='coefi'> <!-- inserează în arborele de ieşire, ca "parent" al nodului 'coefi' curent: --> <div style="margin:5px;padding:10px;border:1px dotted blue;font-size:1em;"> <h2 style="color:blue;"> <!-- înscrie valoarea atributului "functie" din elementul 'coefi' --> <xsl:value-of select="@functie"/> </h2> <!-- aplică recursiv şabloanele aferente nodurilor subordonate ('stu', 'gra') --> <xsl:apply-templates/> </div> </xsl:template> <!-- aplică oricărui nod 'stu' transformarea: --> <xsl:template match="stu"> studii: <span style="color:blue;font-weight:bold;"><xsl:value-of select="@studii"/></span> <table border="2" cellspacing="2" cellpadding="2" style="font-family:monospaced;font-size:0.9em;"> <xsl:if test="./gra[@grad]"> <tr style="background:#eee;"><th>Grad</th> <xsl:for-each select="./gra[@grad='I']/vec"> <th><xsl:value-of select="@tr"/></th> </xsl:for-each> </tr> </xsl:if> <!-- s-a inserat un element <table>; apoi, aplică recursiv şabloanele pe descendenţii lui 'stu': --> <xsl:apply-templates/> </table><br/> </xsl:template> <!-- aplică oricărui nod 'gra' care are atributul "grad", transformarea: --> <xsl:template match="gra[@grad]"> <!-- pentru valoarea curentă a atributului "grad", se inserează un <tr> având ca <td>-uri coeficienţii corespunzători tranşelor de vechime --> <tr><td><b><xsl:value-of select="@grad"/></b></td> <xsl:for-each select="./vec"> <td> <xsl:variable name="coef" select="."/> <xsl:value-of select="$coef"/> <!-- calculează şi adaugă "salariul de încadrare" corespunzător --> <xsl:if test="$coef>0"> <b><xsl:number value="round($valref*$coef)" format=" "/></b> </xsl:if> </td> </xsl:for-each> </tr> </xsl:template> <!-- pentru nodurile 'gra' care NU au atributul "grad": --> <xsl:template match="gra[not(@grad)]"> <tr style="background:#eee;"><xsl:for-each select="./vec"> <th><xsl:value-of select="@tr"/></th></xsl:for-each></tr> <tr> <xsl:for-each select="./vec"> <td> <xsl:variable name="coef" select="."/> <xsl:value-of select="$coef"/> <b><xsl:number value="round($valref*$coef)" format=" "/></b> </td> </xsl:for-each> </tr> </xsl:template> </xsl:stylesheet>
Bibliografie
[http://www.w3.org/TR/xslt] (specificaţia XSLT)
[http://www.w3.org/TR/xpath] (specificaţia XPath)
[How Not to Use XSLT] by R. Alexander Milowski, berkeley.edu
[XML Journal] (articole XML, XSLT)
vezi Cărţile mele (de programare)