Limbaje şi Calculator (de la nivel-înalt, la microprocesor)
[1] "Limbaje şi calculator", Ed. Petrion 1998 (ISBN 973-9116-45-0)
În [1] evidenţiam (potrivnic manualelor uzuale) că limbajele nu sunt izolate faţă de calculator - dimpotrivă, scheletul de bază al oricărui limbaj corespunde structurii tipice de CPU şi posibilităţilor de corelare cu un sistem de operare.
Linia metodologică intuitivă pe care o lansam avea ca idee interpretarea continuă a binecunoscutei teze "programe = algoritmi + structuri de date". Investigând codul furnizat de compilator pentru programe simple (în Pascal, C, etc.), ajungem la formula (de memorie+CPU) program = zonă de cod (CS; IP) + zonă de date (DS); angajând apoi subprograme şi analizând implicaţiile către CPU, ale realizării transferului bidirecţional de control şi de parametri - se prelungeşte formula cu + zonă-stivă (SS; SP/ESP) + cadru-stivă (BP/EBP), unde valorile de bază DS, CS, SS rezultă prin corelare (asigurată de către sistemul de operare) cu mediul de execuţie.
Se intuiau astfel, necesităţile care ar decurge logic din cerinţa ca microprocesorul să execute codul generat de compilator: necesitatea unor regiştri prin care CPU să poată viza separat zona de date şi zona de cod; necesitatea existenţei unui registru Instruction Pointer, pentru a accesa şi a parcurge automat zona de cod, instrucţiune după instrucţiune; necesitatea ca sistemul de operare să aloce o zonă de memorie în care programul aflat în execuţie să poată păstra adrese sau parametri de comunicare între subprograme şi necesitatea ca CPU să dispună de instrucţiuni corespunzătoare folosirii acestei zone; etc.
Desfăşurarea propusă inversează demersurile obişnuite: plecăm de la limbaj (de la programe într-un anumit limbaj), spre CPU (descoperind treptat diversele necesităţi privind structura şi funcţionarea CPU). Este o reacţie adecvată faptului că pregătirea informatică obişnuită în învăţământul nostru (mai ales la acea vreme) se bazează pe generalităţi introductive despre calculator şi pe descrierea prin diagrame de sintaxă sau pseudocod a unui limbaj de nivel înalt (a fost Pascal, acum e "C++") şi în esenţă, se practică două formule - una falsă, informatică = algoritmică + point-and-click şi a doua clamată peste tot program = algoritmi + structuri de date, dar instituţionalizată la cel mai superficial nivel de înţelegere (nivelul pseudocodului) - formule care conduc împreună la izolarea limbajului faţă de calculator: limbajul n-ar fi altceva decât un instrument pentru descrierea algoritmilor (ceva mai pretenţios decât "pseudocodul").
Cunoaşterea structurii tipice de CPU şi a mecanismelor de funcţionare sau de programare asigurate de această structură asigură o însuşire "unitară" a limbajelor şi o mai eficientă folosire (şi nu doar a unuia, ci a mai multor limbaje, după caz).
Locaţii de memorie şi modele de memorie
În termenii cei mai simpli, memoria este un dispozitiv pasiv (un depozit; un container; un suport) cu rolul de a păstra "informaţii" (reprezentate adecvat) şi care permite altor echipamente operaţii de "citire" (obţinerea informaţiei memorate) şi de "scriere" (depunerea sau înregistrarea informaţiei în memorie) - operaţii care se bazează pe existenţa unei ordonări implicite care asigură localizarea unui anumit conţinut (prin "adresa" acestuia în cadrul memoriei):
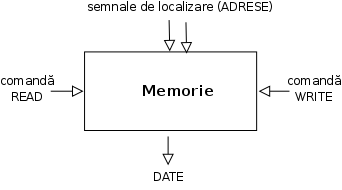
În cazul unui calculator, putem vorbi de două tipuri de memorie: memoria internă (vom zice scurt: memorie) este materializată prin "cipuri de memorie" (sau plăcuţe de memorie) aflate pe placa de bază, alături de acele componente care asigură procesarea informaţiei; memoria externă ţine de exteriorul plăcii de bază, având un anumit suport (disc, bandă magnetică) pe care de obicei, informaţia este localizată (citită, scrisă) printr-o anumită antrenare mecanică a suportului. În vederea procesării, datele din memoria externă trebuie transferate în memoria internă.
Un cip de memorie apare ca o capsulă paralelipipedică din care ies pinii circuitului, care servesc pentru accesarea circuitului interior capsulei (pentru alimentarea lui şi pentru localizarea, citirea sau scrierea informaţiei).
În alţi termeni, memoria internă este un tablou de circuite bistabile; un bistabil (sau flip-flop) are numai două stări stabile (şi complementare), asimilate respectiv cu 0 şi 1 - astfel că el poate memora un bit de informaţie (adică una dintre cele două cifre ale sistemului de numeraţie cu baza 2: 0 şi 1, numite "cifrele binare" sau biţi).
Cuplând şi indexând două bistabile (doi biţi) rezultă patru posibilităţi:
| bitul 1 (cu ponderea 21) |
bitul 0 (cu ponderea 20) |
secvenţa binară | valoarea zecimală |
|---|---|---|---|
| 0 | 0 | 00 | 0 = 0*20 + 0* 21 |
| 0 | 1 | 01 | 1 = 1*20 + 0* 21 |
| 1 | 0 | 10 | 2 = 0*20 + 1* 21 |
| 1 | 1 | 11 | 0 = 1*20 + 1* 21 |
Bistabilele dintr-un cip de memorie sunt aranjate de obicei, în grupe de câte opt - constituind locaţii de memorie. Denumirea byte (sau octet) ar desemna mai degrabă o valoare numerică reprezentată pe 8 biţi (sau o secvenţă binară de lungime 8); un octet poate fi conţinutul unei locaţii de memorie, dar la fel de bine poate fi conţinutul vreunui alt element de memorare (de exemplu, un registru al CPU).
Scriind ca în tabelul de mai sus, secvenţele binare şi valorile lor de câte 3 biţi (când se adaugă şi "bitul 2" de pondere 22), de câte 4 biţi (adăugând şi "bitul 3", de pondere 23), etc. - putem deduce că o locaţie de memorie poate înregistra una dintre cele 28 secvenţe binare 00000000, 00000001, 00000010, ..., 11111110, 11111111 corespunzând respectiv valorilor 0, 1, 2, ..., 254, 255 = 28-1 — octeţi, sau valori de tip byte, sau cifrele sistemului de numeraţie cu baza 28 = 256; sau la fel de bine, resturile modulo 256.
Indexând de la dreapta, conform ponderilor convenite, avem următoarea imagine de locaţie de memorie:
| b7 | b6 | b5 | b4 | b3 | b2 | b1 | b0 |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
Bitul b0 este bitul cel mai puţin semnificativ (el având ponderea cea mai mică, 20); în figură avem valorile b0 = 1, b1 = 1, b2 = 0, etc. Bitul b7 (cu ponderea maximă 27) este bitul cel mai semnificativ. Valoarea conţinută în locaţie este numărul b7b6b5b4b3b2b1b0 = b0 + 21×b1 + 22×b2 + 23×b3 + 24×b4 + 25×b5 + 26×b6 + 27×b7 (redat în baza 2 si respectiv, calculat în baza10; de exemplu, locaţia desenată mai sus conţine valoarea 1 + 21 + 23 + 24 + 25 + 26 = 123).
Pentru practică este util să observăm că o secvenţă de 8 biţi este constituită prin alipirea a două secvenţe de câte 4 biţi: 0000, 0001, 0010, 0011, ..., 1110, 1111; avem 24 = 16 secvenţe de câte 4 biţi, având valorile 0, 1, 2, ..., 15 = 24-1; acestea sunt cifrele sistemului de numeraţie cu baza 16 (cifrele hexazecimale), fiind desemnate uzual prin caracterele 0, 1, 2, ..., 9, A, B, C, D, E, F (A = 10, B = 11, etc.). Deci putem reda secvenţele de câte 8 biţi şi prin concatenarea a câte două cifre hexazecimale: 0016, 0116, ..., 0916, 0A16, 0B16, ..., 0F16, 1016, 1116, ..., 1916, 1A16, ..., 1F16, 2016, ..., FE16, FF16. De obicei, pentru a indica reprezentări hexazecimale se folosesc anumite prefixe; de exemplu valoarea FE16 s-ar reda în C, în Perl, în Javascript, etc. prin 0xFE (0 arată că nu poate fi vorba de un identificator, fiindcă identificatorii încep cu literă sau cu "_"; iar x vine de la "hex").
Exemplele următoare arată procedee practice de conversie:
— conversie la baza 10: 0xCD = C16 * 16 + D16 = 12 * 16 + 13 = 205;
— conversie la baza 2: 0xCD = 1100211012 = 110011012
(am scris în baza 2 fiecare cifră hexazecimală şi am alipit secvenţele de câte 4 biţi)
— conversie la baza 16, continuată la baza 2: 123 = 16 * 7 + 11 = 0x7B = 011110112
(împărţire la 16, exprimare hexazecimală, înlocuire cu cei câte 4 biţi)
— conversie la baza 2, continuată la baza 16: 123 = 64 + 32 + 16 + 8 + 2 + 1 = 26 + 25 + 24 + 23 + 21 + 20 = 011110112 = 0111210112 = 0x7B
(exprimând ca sumă de puteri ale bazei 2, au rezultat rangurile biţilor de valoare 1, în cadrul reprezentării binare; apoi, am înlocuit câte 4 biţi prin cifra hexazecimală).
Ne putem imagina memoria ca fiind un tablou liniar de locaţii; numărul de ordine asociat astfel unei locaţii este adresa absolută a acesteia. Pentru a realiza operaţii de citire/scriere a memoriei, dispozitivele respective trebuie să dispună de o modalitate de indicare a adresei (de unde se citeşte, sau unde se scrie); rezultă anumite limitări sau inconveniente, care au determinat în timp conceperea de diverse modele de memorie, implicând atât hardware-ul cât şi software-ul.
Următoarea vedere este suficient de sugestivă: un an calendaristic AN, poate fi gândit ca fiind un tablou de maximum 366 de zile; putem referi una din zile prin "adresa absolută" 0..365, de exemplu AN[130] - ceea ce este desigur, inconvenabil; sau, putem avea în vedere o segmentare a anului într-un anumit număr de "sub-tablouri" (lunile anului, desigur), permiţând astfel referirea unei zile prin formula Segment: Offset unde prima componentă localizează "segmentul" (adică luna anului), iar a doua indică adresa relativă a zilei ("offset"-ul zilei faţă de "baza" segmentului; în loc de AN[130] am folosi 5:9, sau mai convenabil Mai:9).
Forţând puţin, în scopul evidenţierii prin analogie a problemelor de accesare care au condus la diverse modele de memorie - să presupunem că aşa este dispozitivul nostru de "citire/scriere" în tabloul AN, că nu putem folosi decât valori de maximum 2 cifre zecimale (… precum copiii de la grădiniţă). Aceasta înseamnă că dispozitivul respectiv (… calendarul) nu va fi capabil să localizeze prin "adresa absolută" în tabloul AN decât primele 100 de zile; evident, problema se rezolvă adoptând "modelul segmentat", fiindcă "Segment" (luna calendaristică) are valori 0..11, iar "Offset" are valori 0..31.
În modelul de memorie segmentată, memoria este văzută de dispozitive ca şi cum ar fi împărţită în segmente; fiecare segment conţine un anumit număr de locaţii consecutive; dimensiunea standard a unui segment este - în funcţie de microprocesor - de 216, sau de 232 locaţii de memorie.
În cadrul unui segment precizat, adresarea se poate face în modul "plat", indicând o locaţie din acel segment prin offset-ul ei - numărul de ordine al locaţiei faţă de prima locaţie din segment, sau altfel spus - numărul care arată câte locaţii o preced în acel segment. Dar o locaţie oarecare din memorie, va necesita pentru localizare precizarea ambelor componente: un segment care o include şi respectiv, offset-ul ei în acel segment.
Nu se impune segmentelor să fie disjuncte; o locaţie poate aparţine mai multor segmente şi poate fi referită prin mai multe combinaţii de segment şi offset (se creează astfel posibilitatea reducerii cerinţelor de memorie: în general, datele şi instrucţiunile unui program sunt memorate în segmente distincte, nesuprapuse, iar când datele ocupă abia un sfert din segmentul de date, atunci restul neocupat al acestuia ar putea fi alocat segmentului de cod).
Fiindcă memoria are o structură liniară, iar dispozitivele o văd segmentat - se pune problema convertirii între formatele de adresare liniară (prin adrese absolute) şi respectiv prin Segment:Offset (şi s-a ajuns la circuite complexe - integrate de obicei în microprocesor - care asigură pentru diverse moduri de operare, transformarea în (sau de la) adrese fizice de memorie, pe lângă alte sarcini legate de controlul accesului la memorie). Adresa absolută la care poate începe un segment de memorie, trebuie să fie multiplu de 16 (motivul va reieşi mai încolo); aceasta înseamnă că în scrierea hexazecimală a ei, ultima cifră este totdeauna 016 = 00002 şi ca urmare, ea poate fi omisă din specificaţia adresei de segment (urmând a reconstitui adresa absolută prin înmulţire cu 16, sau totuna - prin deplasare spre stânga cu 4 poziţii binare). Prin urmare, adresa absolută a locaţiei referite prin Segment:Offset va fi valoarea Segment * 16 + Offset.
