Investigarea unor fişiere PDF
În [1] am iniţiat un "site utilitar" - referit mai departe cu //bacmath - pentru a simplifica munca de pregătire a examenului de bacalaureat la proba "matematică"; în principal, se "arată" în browser problemele de la varianta, subiectul, sau tipul precizate de către utilizator.
Dificultatea realizării practice a //bacmath provine din următorul fapt: PDF nu poate reprezenta o formulă matematică decât ca "obiect grafic", iar noi vrem o reprezentare textuală; este ca şi cum ai vrea numele persoanei a cărei poză îţi apare pe ecran (vom arăta mai jos că pentru PDF-urile pe care le-am putea folosi în cazul de faţă - chiar aşa stau lucrurile).
Iniţial, avem fişiere PDF (cu seturi de subiecte de bacalaureat) descărcate de pe diverse site-uri de tip "furnizor de documente" (google bac variante matematica 2009); putem constata că aceste PDF-uri sau provin din documente Microsoft Word, sau sunt rezultatul scanării de pagini tipărite - aşa că recuperarea inversă (a "formulelor" ale căror "poze" apar pe ecran) aproape că nu are nici o şansă (mai ales că lipseşte fişierul ".doc" în care s-au editat iniţial, expresiile matematice respective).
Aceasta înseamnă că este inevitabilă această muncă: citeşte textul problemei din PDF şi scrie-l în format text uzual (folosind pentru expresiile matematice limbajul LaTeX); când termini de scris astfel toate cele 10 probleme din acea variantă - salvează textul în baza de date //bacmath.
Editarea problemelor, citindu-le din fişierul PDF
Utilizatorul căruia i-am creat un cont corespunzător pe //bacmath, va putea să înscrie în baza de date noi variante. Fiind vorba în special de cele 100 de variante "oficiale", imaginăm următoarea interfaţă (menită să facă mai comodă munca de editare necesară):
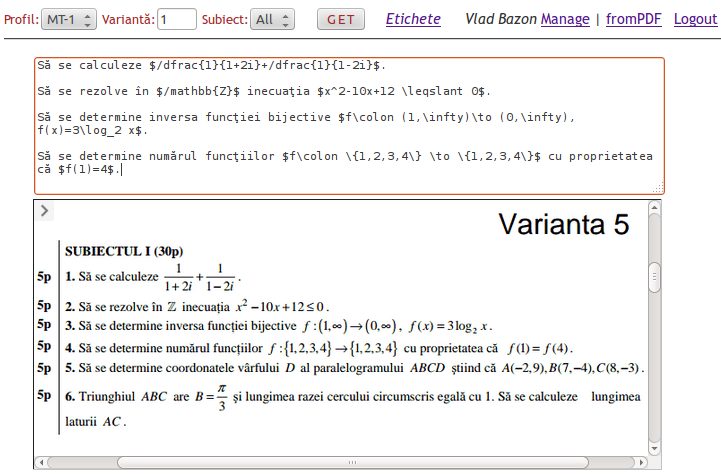
Odată autentificat, utilizatorul dispune de acţiunile "Manage" şi "fromPDF" (şi desigur, de "Logout"). Click "fromPDF" aduce în browser casetele reproduse mai sus, reprezentând respectiv un element <textarea> în care utilizatorul va putea tasta textul problemelor şi un element <iframe>, în care s-a transferat fişierul PDF (derulat pe imaginea de mai sus la "Varianta 5").
Astfel, problemele pot fi citite din PDF (fără operaţii suplimentare, de deschidere sau comutare de ferestre) şi scrise în acelaşi timp în <textarea> (folosind eventual şi Copy&Paste, pentru porţiunile de text); cum se vede pe imagine, problemele se scriu una sub alta - fără numerotare şi fără marcare cu punctajul "5p" - lăsând un rând liber între ele.