Iată şi câteva exemple semnificative de calcul, asumând segmente de 216 locaţii.
— segmentul 0 al memoriei începe cu locaţia de adresă absolută 0 şi include toate locaţiile până la adresa absolută 216-1; segmentul 1 cuprinde locaţiile de adrese absolute 16..216 + 15; segmentul 2 acoperă adresele absolute 32..216 + 31.
— locaţia de adresă 32 poate fi încadrată segmentului 0 (având 32 = 0*16 + 32), sau segmentului 1 (având 32 = 1*16 + 16), sau segmentului 2 (având 32 = 2*16 +0) - putând fi referită prin 0:32, 1:16, respectiv prin 2:0. Primele 16 locaţii, de adrese absolute 0..15, aparţin numai segmentului 0.
— locaţia indicată prin 64:200 (sau în hexazecimal, 0x40:0xC8) are adresa absolută 64*16 + 200 = 1224 (sau calculând în hexazecimal, 0x40 * 0x10 + 0xC8 = 0x400 + 0xC8 = 0x4C8); scăderea cu 16 a părţii de offset înseamnă mărirea cu 1 a părţii de segment, încât aceeaşi locaţie poate fi referită şi cu 65:184, sau 66:168, etc.
— fiind dată adresa absolută 61213, să determinăm segmentul în care locaţia respectivă să aibă offset-ul cel mai mic: avem 61213 = 16*3825 + 13, deci segmentul cerut este 3825 şi locaţia se referă prin 3825:13.
Permiterea necontrolată a accesului la locaţiile din memoria fizică poate periclita funcţionarea sistemului. Neajunsurile care s-au constatat au condus (începând din 1982, odată cu apariţia microprocesorului Intel 80286) la conceperea modelului de memorie protejată; şi în modul protejat se foloseşte adresarea prin Segment:Offset - dar acum Segment nu mai vizează segmentul fizic respectiv, ci este un indice de selectare a unei intrări într-un tabel gestionat de către sistemul de operare ("tabela descriptorilor de segmente"). În acest tabel se păstrează şi se actualizează informaţii privind diversele segmente de memorie: cui aparţine, sau care program are acces la informaţia conţinută în segmentul respectiv; ce drepturi (read/write) are proprietarul asupra segmentului; ce conţine - date, sau cod; limitele reale în memorie la momentul respectiv; dacă segmentul se află într-adevăr în memoria internă, sau a fost temporar descărcat în memoria externă; etc.
Accesarea memoriei; regiştri ai microprocesorului
Memoria internă are un rol pasiv: păstrează informaţii. Recunoaşterea şi procesarea propriu-zisă a informaţiei respective este sarcina microprocesorului, desemnat de obicei prin CPU; acesta dispune prin construcţia sa, de un set intern de instrucţiuni ("limbajul maşinii") care pot să fie folosite de către sistemele de operare şi de către aplicaţii pentru gestionarea traficului informaţiei şi realizarea operaţiilor asupra datelor.
Această sarcină este asigurată material în primul rând, prin conectarea CPU cu memoria internă; comunicarea se face prin trei magistrale comune: una pentru adrese, una pentru date şi una destinată altor semnale (de comandă, control, stare). Într-o accepţie simplă, o magistrală (sau bus) ar fi constituită din una sau mai multe "sârme" paralele, pe care circulă semnale electrice de anumite nivele standard; unele nivele de semnal electric sunt interpretate fie ca "1", fie ca "0" (de exemplu, o linie pe care circulă un semnal de 0.0 - 0.8V reprezintă "0", iar una cu semnal 2.4 - 5V reprezintă "1"; un semnal de 0.8-2.4V poate indica o tranziţie în curs pe linia respectivă, de la "0" la "1" sau invers).
Magistrala de adrese este alcătuită dintr-un anumit număr de "linii de adresă" A0, A1, A2, ..., An; semnalele emise pe aceste linii constituie împreună adresa absolută a unei locaţii de memorie şi semnalele respective determină selectarea acelei locaţii, făcând posibile operaţiile de citire/înscriere a conţinutului ei:
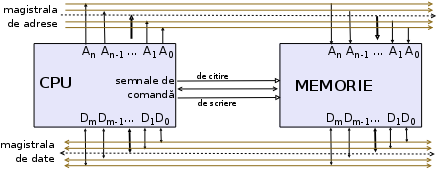
Cum realizează CPU operaţia de scriere în memorie (adică înscrierea unui octet într-o anumită locaţie de memorie, sau a unui cuvânt de 16/32/64 biţi în 2/4/8 locaţii consecutive)? În principiu, prin emiterea pe magistrale a semnalelor corespunzătoare, într-o anumită succesiune:
— se aplică adresa locaţiei pe magistrala de adrese;
— se depune cuvântul de date pe magistrala de date;
— se activează semnalul de comandă a scrierii; ca urmare, cuvântul existent pe magistrala de date va "intra" în locaţia a cărei adresă a fost aplicată pe magistrala de adrese;
— se dezactivează semnalul de scriere;
— se "eliberează" magistralele de date şi de adrese.
Este clar că se va putea selecta o anumită locaţie de memorie, numai dacă adresa acesteia "încape" în magistrala de adrese; de exemplu, dacă ar fi numai 4 linii de adresă, atunci s-ar putea accesa direct numai locaţiile de la adresele 0..15 - fiindcă adresa 16 = 100002 deja ar depăşi lăţimea de 4 biţi asumată aici. Primele microprocesoare pe 8 biţi (Intel 8080 în 1974, apoi Zilog Z80) aveau magistrala de adrese de 16 linii - permiţând adresarea directă a unei memorii de capacitate 216 = 64Ko; apoi, I8086 lărgeşte magistrala de adrese la 20 de linii, putând adresa direct 220 = 1Mo locaţii distincte; în 1982 Intel 80286 o extinde la 24 de biţi, iar apoi I80486 şi Pentium o extind la 32 de biţi.
Este foarte importantă de asemenea, lăţimea magistralei de date. Pentru a permite în modul descris mai sus, transferul unui octet - magistrala de date trebuie să aibă cel puţin 8 linii; dar, dacă ar avea numai 8 linii (cazul I8080), atunci pentru a transfera un grup de doi octeţi sunt necesare două operaţii distincte - pe când dacă are 16 biţi (I8086, I80286; 32 biţi pentru I80486) atunci este posibil transferul simultan a doi octeţi (într-o singură operaţie).
Cuvinte elementare şi ordinea lor în memorie
Asigurarea lăţimii de 16 / 32 / 64 biţi pentru magistrale permite considerarea, pe lângă octet (sau byte) - care este conţinutul unei singure locaţii de memorie, deci are 8 biţi lungime - şi a datelor multi-octet; se numeşte word o dată constituită prin "alipirea" a din doi octeţi şi dword o dată constituită din 4 octeţi (32 de biţi).
Pentru a permite operarea într-un acelaşi mod asupra unor date "multi-octet", a trebuit să se aleagă una din cele două posibilităţi privind ordinea depunerii în memorie a octeţilor componenţi: convenţia little-endian - adoptată de Intel - consideră că octetul mai semnificativ este memorat în locaţia cu adresa mai mare (altfel spus, semnificativitatea octetului creşte odată cu adresa de memorie); convenţia inversă, big-endian (în care, octetul mai semnificativ este primul, adică este memorat la adresa mai mică) este întâlnită de exemplu la microprocesoarele Motorola 68000.
De exemplu, am putea spune pentru analogie că 2008-04-18 reprezintă o dată calendaristică în format "big-endian", iar 18-04-2008 reprezintă aceeaşi dată în format "little-endian".
Un word oarecare, având 16 biţi - rezultă prin concatenarea a două secvenţe de câte 8 biţi (a doi octeţi); valoarea maximă a unui octet este 111111112 = FF16 = 255, deci valoarea maximă a unui word este FFFF16 = (FF16)(FF16)256 = (255)(255)256 = 255*256 + 255 = 65535 = 216-1. Oricărui word W = 0..216-1, i se poate asocia un tablou de două locaţii consecutive (L[0], L[1]) încât W = L[0] + 256 * L[1] — anume, luând L[0] = W mod 256 şi L[1] = W div 256 (unde "a mod b" şi "a div b" desemnează restul şi respectiv câtul împărţirii lui a prin b). L[0] este cifra low (cea mai puţin semnificativă), iar L[1] este cifra high din reprezentarea lui W în baza 256.
Spre exemplu, să vedem cum se reprezintă în memorie numărul 1234; faţă de baza 216 avem 1234 = 4 * 256 + 210 = (4)(210)256, deci în memorie am avea:
| adresă | conţinut | |
|---|---|---|
| ... | ... | |
| A | 210 | (octetul low) |
| A + 1 | 4 | (octetul high) |
| A + 2 | ... |
Cum 210 = 14 * 16 + 2 = (14)(2)16 = 1110200102 = 111000102 avem în final, următorul tablou de memorie:
| adresa A - 1 | A | A + 1 | adresa A + 2 |
| --- | 11100010 | 00000100 | --- |
Observaţie: reprezentarea în memorie nu coincide cu reprezentarea binară obişnuită. Astfel, reprezentarea în baza 2 cu 16 cifre binare obţinută mai sus este 1234 = 00000100111000102, ori în memorie cele 8 cifre de la sfârşitul reprezentării binare compun octetul low, de adresă A, iar cele 8 cifre binare iniţiale constituie octetul high, de adresă A + 1 (în memorie, octeţii sunt inversaţi faţă de ordinea "firească").
Alinierea cuvintelor în memorie
Memoria este accesată prin intermediul magistralelor, pe unităţi de un octet, un word, sau un dword; adresa unei date multi-octet este dată de adresa celui mai puţin semnificativ octet al ei (se subînţelege - peste tot aici, folosim convenţia "little-endian"); în exemplul de mai sus, word-ul 1234 conţinut în locaţiile de adrese A, A + 1 are adresa A. Deci pentru a citi data respectivă, trebuie ca pe magistrala de adrese să se depună adresa octetului low al ei.
Să zicem ca magistrala de date are lăţimea de 16 biţi. Transferul unui octet are loc pe oricare dintre cele două jumătăţi ale căii de date, însă: dacă A0 = 0 (adică adresa octetului respectiv este număr par), atunci octetul este transferat pe liniile D7 - D0 (jumătatea inferioară a căii de date), iar dacă A0 = 1 (adică octetul respectiv are adresa impară), atunci el este transferat pe D15 - D8 (jumătatea superioară a căii de date).
Ca urmare a acestei reguli, s-a creat posibilitatea ca un word care are octetul low la adresă pară (A0 = 0) să fie transferat pe D15 - D0 într-un singur ciclu (octetul low fiind depus pe D7 - D0 ca având adresa pară, iar octetul high - de la adresa următoare, deci impară - fiind depus pe D15 - D8 — încât în final se transferă întregul word, în cadrul unei aceleiaşi operaţii de transfer).
În schimb, dacă A0 = 1 (word-ul are adresă impară), atunci vor fi necesare două operaţii succesive (cu remediul că ele sunt înlănţuite automat): se transferă întâi octetul low pe D15 - D8 şi apoi şi octetul high (de adresă pară) pe D7 - D0.
Avem justificată astfel, opţiunea (directiva) word align data oferită de compilatoare sau de asambloare (în baza căreia, datele vor fi aliniate în memorie la adrese pare - mărind prin aceasta, viteza accesării lor).
Regiştrii microprocesorului
CPU fiind exterior memoriei, ar fi de imaginat că pentru a face o operaţie binară, el ar trebui în prealabil să acceseze operanzii respectivi din memorie, prin intermediul magistralelor — ceea ce am văzut ca este totuşi costisitor în privinţa timpului necesar. Acesta ar fi un prim motiv, pentru care microprocesorul conţine el însuşi câteva locaţii interne de memorie, numite regiştri; etapa citirii din memorie prin intermediul magistralelor se va putea eventual elimina, înlocuind-o printr-o încărcare directă în regiştri.
Între "locaţie de memorie" şi "registru al CPU" avem două deosebiri esenţiale. Locaţiile de memorie au în mod explicit, atributul de "adresă"; iar în limbaj de asamblare, pentru a distinge între adresă şi conţinutul locaţiei de la adresa respectivă, folosim parantezele: dacă X este o adresă, atunci [X] (sau, în unele asambloare (X)) este conţinutul locaţiei de la adresa respectivă (analog cum, dacă j este rangul unui element al tabloului V, atunci V[j] este valoarea acelui element). În schimb, regiştrii CPU nu au asociate în mod explicit, adrese; fiind în număr mic, ei sunt referiţi prin mnemonice (AX, BX, EAX, etc.); desigur, acestea sunt utilizabile la nivelul limbajelor de programare, altfel - intern - regiştrii sunt adresaţi prin coduri de 3-4 biţi (de exemplu, 8 regiştri vor fi referiţi prin "adresele" 0002, 0012, 0102, ..., 1112).
A doua deosebire se referă la dimensiune: regiştrii CPU au dimensiunea corelată cu aceea a magistralelor de adrese şi de date; unii regiştri au 8 biţi (ca şi locaţiile de memorie), alţii au 16, 32 sau 64 de biţi; iar regiştrii coprocesorului — FPU, component şi el al CPU, fiind dedicat pentru calcule "în virgulă mobilă" (când numerele sunt reprezentate "segmentat": o parte de exponent si o parte de mantisă) — au dimensiunea standard de 80 biţi.
Microprocesoarele Intel 80x86 dispun de 4 regiştri principali pentru date, denumiţi simplu AX, BX, CX, DX - toţi de tip word; părţile low ale acestora (cuprinzând biţii mai puţin semnificativi, de la rangul 0 la rangul 7) sunt denumite respectiv AL, BL, CL, DL în timp ce părţile high ale lor (biţii de la rangul 8 până la rangul 15) sunt desemnate prin mnemonicele AH, BH, CH, DH.
 Microprocesoarele I80386 şi cele ulterioare dispun si de nişte extensii ale acestor regiştri, denumite EAX, EBX, EVX, EDX - toţi de tip dword; de exemplu, AX este acum parte (şi anume, partea low) a lui EAX.
Microprocesoarele I80386 şi cele ulterioare dispun si de nişte extensii ale acestor regiştri, denumite EAX, EBX, EVX, EDX - toţi de tip dword; de exemplu, AX este acum parte (şi anume, partea low) a lui EAX.
Observaţie: reprezentarea în baza 2 coincide de data aceasta, cu reprezentarea în regiştri; însă corespondenţa între regiştri şi memorie se face asociind părţii low locaţia de adresă mai mică.
Dat fiind că un registru nu mai are asociată explicit o adresă, nu mai este nevoie (ca în cazul locaţiilor de memorie) să indicăm valoarea conţinută de registru prin vreo convenţie specială (precum, folosirea parantezelor); mnemonica registrului va reprezenta însăşi valoarea conţinută de registru. Între valoarea existentă într-un registru de 16 biţi şi valorile subregiştrilor săi de câte 8 biţi, avem relaţii precum:
— AX = 256 * AH + AL
— AH = AX div 256
— AL = AX mod 256
Însă valoarea existentă într-un registru va putea fi interpretată în anumite cazuri, drept adresă de memorie; cu alte cuvinte, în loc să adresăm direct o locaţie de memorie (precizând în mod explicit adresa ei), o vom putea adresa indirect, prin intermediul unui anumit registru care ar conţine adresa locaţiei. În acest caz, conţinutul locaţiei respective va fi redat (la nivelul limbajului de asamblare) prin încadrarea cu paranteze a mnemonicii registrului; de exemplu, dacă avem BX = 1000, atunci notaţia [BX] va desemna nu conţinutul registrului BX (valoarea 1000) - ci valoarea existentă în locaţia de adresă 1000 (sau mai precis, de la offset-ul 1000 într-un anumit segment de memorie). Prin adresarea directă a unei locaţii de memorie (în vederea citirii sau scrierii), adresa ei (cunoscută explicit) este depusă ca atare, pe magistrala de adrese; în schimb, când ea este adresată indirect, de exemplu prin BX (nu ştim adresa ei, ci doar că ea se află în BX) - atunci pe magistrala de adrese se va depune conţinutul registrului respectiv, BX.
Regiştrilor CPU li s-a conferit un rol important în realizarea transferurilor de date. CPU nu asigură transferul direct între locaţii de momorie (nu operează schema "memorie => memorie"), ci doar prin intermediul regiştrilor (după schema "memorie => registru => memorie"). Mai mult, o locaţie de memorie dată explicit prin Segment:Offset (de exemplu, 100:1234) nu poate fi adresată de CPU decât prin intermediul regiştrilor de segment: partea de Segment 100, trebuie înregistrată în prealabil într-un registru de segment de exemplu DS ("Data Segment"), după care locaţia va fi adresată prin DS:Offset (unde Offset poate fi dat ca atare, sau este şi el, dat indirect - indicând un registru care conţine adresa relativă respectivă).
Principiul compatibilităţii şi adresarea segmentată
În anul 1978 a apărut un nou membru marcant al familiei de microprocesoare INTEL - anume, I8086; tipurile ulterioare, până la I80486 şi Pentium, au respectat consecvent principiul compatibilităţii în jos - ceea ce a contribuit şi la succesul imediat pe piaţă: adaptarea aplicaţiilor existente, cu care utilizatorul era deja obişnuit, a necesitat cheltuieli minime (aplicaţiile create iniţial pentru I8086 "merg" şi pe Pentium).
Compatibilitatea în jos s-a asigurat prin menţinerea principiilor de adresare a memoriei. I8086 are 20 de pini pentru adresă (altfel spus, are o magistrală de adrese de lăţime 20) - ceea ce asigură adresarea directă a 220 = 16 * 216 locaţii, prin adresele 0x00000, 0x00001, 0x00010, ..., 0xFFFFF de câte 5 cifre hexazecimale (5 cifre × 4 biţi = 20 biţi). Dar iată ce nepotrivire trebuia rezolvată: dimensiunea maximă a regiştrilor era de 16 biţi - ori într-un registru de 16 biţi se pot forma doar adresele 0..216 - 1 (mai precis, se pot adresa 216 locaţii consecutive - un segment oarecare - şi nu neapărat numai cele de la adresele absolute 0..216 - 1).
Pentru a permite adresarea a 220 locaţii consecutive (cât ar permite cele 20 de linii de adresă), s-a adoptat modelul segmentat de memorie: unii regiştri au fost înzestraţi prin proiectarea iniţială, cu funcţia specială de a păstra partea de segment a adresei — anume, regiştrii cu mnemonicele CS, DS, ES, SS (la care, începând cu I80386, s-au adăugat FS si GS - rezultând acum în total, 6 regiştri de segment). Pe de altă parte, s-a încorporat microprocesorului o unitate funcţională care să asigure formarea adreselor fizice de 20 biţi, pe baza componentelor Segment:Offset (unde partea de Segment sa fie conţinută într-un registru de segment).
O adresă de 20 de biţi are 5 cifre hexazecimale, ori un registru de 16 biţi (cum sunt regiştrii de segment) poate păstra doar 4 cifre hexazecimale; s-a adoptat atunci convenţia ca prima locaţie din oricare segment de memorie să aibă adresa absolută ("adresa de bază" a segmentului) multiplu de 16 - adică ultima cifră din reprezentarea sa hexazecimală să fie zero (4 biţi 0). Registrul de segment va fi încărcat cu numărul dat de primele 4 cifre hexazecimale ale adresei de bază a segmentului respectiv, urmând ca unitatea de formare a adresei fizice să asigure deplasarea spre stânga cu 4 biţi a valorii transmise prin registrul de segment (rezultând astfel adresa de bază a segmentului, cu 5 cifre hexazecimale, dintre care ultima este totdeauna 0x0000) si la valoarea rezultată astfel să adune partea de offset a adresei locaţiei respective (partea de offset fiind dată explicit ca număr 0..216 - 1, sau fiind conţinută de un registru precizat dar care, nu poate fi tot un registru de segment).
Cu alte cuvinte, specificaţia Segment:Offset trebuie adaptată la DS:Offset (unde DS a fost încărcat cu valoarea Segment), sau CS:Offset, etc. Această modalitate de adresare a fost apoi păstrată, doar că - odată cu extinderea magistralelor la 32 biţi şi cu apariţia modului "protected" - s-a putut creşte dimensiunea segmentului de memorie; regiştrii de segment au rămas tot de câte 16 biţi, dar partea de offset poate fi acum de 32 biţi.
Instrumente de investigare; zona de date şi zona de cod
Să zicem că vrem să vedem reprezentările în memorie pentru diverse valori… În acest scop, am putea scrie un program simplu - definim nişte variabile şi afişăm adresele şi valorile aferente.
În C, &VAR dă adresa variabilei VAR, iar *ADR dă valoarea memorată la adresa păstrată de variabila (pointer) ADR. Operatorii de referenţiere/dereferenţiere & şi * ţin cont de tipul variabilei - mai precis, de dimensiunea zonei alocate. De exemplu, dacă &VAR = 1000 (VAR are adresa 1000) şi VAR este de tip int, iar sizeof(int) = 4 — atunci &VAR+1 este adresa 1004 (adresa valorii de tip int "următoare" celeia de la adresa lui VAR), nu 1001. Pentru a referi octeţii componenţi şi nu "întreaga" valoare (de 4 octeţi) reprezentată de VAR, trebuie să convertim &VAR (adresă de valori int) în adresă de valori de tip char, folosind (char*) &VAR.
/* "limb1.c" */ #include <stdio.h> unsigned int j = 1234; /* 'j' şi 'tc' sunt variabile globale */ unsigned char tc[6] = {'a', 'z', 'A', 'Z', '0', '9'}; main() { int offs; /* 'offs' şi 'adr' sunt variabile locale */ unsigned char* adr = (unsigned char*) &j; printf("adresa variabilei 'j': %p => valoare: %u (pentru 'int' alocă %u octeţi)\n", &j, *(&j), sizeof(int)); printf("adresa tabloului 'tc': %p (are alocaţi %u octeţi)\n", tc, sizeof(tc)); printf("\n10 locaţii de memorie, începând de la adresa variabilei globale 'j':\n"); for(offs = 0; offs < 10; offs++, adr++) printf("%p => %0X ('%c')\n", adr, *adr, *adr); printf("\nadresa variabilei locale 'offs': %p => valoare: %u\n", &offs, *(&offs)); printf("\nadresa codului funcţiei 'main': %p\n", &main); }
Considerăm chiar două variante, pentru obţinerea unui "executabil": întâi, folosind GCC (compilatorul standard adoptat pe Linux şi care se poate folosi şi pe alte sisteme de operare); apoi, folosind un compilator Borland C++ pe un sistem Windows. Vom reda rezultatele execuţiei şi le vom interpreta în contextul nostru de discuţie.
Pe Linux, deschizând un terminal şi lansând de pe linia de comandă gcc limb1.c -o limb1.exe - obţinem fişierul executabil "limb1.exe" (de aprox. 7Ko); lansând apoi "limb1.exe", obţinem:
adresa variabilei 'j': 0x80497a8 => valoare: 1234 (pentru 'int' se alocă 4 octeţi)
adresa tabloului 'tc': 0x80497ac (are alocaţi 6 octeţi)
10 locaţii de memorie, începând de la adresa variabilei globale 'j':
0x80497a8 => D2 ('�)
0x80497a9 => 4 ('')
0x80497aa => 0 ('')
0x80497ab => 0 ('')
0x80497ac => 61 ('a')
0x80497ad => 7A ('z')
0x80497ae => 41 ('A')
0x80497af => 5A ('Z')
0x80497b0 => 30 ('0')
0x80497b1 => 39 ('9')
adresa variabilei locale 'offs': 0xbfc7a24c => valoare: 10
adresa codului funcţiei 'main': 0x80483a4
Iar pe Windows, având instalat un compilator BCC.EXE ("the 16-bit command-line compiler Borland C++ Version 5") — putem proceda astfel: accesăm meniul Run... din bara de Start şi lansăm un terminal cu C:\WINDOWS\System32\cmd.exe; intrăm în directorul în care avem fişierul-sursă cd C:\Teste şi lansăm BCC: C:\Teste> C:\bc5\BIN\bcc limb1.c. În urma compilării şi invocării editorului de legături (Turbo Link), obţinem în directorul nostru de lucru fişierul executabil "limb1.exe" (de peste 31 KB) - pe care-l lansăm apoi (de la prompt): C:\Teste> limb1.exe > limb1.txt (am redirecţionat ieşirea către "limb1.txt", pentru a transfera apoi rezultatele respective pe Linux).
adresa variabilei 'j': 00A8 => valoare: 1234 (pentru 'int' se alocÄ 2 octeÅ£i)
adresa tabloului 'tc': 00AA (are alocaţi 6 octeţi)
10 locaţii de memorie, începând de la adresa variabilei globale 'j':
00A8 => D2 ('Ò')
00A9 => 4 ('')
00AA => 61 ('a')
00AB => 7A ('z')
00AC => 41 ('A')
00AD => 5A ('Z')
00AE => 30 ('0')
00AF => 39 ('9')
00B0 => 61 ('a')
00B1 => 64 ('d')
adresa variabilei locale 'offs': FFF4 => valoare: 10
adresa codului funcţiei 'main': 0293
Sau, folosind de această dată compilatorul pe 32 de biţi, bcc32.exe:
C:\Teste>bcc32 limb1.c
Borland C++ 5.0 for Win32 Copyright (c) 1993, 1996 Borland International
limb1.c:
Warning limb.c 22: Function should return a value in function main
Turbo Link Version 1.6.72.0 Copyright (c) 1993,1996 Borland International
C:\Teste>limb1
adresa variabilei 'j': 00407074 => valoare: 1234 (pentru 'int' se alocă 4 octeţi)
adresa tabloului 'tc': 00407078 (are alocaţi 6 octeţi)
10 locaţii de memorie, începând de la adresa variabilei globale 'j':
00407074 => D2 ('╥')
00407075 => 4 ('♦')
00407076 => 0 (' ')
00407077 => 0 (' ')
00407078 => 61 ('a')
00407079 => 7A ('z')
0040707A => 41 ('A')
0040707B => 5A ('Z')
0040707C => 30 ('0')
0040707D => 39 ('9')
adresa variabilei locale 'offs': 0012FF88 => valoare: 10
adresa codului funcţiei 'main': 0040107C
Interpretarea rezultatelor şi alte observaţii
În limb1.c s-au declarat câteva variabile (bineînţeles că puteam considera şi mai multe). Variabilele globale sunt reprezentate într-o zonă de memorie contiguă, în ordinea în care apar ele în fişierul-sursă; variabilele locale au în mod clar, o zonă de reprezentare separată de aceea a variabilelor globale; zona care corespunde instrucţiunilor de executat (codul funcţiei main()) este separată faţă de celelalte zone de memorie.