La sfârşit, utilizatorul poate acţiona "Save" (omis pe imaginea de mai sus) - declanşând o funcţie //bacmath care în principal, preia conţinutul <textarea> şi înscrie problemele în baza de date.
După această operaţie de salvare, utilizatorul poate folosi formularul "de bază" (indicând "Varianta: 5", "Subiect: All" şi click "GET" - vezi imaginea) pentru a aduce în browserul său varianta tocmai înscrisă. Deasemenea, poate folosi "Manage" - accesând interfaţa "de bază" pentru administrarea bazei de date; aici el va putea să corecteze eventualele greşeli şi va putea să asocieze problemele respective cu anumite etichete.
Pentru scrierea formulelor matematice cu LaTeX, utilizatorul poate consulta de exemplu LaTeX Cookbook (deschizându-l într-un "Tab" al browserului alăturat celui în care se editează //bacmath). Iar dacă utilizatorul preferă totuşi să creeze formulele folosind "point-and-click" (la fel ca în Microsoft Word), el poate folosi de exemplu aplicaţia LaTeX Equation Editor.
Experimente şi operaţii utile asupra fişierelor PDF
Este evident că trebuie exclusă posibilitatea ca utilizatorul să înscrie o variantă care deja există în baza de date. Pentru aceasta, cel mai sigur procedeu constă în a-i oferi în caseta pentru PDF numai una (la alegere) dintre variantele neînregistrate la momentul curent - adică numai una anumită, dintre cele 100 de pagini ale PDF-ului.
Prin urmare, se pune problema separării prealabile a fiecărei pagini din PDF-ul iniţial - obţinând 100 de fişiere PDF (fiecare reprezentând câte una dintre variantele existente). În acest scop putem folosi fie pdftk, fie Ghostscript (sau diverse produse comerciale, pentru manipularea fişierelor PDF).
Şi dacă n-am observat anterior - acum este inevitabil să constatăm că nu este de loc indiferent care fişier PDF îl agreem, dintre cele (conţinând variantele care ne interesează) pe care le putem descărca de la diverse site-uri "furnizor de documente"! Unele sunt criptate (iar pdftk nu le poate exploata, dacă nu-i furnizăm şi parola respectivă), altele folosesc caractere dintr-un font neaccesibil (încât pdftk sau gs pot eşua); unele sunt "optimizate" (reducând lungimea), altele nu; etc.
Putem folosi programul utilitar pdfinfo, pentru a extrage informaţii din fişierul PDF:
vb@vb:~/bacmath/DOC$ pdfinfo Variante_Matematica_MT1_BAC_2009.pdf Title: Variante Matematica MT1 BAC 2009 Keywords: Author: Blader2k Creator: Acrobat PDFMaker 8.1 for Word Producer: Acrobat Distiller 8.1.0 (Windows) CreationDate: Mon Mar 16 16:28:54 2009 ModDate: Mon Mar 16 17:00:15 2009 Tagged: yes Pages: 100 Encrypted: yes (print:yes copy:no change:no addNotes:no) Page size: 595.22 x 842 pts (A4) File size: 5464992 bytes Optimized: no PDF version: 1.6
Putem elimina parola (setată de către "Author" la crearea fişierului) folosind Ghostscript:
gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=MT1_2009.pdf \ -c .setpdfwrite -f Variante_Matematica_MT1_BAC_2009.pdf
Sau altfel, putem apela "on-line" la freemypdf.com - cu deosebirea faţă de comanda reprodusă mai sus, că acolo (dacă vrem) putem şi dona nişte bănuţi; altfel, rezultatele sunt identice (cum ne arată pdfinfo). Fireşte - freemypdf.com foloseşte tot Ghostscript drept "Producer".