Vedem că s-a folosit adresare pe 32 de biţi, respectiv pe 16 biţi - după caz. Adresele sunt reprezentate numai prin "offset" (nu ca Segment:Offset); este de intuit că locaţiile respective fac parte dintr-un acelaşi segment de memorie (o anumită porţiune a lui - pentru date şi o alta, disjunctă de prima - pentru cod). Este instructiv de experimentat cât de puţin cu programul — adăugând încă nişte variabile, recompilând şi reexecutând în diverse contexte - de exemplu după lansarea prealabilă a altor aplicaţii, sau folosind diverse opţiuni de compilare (de exemplu, privind "alinierea în memorie").
De observat că reprezentarea în memorie corespunde formatului little-endian (specifică microprocesoarelor INTEL): variabila j are reprezentarea (D2, 4, 0, 0) (respectiv, pe numai doi octeţi (D2, 0)), la adresa cea mai mică fiind octetul D2 (şi avem 0xD2 = 210, iar 210 + 4*256 = 1234 = valoarea lui j).
De observat şi că GCC (pe Linux) foloseşte codificarea "universală" Unicode (UTF-8), care reprezintă caracterele prin coduri de lungime variabilă (BCC foloseşte codul ASCII, în care fiecare caracter este reprezentat pe un octet): caracterului ţ îi corespunde un cod de doi octeţi (reprezentând î) pe care BCC i-a văzut ca atare (individual), dar GCC i-a interpretat ca reprezentând împreună un caracter. Sunt de reţinut codurile ASCII care s-au afişat: pentru 'a' 0x61, pentru 'A' 0x41 şi pentru '0' 0x30.
Privind diferenţa sensibilă de dimensiune a codului executabil (7 Ko faţă de 31 Ko), explicaţia poate decurge logic astfel: pentru obţinerea executabilului, editorul de legături trebuie să "lege" codul obiect produs de compilator pentru programul-sursă, de codul corespunzător bibliotecilor incluse (în cazul de faţă, codul funcţiei printf() din stdio); această "legare" se poate face în două moduri, după cum compilatorul respectiv este integrat sau nu, în sistemul de operare; GCC există pe orice sistem Linux, pe când BCC poate să fie sau poate să nu fie instalat, pe sistemul Windows respectiv; în cazul sistemului Linux va fi suficient pentru "legare" să se precizeze adresa codului funcţiei printf(), pe când în celălalt caz acest cod trebuie efectiv încorporat ca atare în codul executabil.
Programe de investigare specializate - Debug (Microsoft Windows)
Pentru investigarea memoriei şi a modului de funcţionare a programelor există instrumente software specializate, numite debugger. Pe de o parte, acestea permit vizualizarea conţinutului diverselor zone de memorie, inclusiv a regiştrilor CPU/FPU; pe de altă parte, permit execuţia programului în regim "pas cu pas" - posibilă datorită faptului că CPU oferă suportul hardware necesar (vizibil prin prezenţa "flagului" Trap flag (single step) în registrul FLAGS).
Folosind butonul Start ("click here to begin") şi opţiunea Run... se lansează întâi interpretorul de comenzi cmd.exe; bara de titlu a fereastrei obţinute conţine un buton (etichetat "C:\") prin a cărui punctare (prin click) se deschide un meniu care pe lângă opţiunile obişnuite pentru "butonul din stânga-sus al ferestrei Windows" (Restore, Move, Close, etc.), conţine şi un submeniu Edit care oferă opţiuni de selectare a conţinutului ferestrei şi de Copy - permiţând astfel ca rezultatele obţinute prin folosirea în fereastra respectivă a diverselor comenzi să poată fi transferate interactiv, de exemplu într-un fişier-text.
Reproducem parţial, o asemenea sesiune de lucru; după ce s-a lansat debug, s-a folosit comanda r (afişează regiştrii) şi apoi comanda ? ("Help" asupra comenzilor disponibile):
Microsoft Windows XP [Version 5.1.2600] (C) Copyright 1985-2001 Microsoft Corp. C:\Documents and Settings\vb>debug -r AX=0000 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=135C ES=135C SS=135C CS=135C IP=0100 NV UP EI PL NZ NA PO NC 135C:0100 0000 ADD [BX+SI],AL DS:0000=CD -? assemble A [address] dump D [range] enter E address [list] fill F range list go G [=address] [addresses] hex H value1 value2 load L [address] [drive] [firstsector] [number] move M range address name N [pathname] [arglist] proceed P [=address] [number] quit Q register R [register] search S range list trace T [=address] [value] unassemble U [range] write W [address] [drive] [firstsector] [number]
Comanda R a afişat conţinutul curent al regiştrilor de 16 biţi, pe două linii: întâi, regiştrii "generali" (implicaţi de exemplu în operaţii aritmetice sau folosiţi pentru a indica "offset"-uri); pe a doua linie apar regiştrii de segment, registrul "Instruction Pointer" şi starea curentă a 8 dintre flagurile microprocesorului (de exemplu, NC semnalează "Not Carry", iar NZ "No Zero"). Pe a treia linie este indicată, pe trei coloane, instrucţiunea care ar fi executată dacă s-ar tasta imediat comanda T "Trace"; pe prima coloană este adresa acestei instrucţiuni - 135C:0100, adică observând linia de deasupra CS:IP (registrul CS conţine 135C, iar IP=0100); a doua coloană redă codul maşină corespunzător instrucţiunii respective, iar a treia coloană transcrie instrucţiunea în limbaj de asamblare.
Clarificări, folosind debug
Propunem un mic experiment cu debug, pentru a face o serie de clarificări privind regiştrii CPU, reprezentarea în memorie, instrucţiunile CPU şi limbajul de asamblare.
C:\>debug -a 135E:0100 mov AX, 415A ; AX = 0x415A (adica "AZ") 135E:0103 mov word ptr [DI], AX ; DS:[DI] <-- AX 135E:0105 -u 100 104 135E:0100 B85A41 MOV AX,415A 135E:0103 8905 MOV [DI],AX
Primind comanda a, debug asamblează instrucţiunea indicată, adică: determină "codul-maşină" corespunzător (folosind un tabel propriu de mnemonice - coduri) şi îl înscrie la adresa CS:IP curentă (CS = 0x135E indică adresa de bază a segmentului de cod, iar IP = 0x100 este "offset"ul instrucţiunii). Prima instrucţiune a fost asamblată începând de la adresa CS:0100, iar a doua - de la CS:0103; deducem că octeţii de "cod-maşină" corespunzători primei instrucţiuni ocupă locaţiile de offseturi 0x100, 0x101 şi 0x102 (iar codul-maşină corespunzător celor două instrucţiuni este cuprins între CS:0100 şi CS:0104 inclusiv - de unde şi comanda "u 100 104").
mov este mnemonica folosită în multe limbaje de asamblare pentru instrucţiunile de transfer: mov Dest, Sursă transferă date (copiază) de la Sursă la Destinaţie (în unele limbaje, sintaxa este inversată: mov Sursă, Dest).
Prin comanda u, debug dezasamblează codul-maşină de la adresa specificată, afişând un tabel cu trei coloane: adresa codului-maşină, octeţii care constituie împreună codul-maşină şi "traducerea" corespunzătoare în limbaj de asamblare. Secvenţa de octeţi 0xB85A41 reprezintă "codul-maşină" al primei instrucţiuni; primul, 0xB8 este opcode ("operation code"), specificând microprocesorului operaţia de efectuat - "încarcă în registrul AX o valoare", anume 0x415A (şi vedem că octeţii acesteia sunt inversaţi în memorie, după modelul "little-endian").
Să trecem la executarea celor două instrucţiuni:
-t AX=415A BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=135E ES=135E SS=135E CS=135E IP=0103 NV UP EI PL NZ NA PO NC 135E:0103 8905 MOV [DI],AX DS:0000=20CD -t …… -d DS:0 F 135E:0000 5A 41 FF 9F 00 9A EE FE-1D F0 4F 03 C2 0D 8A 03 ZA........O.....
Primind comanda t, debug pune în execuţie instrucţiunea asamblată la adresa CS:IP curentă (CS:0x0100, în cazul primei instrucţiuni). Execuţia de către CPU a unui instrucţiuni este un proces "neinteruptibil" şi care durează unul sau mai mulţi "clock cycles"; la finalul execuţiei, IP indică adresa relativă a următoarei instrucţiuni de executat (aici, CS:0x0103).
A doua comandă t a pus în execuţie instrucţiunea mov [DI], AX, prin care conţinutul lui AX este copiat în memorie, anume în segmentul DS = 0x135E la offsetul indicat de registrul DI; în memorie, octeţii lui AX sunt inversaţi ("ZA"), fiind vorba de formatul "little-endian".
Comanda d afişează conţinutul memoriei de la adresa indicată (aici de la adresa DS:0), pe trei coloane: prima coloană conţine adresa primului octet din cei 16 afişaţi pe coloana a doua; ultima coloană redă interpretarea ASCII (înlocuind cu ".", dacă octetul respectiv nu se încadrează în gama codurilor ASCII a caracterelor "tipăribile").
Putem adăuga noi instrucţiuni, de exemplu pentru a înscrie "az" după "ZA" în zona DS:DI:
-a 135E:0105 add AX, 2020 ; 0x41 + 0x20 = 0x61 = 'a'; 0x5A + 0x20 = 0x7A = 'z' 135E:0108 xchg AL, AH ; "exchange" AL cu AH 135E:010A mov word ptr [DI+2], AX 135E:010D -t
add realizează aici operaţia "AX += 0x2020", care transformă octeţii 'A', 'Z' din AH şi respectiv AL în 'a' şi 'z'; apoi, xchg interschimbă între ei AH şi AL (obţinem AX=617A), încât la depunerea în memorie octeţii să apară în ordinea firească "az":
AX=617A BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=135E ES=135E SS=135E CS=135E IP=0108 NV UP EI PL NZ NA PO NC 135E:0108 86C4 XCHG AL,AH -t AX=7A61 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000 DS=135E ES=135E SS=135E CS=135E IP=010A NV UP EI PL NZ NA PO NC 135E:010A 894502 MOV [DI+02],AX DS:0002=9FFF -t…… -d DS:0 F 135E:0000 5A 41 61 7A 00 9A EE FE-1D F0 4F 03 C2 0D 8A 03 ZAaz......O.....
Programul DEBUG a fost creat de Tim Paterson, autorul original al sistemului de operare MS-DOS. Este un instrument uşor de folosit şi care serveşte încă (utilizatorilor individuali, sau în medii universitare) pentru studiul limbajului de asamblare - deşi nu recunoaşte decât setul de instrucţiuni Intel 8086/8087; Microsoft® nu l-a "updatat" - din fericire! - probabil pentru că a preferat să comercializeze propriile instrumente de programare: asamblorul MASM (Microsoft Macro Assembler), compilatorul şi debuggerul CodeView, şi apoi Microsoft Visual Studio.
Zona stivei şi transferul execuţiei; Turbo Debugger
Mecanismul de execuţie a programului are la bază însăşi construcţia CPU, prin specializarea corespunzătoare a anumitor regiştri (denumiţi Instruction Pointer, Stack Pointer, Base Pointer) şi prin prevederea unor instrucţiuni corespunzătoare (CALL, RET, PUSH, POP); sistemul de operare intervine şi el în acest mecanism, măcar pentru faptul că trebuie să aloce fiecărui program care intră în execuţie anumite resurse de memorie, între care o "zonă de cod" şi o zonă de stivă ("stack") - ceea ce iarăşi, se bazează pe existenţa regiştrilor CPU denumiţi Code Segment şi Stack Segment.
Pentru a evidenţia aceste elemente, plecăm de la un program simplu şi-l "urmărim" folosind Turbo Debugger - utilitar inclus în pachetul Borland C++ (pentru Windows; la fel de bine desigur, putem folosi produse similare, pe Linux: "GNU's GDB Debugger", sau un "front-end" precum Insight Debugger).
Click pe butonul Start al Windows-ului, click pe meniul Run... şi lansăm cmd.exe (interpretorul de comenzi din Windows, vechiul COMMAND.COM din DOS; dacă sistemul este instalat cum se cuvine, dispunem de "comanda" debug şi de edit - programul DOS pentru editarea de fişiere text obişnuite). Fie folosind C:\Teste>edit limb2.c, fie folosind comanda C:Teste>copy con limb2.c ("CON" este rezervat în Windows pentru "consolă", permiţând copierea de la tastatură într-un fişier, sau dintr-un fişier pe ecran) - creem fişierul "limb2.c", prezentat în prima imagine de mai jos.
Apelăm BCC, dar folosind opţiunile de compilare -v (include în executabil informaţii necesare debugg-erului, de exemplu tabelul simbolurilor) şi -p (foloseşte convenţia de apelare Pascal, în loc de convenţia de apelare C): bcc -v -p limb2.c. Ca urmare, se obţin fişierele "limb2.OBJ" (care conţine codul obiect) şi executabilul "limb2.exe". Apoi, lansăm Turbo Debbuger, tot de pe linia de comandă C:\Teste>td limb2.c şi obţinem:
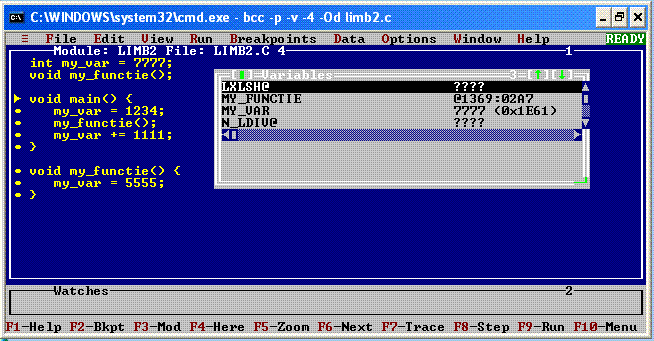
Accesând meniul View, opţiunea Variables - am obţinut fereastra "Variables"; derulând, vedem şi simbolurile noastre: MY_VAR are (la momentul încărcării pentru execuţie) valoarea 7777 = 0x1E61, iar MY_FUNCTIE are adresa 1369:02A7 (codul funcţiei my_functie() este memorat în segmentul 0x1369, începând de la offsetul 0x02A7). Observând ce se afişează în fereastra "Variables", trebuie să fie clar: pe lângă variabilele explicitate în programul respectiv, compilatorul asociază oricărui program, în mod standard, numeroase alte variabile, corespunzând opţiunilor prevăzute pentru compilare, diverselor biblioteci incluse, etc.
Accesând View, CPU obţinem:
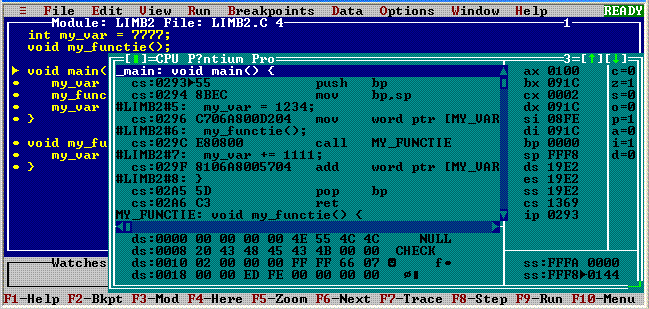
Fereastra CPU are cinci diviziuni ("panel"); se poate trece din una în alta folosind tasta TAB (sau prin click-stânga în panoul respectiv); click-dreapta în interiorul unui panou va deschide un meniu local, cu opţiuni pentru panoul respectiv. Un panou reflectă zona de cod a programului încărcat pentru depanare, un altul redă conţinutul curent al regiştrilor CPU (click-dreapta va permite comutarea între afişarea regiştrilor de 16 biţi AX, etc. şi afişarea regiştrilor extinşi EAX, etc.); un panou redă starea curentă a flagurilor microprocesorului (c corespunde flagului Carry, z corespunde flagului Zero, etc.); panoul în care apare SS ("Stack Segment") reflectă conţinutul curent al zonei stivă asociate programului; în sfârşit, un panou este destinat să redea conţinutul curent al altor zone de memorie (pe figură - conţinutul zonei DS:0).
Maximizăm fereastra CPU; clicând în panoul datelor şi apoi click-dreapta, deschidem meniul local aferent:
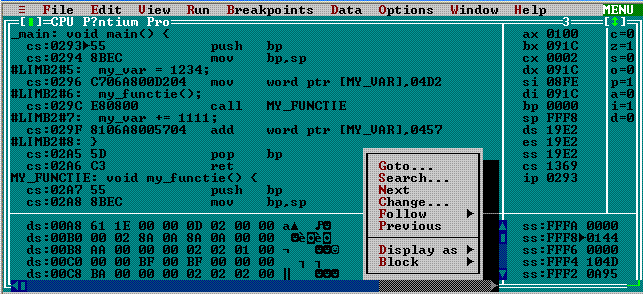
Am folosit opţiunea Goto... indicând ca adresă de poziţionare a panoului DS:0x00A8; aceasta este adresa variabilei "my_var" şi am determinat-o citind în panoul de cod:
#LIMB2#5: my_var = 1234;
cs:0296 C706A800D204 mov word ptr [MY_VAR],04D2
Instrucţiunea codificată la adresa CS:0x0296 este de tipul "încarcă la adresa, data", unde aici adresa=[MY_VAR] şi data=04D2; 0xC706 este partea de "opcode" a instrucţiunii, iar "A800" reprezintă adresa relativă 0x00A8 (în segmentul implicit DS) şi "D204" reprezintă data de încărcat, 0x04D2; deducem că adresa variabilei "my_var" este DS:0x00A8.
În panoul de cod, se foloseşte semnul ▶ pentru a marca instrucţiunea care urmează să fie pusă în execuţie când se apasă tasta funcţională F7 ("Trace"). Punctul de start al execuţiei programului este adresa CS:0293▶ şi vedem pe panoul regiştrilor că IP = 0293. Registrul IP (sau extins, EIP) este menit să păstreze adresa relativă (în cadrul segmentului de cod CS) a instrucţiunii care urmează să se execute; tastând F7, se va executa instrucţiunea de adresă CS:IP şi IP va fi avansat sau poziţionat automat pentru a viza următoarea instrucţiune de executat.
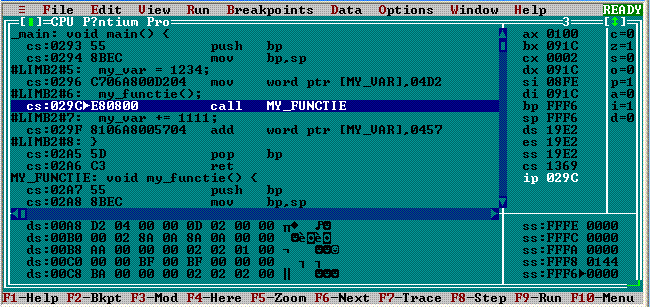
Imaginea de mai sus redă starea programului după ce s-a tastat de trei ori F7; ultima instrucţiune executată a fost cea de la adresa CS:0296 (şi efectul ei se vede în panoul datelor: la adresa DS:00A8 a variabilei "my_var", a apărut valoarea 0x04D2, în locul valorii anterioare 0x1E61). IP = 029C vizează acum instrucţiunea prin care se apelează my_functie(): call MY_FUNCTIE, având codul constituit din octeţii E8, 08, 00. Apelarea funcţiei înseamnă rezolvarea a două probleme:
— activarea codului funcţiei my_functie(), de la adresa CS:02A7; pentru ca my_functie() să intre în execuţie trebuie ca adresa relativă 0x02A7 să fie "adusă" în registrul IP;
— după încheierea executării codului my_functie(), va trebui continuată execuţia funcţiei main(), începând de la adresa CS:029F (a instrucţiunii "my_var += 1111", care urmează în main() după "call MY_FUNCTIE").
Ambele probleme ar fi banale, dacă IP ar putea fi încărcat direct (precum regiştrii obişnuiţi) cu o valoare dată: după IP = 0x02A7 (încărcare directă în IP a adresei MY_FUNCTIE), s-ar declanşa execuţia codului MY_FUNCTIE, urmând ca la încheiere să punem IP = 0x29F, revenind în main(). S-a evitat însă o asemenea "soluţie": a lăsa posibilitatea de a folosi IP la fel cum este folosit orice alt registru (în particular, de a încărca IP cu o adresă oarecare) ar crea riscuri inutile în funcţionarea sistemului, având în vedere rolul cheie dedicat acestui registru (de a păstra mereu adresa relativă a instrucţiunii care urmează a fi executate); pe de altă parte, s-ar încălca subtil principiul adresării relative, atrăgând limitări importante. Registrul IP a rămas un registru privat al CPU, inaccesibil în mod direct (prin instrucţiuni explicite); dar există posibilitatea de a fixa în IP o anumită adresă, operând cu deplasamente faţă de valoarea curentă din IP.
Să lămurim ce înseamnă adresa curentă din IP. În momentul când IP = 029C, se va pune în execuţie instrucţiunea de la această adresă, codificată prin octeţii E8 08 00: se preia şi se decodifică primul octet E8, iar IP este avansat pentru a referi următorul octet din zona de cod (IP = 029D); codul E8 fiind codul unei operaţii de apel de subrutină, urmează să se preia şi următorii doi octeţi, pentru a completa informaţia necesară executării operaţiei (precizând deplasamentul faţă de valoarea curentă IP, a adresei rutinei de apelat); cum la fiecare preluare de câte un octet, IP este automat incrementat pentru a referi următorul octet din zona de cod - rezultă că în final vom avea IP = 029F (indicând - conform rolului preconizat pentru acest registru - adresa următoarei instrucţiuni din zona de cod).
Prin urmare, adresa curentă din IP - faţă de care trebuie operată deplasarea până la adresa rutinei apelate - este în cazul nostru IP = 029F (adresa instrucţiunii următoare celei de apelare). Adunând deplasamentul indicat (de către cei doi octeţi 08, 00 care urmează după codul E8 al operaţiei), deci adunând 0x0008 - vom obţine în IP valoarea 0x029F + 0x0008 = 0x02A7, adică exact adresa subrutinei MY_FUNCTIE de apelat (desigur, calculul deplasamentelor este lăsat de obicei în seama asamblorului).
A doua problemă, problema revenirii în programul apelant, nu poate fi rezolvată decât:
— reţinând adresa de revenire CS:029F şi
— prevăzând o posibilitate de a fixa IP = 0x029F după ce MY_FUNCTIE s-a încheiat.
Ar fi suficient să dispunem de un registru special JP, în care să se salveze valoarea curentă a lui IP (JP = 0x029F), urmând ca după execuţia subrutinei MY_FUNCTIE să se reconstituie IP = JP. Dar o asemenea idee are defectul major că nu permite apeluri imbricate: dacă din main() se apelează functieA() şi din functieA() se apelează functieB(), atunci trebuie revenit din functieB() în functieA(), apoi din functieA() în main() - deci ar aparea necesitatea unui al doilea registru JP…
Soluţia la care s-a ajuns constă în asocierea la program a unei a treia zone în memoria internă, pe lângă zona de date şi zona de cod - numită zona stivei; registrul SS Stack Segment este destinat să păstreze adresa de bază a segmentului de memorie care va fi alocat zonei stivei (sau să o conţină la un moment sau altul). Executând instrucţiunea marcată în imaginea precedentă (tastând F7, nu F8), obţinem:
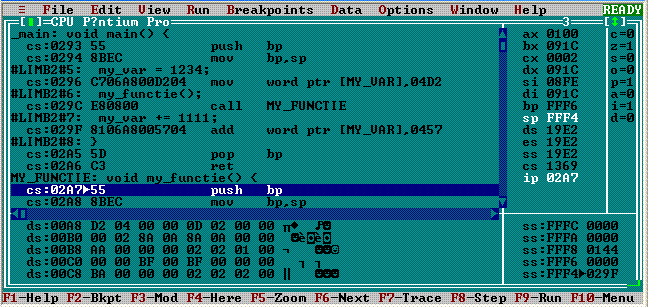
Vedem că s-a depus în zona stivei (la adresa SS:FFF4) adresa 0x029F (drept adresa de revenire din my_functie() în main()) şi că se va trece la execuţia subprogramului MY_FUNCTIE (s-a adunat deplasamentul 0x0008 la valoarea precedentă IP = 0x029F, obţinând IP = 0x02A7, conform calculului redat mai sus); la încheierea execuţiei acestuia (tastăm de cinci ori F7), se va scoate în IP adresa de revenire existentă în zona stivei:
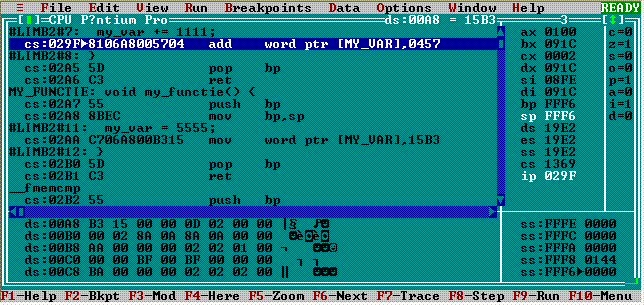
Desigur, după ce IP a preluat adresa de revenire, nu mai este necesară reţinerea ei în zona stivei şi este de dorit eliberarea locului respectiv în vederea unei reutilizări. Având în vedere şi cerinţa de a face posibile apeluri imbricate, rezultă că zona stivei trebuie întreţinută ca o structură Last In First Out; într-adevăr, ordinea de revenire este inversă cu ordinea de apelare (de exemplu, dacă P apelează P1, iar P1 apelează P2, atunci ordinea de apelare este P-->P1-->P2, iar ordinea revenirilor este P2-->P1-->P).