Mai departe, putem extrage o pagină (fie cea cu varianta 5) folosind pdftk astfel:
vb@vb:~/bacmath/DOC$ pdftk A=MT1_2009.pdf cat A5 output MT1_2009_v5.pdf
Confruntând pagina obţinută cu pagina respectivă din fişierul iniţial, putem vedea dacă nu cumva unele caractere au fost omise - caz în care putem încerca extragerea paginii cu Ghostscript:
vb@vb:~/bacmath/DOC$ gs -sDEVICE=pdfwrite -dNOPAUSE -dBATCH -dSAFER \
-dFirstPage=5 -dLastPage=5 -sOutputFile=MT1_2009_v5.gs.pdf \
MT1_2009.pdf
În orice caz, programul utilitar pdffonts ne listează informaţiile referitoare la fonturile folosite de PDF-ul respectiv şi rămâne eventual să vedem dacă şi cum am putea "completa" resursele de font conectate (în mod implicit) de către programul folosit pentru extragerea paginii. Dar o asemenea "completare" este o operaţie complicată; cel mai bine este să abandonăm PDF-ul respectiv şi să încercăm un fişier PDF (cu variantele care ne interesează) descărcat din altă parte.
Astfel, iniţial noi am folosit "bacM1mate2009_variante.pdf" descărcat mai demult (are PDF version 1.3) de la //didactic.ro, având peste 10 MB lungime; am renunţat să-l mai folosim, după ce am constatat că pagina extrasă cu pdftk măsoară tot 10MB (în plus, sunt omise anumite caractere).
Am găsit într-un final "var_imprimare_m1_bac2009.pdf", la //bacmatematica.ro - anume un PDF "optimizat"; am eliminat parola (prin comanda gs redată mai sus) şi astfel dimensiunea fişierului - redenumit "mt1_09.pdf" - s-a redus la 1.3 MB (de la 2.3 MB, iniţial). Obţinem cele 100 de fişiere PDF aferente variantelor conţinute de acest fişier folosind pdftk astfel:
vb@vb:~/bacmath/DOC/MT1/2009$ pdftk mt1_09.pdf burst output v_%d.pdf
Specificând operaţia "burst" pentru pdftk, se extrage fiecare pagină din PDF-ul iniţial, rezultând fişierele "v_1.pdf", "v_2.pdf", ..., "v100.pdf".
Cum de este aşa de scurt, fişierul PDF? Verificare…
Fişierul "optimizat" menţionat mai sus are cea mai mică lungime (iniţial, 2.3 MB); celelalte fişiere PDF (pentru variantele din 2009) care se pot descărca de pe diverse site-uri, au lungimea de cel puţin 5 MB. Tocmai din acest motiv, l-am şi preferat celorlate ("într-un final", cum ziceam mai sus).
Dar - şi tocmai "în final", din păcate - m-am întrebat şi eu: cum de este aşa de scurt, în raport cu celelalte care au "acelaşi" conţinut? Desigur - fiindcă este optimizat…
"Optimizarea" fişierului înseamnă multe lucruri pe care autorul documentului le poate face în scopul reducerii dimensiunii - cele mai "inocente" fiind eliminarea spaţiilor nerelevante şi o compresare acceptabilă a imaginilor. Desigur, motivul reducerii dimensiunii nu este neapărat acela că astfel "fişierul încape mai bine pe stick", cât faptul că astfel - PDF-ul respectiv va putea fi deschis şi vizualizat mult mai rapid.
Dar cea mai mare "optimizare" se obţine cu o măsură care nu mai este "inocentă". O proporţie foarte mare într-un fişier PDF (ca şi într-unul produs cu Microsoft Word) revine fonturilor încorporate în document. Autorul poate miza pe faptul că fonturile respective "există" şi pe calculatorul celui care va deschide documentul său, astfel că poate alege să nu le încorporeze în document - regula fiind că dacă fontul nu este disponibil, atunci el va putea fi substituit cu vreunul dintre fonturile existente.