În scopul asigurării acestui mecanism, CPU a fost prevăzut cu registrul SP Stack Pointer, care are rolul de a păstra adresa relativă faţă de baza stivei indicată de SS, a ultimei valori (sau adresă de revenire, după caz) depuse spre păstrare în zone stivei; când adresa de revenire indicată de SP este scoasă în IP, ea este şi "eliminată" din zona stivei - în sensul că SP este poziţionat automat pentru a indica valoarea precedentă celei tocmai "ieşite" din stivă.
Pentru a evita restricţionări de genul "zona de cod sau de date se poate extinde numai până la cutare adresă, fiindcă de la această adresă începe zona stivei" - s-a optat pentru o construcţie descrescătoare a zonei stivei; la depunerea în stivă, SP scade cu 2 (dacă se depune un "word"), iar la "scoatere" din stivă SP creşte cu 2 (indicând precedenta valoare depusă).
Pentru depunerea unei adrese în zona stivei (respectiv pentru scoaterea ultimei valori depuse), CPU a fost prevăzut cu instrucţiuni care, în limbajele de asamblare intră în cadrul mnemonicei PUSH (respectiv POP). Efectul vizat pentru o instrucţiune "push REG" este următorul: se decrementează SP cu 2, pentru a indica locul noii valori depuse drept "ultima" în zona stivei şi în locul indicat acum de SP, se depune conţinutul registrului REG. Iar "pop REG" are efectul următor: valoarea indicată de SP (adică valoarea existentă în stivă la offsetul SP faţă de baza SS; în panoul stivei ea este marcată prin ▶) este transferată în REG şi apoi SP este incrementat cu 2, indicând precedenta valoare existentă în zona stivei.
Efectul instrucţiunii call P1 este următorul: se decrementează SP cu 2, se depune în locul indicat acum de SP adresa curentă din IP (în cazul nostru - 0x029F, care este adresa de revenire), apoi se determină adresa la care se face transferul execuţiei (adunând la IP deplasamentul corespunzător) şi aceasta devine noua valoare a lui IP.
După încheierea execuţiei subprogramului apelat astfel, urmează să se "scoată" adresa de revenire din zona stivei, revenind în programul apelant; să observăm o ultimă problemă importantă: cum anume poate şti CPU că execuţia subprogramului este încheiată şi că urmează să se revina la adresa care a fost salvată în zona stivei prin instrucţiunea de apel "call"? Pentru rezolvarea problemei încheierii execuţiei unui subprogram şi revenirii în programul apelant s-au prevăzut microprocesorului instrucţiuni care în limbajele de asamblare au mnemonica RET (de la RETurn). O instrucţiune RET încheie execuţia subprogramului prin faptul că determină transferarea în IP a adresei indicate de SP (iar SP urcă cu 2) - ceea ce înseamnă că execuţia va continua de la noua adresă adusă în CS:IP (şi implicit, subprogramul şi-a încheiat execuţia, revenindu-se în programul apelant).
În general, fiecare program deţine în cursul execuţiei sale, o zonă stivă proprie; însă, pentru gestionarea stivei proprii - fiecare program va trebui să folosească aceiaşi doi regiştri, SS şi SP; rezultă că în principiu, un program care întrerupe execuţia în curs a unui alt program, va trebui să salveze în prealabil valorile găsite de el în SS şi în SP (folosind apoi SS şi SP pentru propria execuţie), urmând ca la încheierea intervenţiei sale să reconstituie valorile SS şi SP proprii programului pe care l-a întrerupt. Apelarea unui subprogram este în mod implicit, o întrerupere a execuţiei programului apelant - astfel că fiecare program apelat trebuie să salveze măcar SP-ul corespunzător apelantului (urmând a-l reconstitui înainte de RET); se vede într-adevăr, pe imaginile de mai sus că şi main() şi my_functie() debutează fiecare prin push BP; mov BP, SP şi încheie fiecare prin pop BP; ret; astfel, fiecare (folosind registrul BP Base Pointer) salvează în zona stivă şi în final reconstituie, adresa SP corespunzătoare "cadrului-stivă" al apelantului.
Observaţii
— Este de aşteptat ca toate aceste instrucţiuni de lucru cu zona stivei (push, pop, call, ret) să necesite mai mult timp pentru a fi realizate, în comparaţie cu acele instrucţiuni care angajează doar regiştrii interni - dat fiind că ele implică accesarea prin intermediul magistralelor, a unei zone de memorie externe microprocesorului. Este tentantă folosirea zonei stivei drept zonă de salvări temporare a unor rezultate intermediare - dar ca timp, va fi mai economic de efectuat astfel de memorări temporare nu în zona stivei, ci în regiştrii interni găsiţi disponibili în momentul respectiv.
— Dacă există multe subprograme de apelat (inclusiv, apelarea multiplu repetată a unui subprogram), timpul de execuţie a programului creşte în mod artificial, datorită cumulării timpilor necesari execuţiei instrucţiunilor CALL; este un timp consumat nu pentru realizarea propriu-zisă a scopurilor programului, ci pentru pasarea sarcinilor către executanţi! Este de semnalat însă şi posibilitatea (dar nu în limbaj de nivel înalt) de "programare fără CALL" (dar cu funcţii, sau subprograme), evitând timpul suplimentar cerut de execuţia instrucţiunilor de intrare şi ieşire în/din subprogram; pentru aceasta, codul programului ar trebui să fie o stivă "PROG" de adrese ale subrutinelor ce vor trebui apelate, adrese stivuite în ordinea apelării lor; execuţia programului constă atunci în execuţia succesivă a subrutinelor din stiva "PROG", declanşată prin forţarea initială SP = PROG şi execuţia imediată a unui RET - ca urmare, IP va prelua prima adresă înregistrată în zona "PROG", determinând execuţia subrutinei respective, iar SP va coborî cu 2; încheierea execuţiei subrutinei (RET-ul acesteia) va determina scoaterea din stiva "PROG" a următoarei adrese şi activarea subrutinei respective, SP coborând încă cu 2 şi referind adresa subrutinei care va prelua controlul după RET-ul celei în curs de execuţie, ş.a.m.d. Această idee - metoda salturilor indirecte - este folosită de exemplu, pentru scrierea programelor interpretoare de comenzi (a vedea de exemplu, COMMAND.COM din DOS 5.0, dezasamblând primii 24 octeţi).
Zona stivei şi transferul parametrilor
Zona stivei este utilizată ca zonă de date în două situaţii importante:
— pentru comunicarea parametrilor către un subprogram;
— drept zonă a datelor locale unui subprogram.
De asemenea, zona stivă serveşte şi pentru salvarea conţinutului regiştrilor, în situaţia când execuţia programului urmează să fie întreruptă prin activarea unei subrutine care şi ea, are nevoie să utilizeze regiştrii respectivi.
De obicei, porţiunea din zona stivă a programului care cuprinde parametrii transmişi de către programul apelant şi variabilele locale considerate în subprogramul respectiv este denumită cadrul stivă al subprogramului; de fapt, cadrul stivă asociat unui subprogram include totdeauna încă două elemente (cum vom vedea mai încolo).
Să presupunem că avem un subprogram P1(x, y) unde x şi y sunt parametrii care urmează să fie primiţi de la programul care apelează P1; în vederea apelării lui P1, programul apelant va depune în zona stivei valorile respective (folosind PUSH) şi apoi va folosi CALL P1. Deci la activarea subprogramului P1, zona stivei are următoarea descriere:
SP_vechi —> ---- (partea superioară a stivei, până la momentul iniţierii apelului P1)
—> primul parametru transmis lui P1 (sau x, sau y)
—> al doilea parametru transmis (y, respectiv x)
SP_nou —> adresa de revenire în programul apelant (după execuţia lui P1)
P1 ar putea accesa valorile transmise lui drept parametri, adăugând un deplasament la valoarea curentă SP_nou a registrului SP: al doilea parametru este la adresa SP + 2, iar primul la adresa SP + 4; parametrul este într-adevăr indicat de [SP + deplasament], dar valoarea respectivă trebuie nu atât indicată, cât preluată ca atare de către subprogram (adică trebuie să se dispună de o instrucţiune "mov DEST, [REG]" prin care să se transfere la DEST valoarea a cărei adresă o conţine REG; nu pentru toţi REG, este cablată o astfel de instrucţiune - cel puţin nu pentru oricare CPU).
Desigur că revenirea din P1 în programul apelant va trebui să însemne nu numai recuperarea adresei de revenire indicată de SP_nou, dar şi eliberarea imediată a locului ocupat în stivă de valorile transmise, devenite inutile. Această curăţare a stivei se va putea face adăugând la SP_nou deplasamentul necesar pentru a ajunge la nivelul SP_vechi.
CPU dispune de instrucţiuni ADD SP, n şi SUB SP, n prin care se avansează SP cu n octeţi, într-un sens sau în celălalt; ADD SP, n "elimină" din stivă n octeţi, în sensul că poziţionează SP "deasupra" lor, iar SUB SP, n rezervă (sau alocă) în stivă n octeţi, poziţionând SP "dedesubtul" lor (desigur, ADD şi SUB sunt mnemonicele generale pentru adunare şi scădere; dar cu referire la SP, ele capătă semnificaţia precizată - de a "elimina" din stivă şi de a "rezerva" loc în stivă; eliminarea celor n octeţi din stivă înseamnă doar că ei nu vor mai fi sub controlul programului respectiv, putând fi ulterior suprascrişi de un alt program care ar căpăta temporar controlul).
Dacă P1 prevede nişte variabile locale acestea vor putea fi alocate "dedesubtul" lui SP_nou: în cadrul lui P1 se va coborî SP cu numărul de octeţi necesar variabilelor locale (SUB SP, n), urmând ca în zona rezervată astfel să se păstreze valorile curente ale acelor variabile; apoi, imediat înainte de a reveni în programul apelant, zona variabilelor locale va fi "eliminată" prin ADD SP, n (încât SP revine la nivelul SP_nou care indică adresa de revenire).
Dar gestionarea stivei în acest mod (prin simpla manevrare a valorii SP curente) se va complica în situaţia apelurilor imbricate. Dacă P1 prevede variabile locale, atunci acestea trebuie să fie accesibile oricărui subprogram P2 apelat din P1, ca şi oricărui subprogram P3 apelat din P2. Ori din cadrul lui P3 nu se va mai putea calcula deplasamentul necesar pentru a indica variabilele locale din cadrul stivă corespunzător lui P1 (decât cunoscând, la nivelul P3, mai multe informaţii care de fapt sunt străine de activitatea specifică lui P3: dimensiunea zonelor de parametri şi de variabile locale ale "strămoşilor" lui P3).
Prin urmare, se impune ca la nivelul subprogramului apelat (în cadrul stivă asociat acestuia) să fie înregistrată o informaţie despre nivelul ierarhic superior, adică despre nivelul la care se află în zona stivei, cadrul stivă al programului apelant. Realizarea cea mai simplă şi cea mai sigură a acestei idei constă în a considera împreună cu SP, încă un registru - să-l numim REG (în realitate este vorba de registrul Base Pointer). Acesta va memora nivelul în zona stivei, al cadrului asociat subprogramului (sau chiar "programului principal" - la urma urmei şi acesta este "apelat", anume din mediul de operare - ceea ce ar reveni la o iniţializare REG = 0).
Pe parcursul execuţiei unui subprogram, REG păstrează adresa cadrului stivă al acestui subprogram (permiţând şi accesarea comodă a valorilor înscrise în cadrul stivă respectiv). La activarea unui subprogram, acesta va adăuga în cadrul stivă propriu valoarea existentă în REG (adică adresa cadrului stivă a programului care l-a apelat) şi va înregistra în REG adresa propriului cadru stivă. În finalul execuţiei subprogramului, înainte de a permite revenirea în programul apelant, subprogramul va trebui să reconstituie în REG valoarea salvată la debut, caracteristică programului în care se revine.
Pentru a permite (pe lângă referirea de cadre stivă) şi obţinerea uşoară a valorilor existente în cadrul stivă respectiv, REG trebuie înzestrat cu sarcina realizării unor instrucţiuni de tip "mov DEST, [REG]" - prin care să se transfere la DEST valoarea de la adresa conţinută de REG. Registrul SP de exemplu, este scutit de această sarcină: nu este cablată o instrucţiune "mov DEST, [SP]" (sarcina aceasta trebuind să fie efectuată în două părţi, de exemplu prin mov BX, SP şi apoi mov DEST, [BX]).
Drept REG, s-a adăugat un registru special, denumit BP Base Pointer. Rolul lui REG ar putea fi preluat de asemenea, de registrul BX, fiind cablate instrucţiunile mov DEST, [BX] şi mov DEST, [BP] (pe ultimele generaţii de microprocesoare Intel sunt cablate instrucţiuni mov DEST, [REG] şi pentru alţi regiştri generali - AX, CX, DX).
Pentru o exemplificare, să considerăm acest schelet de program Pascal:
program P;
var a, b: integer;
procedure P1(x, y: integer);
var i, j: integer;
begin --- end;
begin
---
P1(100, 567);
a := 1;
---
end.