Procedând astfel, rezultă un fişier PDF mult mai scurt; este dicutabil însă, dacă vizualizarea lui va fi sensibil mai rapidă: fonturile care n-au mai fost încorporate vor trebui căutate (eventual, substituite) şi încărcate şi acestea în memorie, de către "Document Viewer"-ul folosit pentru deschiderea fişierului.
Verificând cu pdffonts fişierul "mt1_09.pdf", am constatat că într-adevăr, există mai multe fonturi neîncorporate în fişier - ceea ce explică lungimea relativ mică a fişierului respectiv.
Dar oare, pdftk (în comanda de paginare redată mai sus) a găsit pe calculatorul meu resursele de font necesare? Dacă nu - pot eventual instala fonturile lipsă, pot reconfigura eventual pdftk ca să "vadă" şi aceste fonturi, etc.; dar în contextul de faţă nu-i vorba de "calculatorul meu" - PDF-ul respectiv va trebui vizualizat în browserul utilizatorului lui //bacmath.
Iată pentru probă, cum este vizualizat pe calculatorul meu PDF-ul "optimizat", descărcat de la //bacmatematica.ro şi derulat la "Varianta 15":

Se vede că enunţul problemei 2 este trunchiat; "Document Viewer"-ul de pe calculatorul meu n-a găsit resursele de font necesare pentru vizualizarea documentului.
Prin urmare, trebuie să renunţăm la PDF-ul optimizat "var_imprimare_m1_bac2009.pdf" de la //bacmatematica.ro; bineînţeles, am şters cele 100 de fişiere "v_*.pdf" obţinute mai sus şi am revenit la fişierul PDF de 5MB, neoptimizat, descris la început (Author: Blader2k).
Ce conţine de fapt, acest fişier PDF?
Din păcate (fără cunoştinţe suficiente despre "formatul PDF"), n-am reuşit să elimin "antetul" (mai mult decât inutil) care apare în acest fişier pe fiecare pagină:

Acest antet conţine text, dar nu este "text" (ci un "obiect grafic", sau o "imagine"); linia albă subţire care taie penultimul rând indică faptul că "textul" respectiv provine din scanarea unei pagini tipărite (căci numai la tipărire apare când şi când, o asemenea "tăietură albă" a rândului - din motive care ţin de starea imprimantei şi a consumabilelor aferente). Şi într-adevăr, programul utilitar pdftotext ne arată că fişierul respectiv conţine drept "text" propriu-zis doar "Blader2k@BiTT" (repetat pe fiecare pagină) şi "Varianta 1", "Varianta 2", ..., respectiv "Varianta 100".
pdfimages extrage imaginile existente într-un PDF, în câte un fişier .PBM (Portable Bitmap Format) (sau încă vreo două tipuri de "bitmap": .PPM, .PGM, etc.). Pentru cazul nostru, obţinem 1178 de fişiere, marea majoritate fiind de tip .PBM (în care fiecare bit indică un pixel monocrom - fie alb, fie negru) şi câteva fiind de tip .PPM (în care 1 pixel este reprezentat prin 24 de biţi, acoperind gama obişnuită de culori posibile). Redăm câteva "screenshot"-uri relevante de pe fişierele respective:



Toate cele 1178 de fişiere arată ca mai sus, reprezentând fiecare câte una dintre imaginile conţinute de PDF - adică practic, harta de biţi care va fi imprimată pe câte o porţiune de o anumită înălţime, a paginii curent tipărite; de fapt, pentru fiecare pagină din PDF, "hărţile de biţi" aferente înregistrează rezultatul scanării prealabile, porţiune cu porţiune, a unei pagini deja tipărite.
În cazul nostru (în contextul aplicaţiei //bacmath), dar chiar şi în general vorbind (în orice context) - textul obişnuit este infinit mai util (inclusiv pentru modelarea formulelor matematice, folosind limbajul modern LaTeX), decât această multitudine de imagini (extrem de "savant" definite de "formatul PDF"), create cu singurul scop de a fi tipărite una după alta.
vezi Cărţile mele (de programare)