Apelarea procedurii P1 se realizează prin următoarea secvenţă:
push 100 ; transmite valoarea primului parametru din lista de parametri push 567 ; transmite valoarea pentru al doilea parametru call P1 ; memorează adresa de revenire (la "a:=1") şi predă controlul lui P1
Parametrii pot fi transmişi de la stânga spre dreapta - întâi 100, apoi 567 - adică folosind convenţia Pascal, sau de la dreapta spre stânga în convenţia C.
Ca urmare a execuţiei secvenţei de mai sus, se va constitui în segmentul de memorie cu adresa de bază dată de SS, cadrul stivă asociat procedurii P1:
| adresă | conţinut | |
|---|---|---|
| ---- | cadrul stivă al programului apelant, indicat | |
| SP = s0 = SP_vechi | ---- | de valoarea curentă existentă în REG (BP) |
| SP = s1 = s0 - 2 | 100 | valoarea pentru x |
| SP = s2 = s1 - 2 | 567 | valoarea pentru y |
| SP = s3 = s2 - 2 | adresa instrucţiunii "a:=1" | adresa de revenire |
|
P1 completează imediat acest cadru, cu adresa REG specifică cadrului stivă al programului apelant: | ||
| SP = s4 = s3 - 2 | REG (în speţă BP) | după push BP |
|
şi apoi fixează în REG adresa propriului cadru-stivă: | ||
| mov REG, s4 | mov BP, SP | |
De-acum încolo, P1 va putea referi propriul cadru stivă folosind REG (în speţă, BP): la nivelul [REG + 2] se află adresa de revenire, la nivelul [REG + 4] - valoarea lui y, etc. Valoarea transmisă pentru x se va putea obtine de exemplu, cu mov AX, [BP + 6].
Observăm în textul=sursă că procedura P1 are variabilele locale i, j:integer;. P1 realizează alocarea necesară pentru acestea prin sub SP, 4 determinând extinderea cadrului stiva pentru a păstra valorile variabilelor locale i, j:
s5 = s4 - 2 rezervat pentru valoarea curentă a lui i SP = s6 = s5 - 2 rezervat pentru valoarea curentă a lui j
Accesarea variabilelor locale i, j se va realiza folosind de asemenea REG: mov AX, [BP - 2] va transfera valoarea curentă i în AX, iar mov [BP - 4], 1234 va realiza atribuirea j := 1234.
La încheiere, înainte de a permite revenirea în programul apelant, P1 trebuie să reconstituie în REG valoarea proprie programului apelant (secvenţa "epilog"):
mov SP, BP ;SP revine la nivelul s4, "eliberând" implicit zona variabilelor locale pop BP ;REG reia valoarea înscrisă la s4, iar SP ajunge la nivelul s3
La nivelul s3 se află adresa de revenire în programul apelant şi RET ar determina această revenire (la adresa instrucţiunii "a := 1"). Dar în convenţia Pascal "curăţirea" stivei (de parametrii x, y deveniţi inutili) revine tot subprogramului şi anume se foloseşte instrucţiunea RET 4 - prin care se pune IP = adresa de revenire, dar simultan se incrementează SP cu 4, revenind deci la SP = s0 şi "eliminând" astfel parametrii x, y (am presupus că integer ocupă 2 octeţi).
În schimb, convenţia C prevede curăţirea stivei de parametrii transmişi nu de către subprogramul apelat, ci de către apelant (care oricum, "ştie" câţi şi ce fel de parametri a transmis); deci P1 şi-ar încheia activitatea cu RET, redând controlul către P, urmând ca acesta să elimine parametrii fie cu add SP, 4 fie cu pop CX ("descarcă" primul parametru) şi pop CX ("descarcă" şi al doilea argument).
Observaţii
➀ Codul unui program care conţine multe apeluri de subprograme va fi mai scurt dacă este generat pe baza convenţiei Pascal şi nu pe baza convenţiei C (întrucât secvenţa de descărcare a stivei este conţinută de subprogramul apelat în cazul Pascal, pe când în celălalt caz ea este amplasată în programul apelant, după instrucţiunea CALL de apelare a subprogramului).
➁ Dacă P1 ar apela la rândul său, P2(a), atunci compilatorul ar constitui cadrul stivă corespunzător lui P2 astfel:
s7 = s6 - 2 parametrul a s8 = s7 - 2 valoarea REG (BP) s9 = s8 - 2 adresa de revenire din P2 în P1
adică ar adăuga drept parametru şi valoarea REG proprie cadrului stivă al lui P1; aşa, se va permite lui P2 accesarea variabilelor locale ale lui P1. După "prologul" din P2: push BP; mov BP, SP care determină completarea cadrului stivă cu:
(REG=BP = ) SP = s10 = s9 - 2: [REG] (valoarea din BP)
valoarea variabilei locale x din P1 se va putea accesa astfel:
mov BX, [BP + 4] (BX = valoarea REG din P1) mov AX, [BX] (AX = valoarea lui x din P1)
➂ Dacă subprogramul apelat P1 ar face parte dintr-un alt segment de cod decât cel care corespunde programului apelant (apelare far), atunci apelarea lui P1 necesită şi modificarea registrului CS, astfel că valoarea CS a programului apelant trebuie şi ea salvată:
push primul parametru push al doilea parametru push CS call P1
Aceasta determina creşterea cu 2 a cadrului stivă al lui P1, deci adresarea prin BP va fi cu +2 faţă de cazul near prezentat mai sus (BP + 2 împreună cu BP + 4 indică adresa CS:IP de revenire; BP + 6 referă al doilea parametru şi [BP + 8] conţine valoarea primului parametru).
➃ În cele de mai sus, am considerat implicit ca adresa de revenire (depusă de apelant în stivă, înainte de a şi pasa controlul executantului apelat) ar avea dimensiunea de 2 octeţi (în cazul near), sau de 4 octeţi (în cazul far). Poate exista însă şi un alt caz: dacă segmentul de cod are atributul USE32 (deci el este referit cu un deplasament de tip dword), atunci se foloseşte registrul extins EIP drept "instruction pointer" şi drept urmare, adresele de revenire (înapoi în segmentul de 32 biţi) au ele însele, câte 4 octeţi; deci în acest caz (posibil de la I80386 încoace), adresa de revenire are 4 octeţi în cazul near şi 4 + 2 = 6 octeţi în cazul far.
Investigarea setului de instrucţiuni CPU
Instrucţiunile pot fi împărţite în mai multe tipuri; într-un acelaşi grup, variază tipul operanzilor, sau modul de accesare a acestora. Codul de instrucţiune trebuie să reflecte categoria instrucţiunii si să precizeze, într-un mod sau altul, operanzii necesari. Tipul de instrucţiune este codificat în cadrul primului octet, sau uneori şi în cadrul celui de-al doilea octet; biţii rămaşi disponibili din primul şi al doilea octet, precum şi restul de octeţi (din secvenţa recunoscută în ansamblul ei, drept instrucţiune) furnizează de regulă informaţiile necesare privind tipul operanzilor şi locul unde se află aceştia, sau eventual chiar valorile lor.
Să considerăm de exemplu, operaţia de a înregistra în stivă conţinutul unui registru. I80x86 dispune în acest scop de instrucţiuni codificate pe câte un singur octet, în cadrul căruia se reprezintă atât tipul operaţiei realizate - push: se descreşte SP cu 2 şi la adresa SS:SP rezultată se copiază operandul - cât şi registrul care conţine valoarea de depus în vârful stivei:
0 1 0 1 0 b2 b1 b0 tipul operaţiei: PUSH = 010102 operand: registrul codificat pe ultimii 3 biţi din octet
Valorile posibile ale acestui octet sunt 0x50 (când b2b1b0 = "000"), 0x51, ..., 0x57 (când b2b1b0 = "111") - deci această categorie cuprinde 8 instrucţiuni. Putem angaja programul debug din Windows, pentru a constata că formatul instrucţiunilor PUSH cu operand registru se reduce la octetul de cod prezentat mai sus şi pentru a determina codurile de 3 biţi ale regiştrilor: trebuie să introducem în memorie secvenţa de octeţi 0x50, 0x51, ..., 0x57 (folosind comanda E, "Enter") şi să dezasamblăm apoi zona respectivă (comanda U, "Unassemble"):
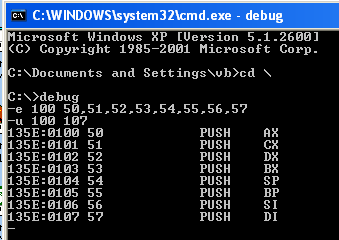
Vedem astfel corespondenţa următoare:
| adresa | conţinut | instrucţiune | b2b1b0 | registrul |
|---|---|---|---|---|
| 135E:0100 | 50 | push AX | 000 | AX |
| 135E:0101 | 51 | push CX | 001 | CX |
| 135E:0102 | 52 | push DX | 010 | DX |
| 135E:0103 | 53 | push BX | 011 | BX |
| 135E:0104 | 54 | push SP | 100 | SP |
| 135E:0105 | 55 | push BP | 101 | BP |
| 135E:0106 | 56 | push SI | 110 | SI |
| 135E:0107 | 57 | push DI | 111 | DI |
Se confirmă astfel că formatul instrucţiunilor PUSH registru constă dintr-un singur octet, în care primii 5 biţi "01010" indică operaţia respectivă (depunere pe stivă a conţinutului unui registru de 16 biţi care nu este un registru de segment), iar ultimii 3 biţi corespund operandului; deducem si codificarea regiştrilor AX, CX, DX, BX, SP, BP, SI, DI (8 regiştri, codificaţi sau adresaţi prin "000", "001", ..., "111").
Dacă este cazul să studiem şi efectul instrucţiunii, putem asambla (comanda A, "Assemble") o instrucţiune de încărcare în AX şi una PUSH AX, folosind apoi comanda T "Trace" şi eventual D "Dump":
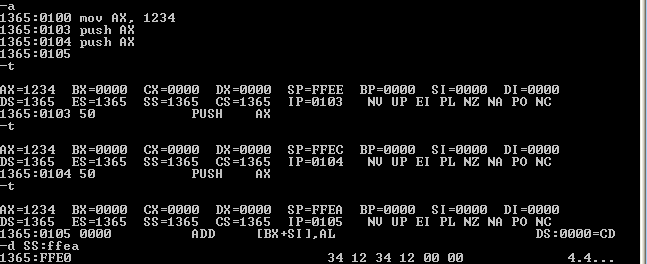
După prima comandă t, vedem că AX a fost încărcat cu 0x1234 şi SP cu 0xFFEE; după următorul t (executând PUSH AX de la adresa CS:0x0103) vedem că SP a coborât cu 2 (SP = 0xFFEC); după execuţia celui de-al doilea PUSH rezultă SP = 0xFFEA. Prin d SS:ffea, vedem conţinutul stivei de la offsetul 0xFFEA: două secvenţe de doi octeţi 0x34, 0x12 (reprezentând "little-endian" valoarea 0x1234 din AX).
Pentru a găsi codul-maşină asociat instrucţiunilor prin care se depune pe stivă conţinutul unui registru de segment, putem proceda invers faţă de maniera în care ne-am ocupat mai înainte de PUSH AX: asamblăm (folosind A) instrucţiunile corespunzătoare (push DS, push CS, etc.) şi apoi dezasamblăm (comanda U) zona instrucţiunilor introduse. Găsim astfel, următoarea corespondenţă:
instrucţiune cod în binar
push ES 0x06 00000110
push CS 0x0E 00001110
push SS 0x16 00010110
push DS 0x1E 00011110
Comparând reprezentările binare ale codurilor, deducem că formatul instrucţiunilor PUSH pentru cazul când operandul este într-un registru de segment constă dintr-un octet cu şablonul binar 000b4b3110; rezultă totodată codificarea asociată regiştrilor de segment ES "Extra Segment", CS "Code Segment", SS "Stack Segment" şi DS "Data Segment".
Unele instrucţiuni au efect numai asupra operandului destinaţie; de exemplu, instrucţiunea mov AX, BX determină înlocuirea conţinutului existent în AX cu acela din BX - fără a modifica "sursa" BX şi fără nici un alt efect secundar (în particular, nu este afectat nici într-un fel registrul flagurilor).
Să considerăm însă o instrucţiune aritmetică, de exemplu v := v + 100 în Pascal, sau v += 100 în C şi analog, ADD AL, 100 în limbajul de asamblare; în principiu, se adună valoarea 100 cu valoarea existentă în variabila v şi respectiv în registrul AL şi rezultatul adunării devine noua valoare din v şi respectiv din AL.
De data aceasta, efectuarea operaţiei trebuie să ţină seama de tipul destinaţiei: dacă v este de tip byte (ca şi AL) şi valoarea iniţială din v este 200,atunci rezultatul ar fi 200 + 100 = 300 - valoare care nu aparţine tipului byte (nu "încape" pe un octet); se va reţine atunci în v (în AL) octetul low al valorii 300 = 1*28 + 44 (deci x <— 44, respectiv AL <— 44).
La nivelul "high" al limbajului (în Pascal, de exemplu) nu apar alte efecte (decât trunchierea menţionată, sau eventual întreruperea execuţiei prin Error: Range check error); în schimb, ADD AL, 100 (la nivelul de limbaj "low") va fi totdeauna executată, posibil cu trunchierea la octetul low al valorii-rezultat; în plus, bitul Cf "Carry flag" (CY în notaţia din debug) din registrul indicatorilor de stare (registrul flagurilor) va fi setat (comutat pe valoarea 1) dacă rezultatul operaţiei depăşeşte capacitatea registrului destinaţie:
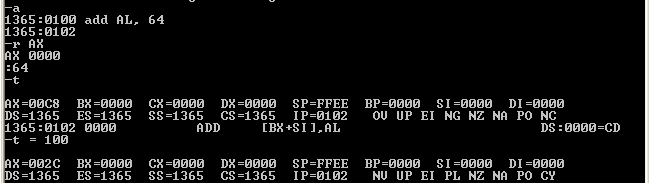
S-a asamblat instrucţiunea add AL, 64 (avem 0x64 = 6*16 + 4 = 100); apoi s-a vizualizat conţinutul registrului AX (r AX) şi s-a fixat în AX valoarea 0x64; apoi s-a executat de două ori succesiv, instrucţiunea de la adresa CS:0x100.
După primul t (prima execuţie) vedem că AX = 0x00C8 (adică AL = 0xC8), ca efect al operaţiei 100 + 100 = 200 = 0xC8; iar flagul Carry este resetat (= 0, ceea ce debug indică prin "NC"—Not Carry) - ceea ce înseamnă că nu s-a produs, prin operaţia executată, depăşirea capacităţii registrului destinaţie AL. Mai vedem de exemplu, că indicatorul de zero ("NZ"—Not Zero în debug) este şi el resetat, semnificând că rezultatul operaţiei nu a devenit zero.
La repetarea executării instrucţiunii (prin t = 100, nu prin t care ar fi pus în execuţie următoarea instrucţiune, de la offsetul IP = 0x0102) - deci după ce AL conţine valoarea 200 - vedem că a rezultat AL = 0x2C = 44 (= 300 mod 28) şi flagul Carry a fost setat, semnalând depăşirea capacităţii destinaţiei AL (registrul AH rămâne nemodificat, bitul de depăşire fiind "preluat" de Carry şi nu de "prelungirea" AH a lui AL).
Ţinând seama de principiul firesc, ca toate instrucţiunile dintr-o aceeaşi categorie (aceeaşi operaţie şi acelaşi tip de operand) să fie executate într-un acelaşi mod — putem conchide numai pe baza singurului exemplu analizat mai sus, că efectul instrucţiunilor ADD reg8, _octet unde reg8 este oricare registru de 8 biţi, iar _octet este orice valoare de 8 biţi, constă în:
reg8 <— (reg8 + _octet) MOD 256, Cf <— (reg8 + _octet) DIV 256 ∊ {0, 1} Zf <— 1 ⇔ reg8 + _octet = 28 = 10256 (pot fi afectate şi alte flaguri)
O subtilitate: execuţia de instrucţiuni "nerecunoscute"
debug poate fi utilizat astfel - cum se vede pe exemplele redate mai sus - pentru a investiga toate categoriile de instrucţiuni ale microprocesorului Intel 8086. Este adevărat că debug nu recunoaşte mnemonicele de instrucţiuni (şi de regiştri extinşi) ulterioare lui I8086 - de exemplu introducând sub comanda a mov EBX, 12345678 se obţine "Error" (registrul extins "EBX" nu este recunoscut).
Dar să încercăm o distincţie: debug nu recunoaşte instrucţiunea în limbaj de asamblare (şi deci n-o poate "converti" în cod-maşină), dar pune în execuţie orice cod-maşină recunoscut de către microprocesor! Ar fi suficient să cunoaştem modalitatea prin care se face distincţia între regiştrii obişnuiţi şi cei extinşi (pe care nu-i recunoaşte), pentru a putea introduce instrucţiunile nu în limbaj de asamblare (că nu ar fi recunoscute), ci direct prin octeţii de cod-maşină corespunzători - putând astfel studia cu debug şi instrucţiuni specifice microprocesoarelor ulterioare lui I8086.
Am evidenţiat anterior că INTEL a adoptat consecvent principiul compatibilităţii în jos; trecerea la un nou microprocesor (inclusiv extinderea regiştrilor) a însemnat o completare (şi nu o structură complet nouă) a setului de instrucţiuni. Aşa se face că diferenţa dintre instrucţiunile I8086 şi cele care ar angaja regiştrii extinşi se face pur şi simplu prin prefixarea codului instrucţiunii cu un octet cu valoarea constantă 0x66, indicând că operandul respectiv este de tip dword (pe 32 de biţi); de exemplu, am văzut mai sus că push BX are codul 0x53 - atunci, push EBX are codul de doi octeţi: 0x66, 0x53.
Următoarea imagine demonstrează valabilitatea distincţiei sugerate mai sus, arătând că debug se poate folosi şi pentru a investiga instrucţiuni ulterioare lui I8086.
debug nu a recunoscut EBX, când s-a încercat asamblarea instrucţiunii mov EBX, 0x12345678. Introducând totuşi codul instrucţiunii: 66 BB 78 56 34 12, vedem că t o pune în execuţie (în BX apare valoarea 0x5678; în EBX ar trebui să avem 0x12345678). Am introdus apoi şi codul 66 53 pentru push EBX, încât valoarea 0x12345678 ar trebui să fie depusă pe stivă; am adăugat instrucţiunile pop DX şi pop AX, pentru a descărca de pe stivă în DX şi AX. Vedem după execuţia ultimelor trei instrucţiuni (prin t 3) că DX a preluat de pe stivă valoarea 0x5678, iar AX a preluat 0x1234 - ceea ce arată că valoarea salvată pe stivă a fost într-adevăr, aceea care s-a dorit iniţial să fie încărcată în registrul extins EBX. Deci instrucţiunea "nerecunoscută" mov EBX, 0x12345678 a fost executată, trebuind doar să fie introdusă prin codul ei (nu prin mnemonice).
De fapt, acest comportament (nu înţelege instrucţiunea, dar o execută) chiar n-ar trebui să surprindă… (nu întâlnim mereu această situaţie?). Comenzile a şi t sunt independente; debug asamblează instrucţiunea dată în limbaj de asamblare dacă o recunoaşte (pe baza tabelelor proprii de translatare); în schimb, t pune în execuţie codul indicat de CS:IP şi nu debug execută codul, ci microprocesorul (nu debug trebuie să recunoască acel cod, ci microprocesorul).
Un exemplu de programare în limbaj de asamblare
În şcoli se folosesc compilatoarele de la Borland, cu licenţă comercială specifică (de fapt, compilatoarele sunt implicate numai la nivelul Integrated Development Environment pentru DOS/Windows). Borland a introdus pe piaţă şi asamblorul TASM Turbo Assembler, interoperabil în general cu celelalte produse Borland. Există o versiune "free" Borland C++ v.5.5, care include compilatorul bcc32.exe, linker-ul tlink32.exe, etc. - dar nu şi TASM (trebuie achiziţionat separat).
Alternativa achiziţionării de software comercial este investigarea zonei free software…
nasm Netwide Assembler este un asamblor pentru Intel x86 (şi pentru mai multe sisteme de operare), sub licenţa LGPL (la fel de exemplu, ca şi Mozilla). Pentru Windows, se poate descărca nasm-2.02-dos.zip DOS 32-bit binaries, de la //sourceforge.net/projects/nasm; după dezarhivare, se poate consulta fişierul text "nasmdoc", pentru documentare asupra instalării şi folosirii asamblorului.
Gas The GNU Assembler este asamblorul folosit de GNU. Gas (ca executabil - as) este "back-end"-ul implicit pentru GCC (colecţie GNU de compilatoare pentru C/C++, Java, Fortran, Ada, şi alte limbaje de programare), fiind utilizat între altele şi pentru a compila Linux-ul. Multe programe GNU au fost portate pe Microsoft Windows, Mac OS X şi chiar pe Unix (constatându-se adesea că sunt mai bune decât programele comerciale pe care le înlocuiesc); de exemplu, Cygwin sau Mingw portează diverse pachete GNU - în particular GCC şi implicit, Gas - pe un sistem Windows.
În cele ce urmează încercăm să vizăm pe un exemplu concret, ambele asambloare: Gas şi respectiv, nasm; descriem şi folosim diverse categorii de instrucţiuni CPU/FPU, câteva apeluri de sistem (pentru DOS/Windows, respectiv Linux), diverse directive de asamblare şi desigur - pe cât se poate - ilustrăm sau clarificăm diverse chestiuni fundamentale (reprezentarea numerelor, codul ASCII, etc.; elaborarea şi dezvoltarea programelor).
Structura unui program în limbaj de asamblare
Într-un limbaj de nivel înalt, un program este format de obicei din declaraţii globale (cu sau fără iniţializare), o funcţie principală (care conţine punctul de începere a execuţiei programului) şi diverse alte funcţii; tot aşa, un program în limbaj de asamblare conţine o secţiune de date iniţializate, una de date neiniţializate (pentru care doar se alocă memorie) şi o secţiune de cod (desigur, directivele prin care se introduc aceste secţiuni pot să difere, în funcţie de asamblorul folosit):
| Gas | Nasm | |
|---|---|---|
| .section .data | section .data | începe o secţiune pentru date iniţializate |
| var1: .int 1234 | var1 dw 1234 | int var1; (în C/C++) |
| array: .byte 1, 2, 3, 4 | array db 1, 2, 3, 4 | char array[]={1,2,3,4}; |
| nume: .string "Enter Your Name: " | nume db "Enter Your Name: " | char nume[]="Enter Your Name: "; |
| .section .bss | section .bss | începe o secţiune pentru alocare de date |
| .lcomm buffer, 100 | buffer resb 100 | rezervă 100 bytes de memorie |
| .section .text | section .text | începe secţiunea de cod (sau "text") |
| .globl _start | global _start | declară punctul de intrare în execuţie |
| _start: | _start: | adresa de început a execuţiei |
| movl $nume, %edx | mov edx, nume | instrucţiunile programului... |
Asamblorul primeşte un astfel de fişier şi creează codul obiect, prin translatarea mnemonicelor de instrucţiuni în cod-maşină specific microprocesorului destinaţie şi prin transformarea în adrese relative a simbolurilor (etichete) existente în programul sursă; în codul-obiect, secţiunile sunt nişte blocuri disjuncte de adrese consecutive, având fiecare adresa de bază zero (nu corespund unor adrese reale). Fişierul-obiect trebuie transmis (direct sau indirect) unui program linker, care va constitui fişierul executabil, relocatând adresele încât acestea să corespundă unor adrese reale şi adăugând fişierului obiect un header cu informaţii despre secţiunile programului (adresă, dimensiune, etc.).
Sintaxa de asamblare AT&T şi sintaxa Intel
Nasm foloseşte sintaxa Intel, ca şi multe alte asambloare; Gas foloseşte sintaxa AT&T, standard pe sistemele Unix (dar Gas oferă suport şi pentru sintaxă Intel, prin directiva de asamblare .intel_syntax; iar pe de altă parte, există programe care convertesc dintr-o sintaxă în cealaltă).
Formatul instrucţiunilor (cei doi operanzi sunt inversaţi)
în sintaxa AT&T: Mnemonică Sursă, Destinaţie,
în sintaxa Intel: Mnemonică Destinaţie, Sursă.
În sintaxa AT&T operanzii registru trebuie prefixaţi cu % (mov %eax, %ebx), iar operanzii imediaţi (numere constante, adrese constante) trebuie prefixaţi cu $ (mov $4, %eax faţă de "mov eax, 4").
În sintaxa AT&T mnemonicele instrucţiunilor care angajează referinţe de memorie trebuie sufixate cu b (referinţă de byte, 8 biţi), w (= word, 16 biţi), l (= long, 32 biţi), etc. - permiţând asamblorului să determine dimensiunea operandului implicat (sufixul poate lipsi dacă operanzii implicaţi nu referă memoria); în sintaxa Intel, determinarea dimensiunii operanzilor de memorie necesită prefixarea cu byte ptr, sau cu word ptr, respectiv dword ptr. De exemplu, pentru a încărca în registrul AL un octet de la adresa "foo" - AT&T: movb foo, %al; Intel: mov al, byte ptr foo.
Particularităţile sintactice AT&T au justificările lor; de exemplu, indicarea regiştrilor prin prefixul "%" face posibilă includerea simbolurilor externe C fără vreun risc de confuzie (şi fără a cere prefixarea acestor simboluri externe cu "_", precum în cazul altor asambloare).
Apeluri de sistem (întreruperi software)
Uneori execuţia unui program trebuie întreruptă, pentru a deservi evenimente care impun un răspuns prompt. Întreruperile hardware sunt "cerute" de diverse dispozitive externe - tastatură, mouse, CD-ROM, etc. - al căror hardware propriu este conectat la un controller programabil de întreruperi (circuitul I8259, pe platformele Intel) cu care şi microprocesorul are două legături (doi pini prin care percepe semnalele şi codurile de întrerupere de la I8259). Întreruperile software sunt emise de un program în execuţie, în general în acele momente când execuţia ajunge în situaţia de a necesita acces direct la hardware; de regulă, numai sistemul de operare are acces direct la hardware - aplicaţiile obişnuite trebuie să apeleze la sistemul de operare pentru asemenea operaţii. Sistemul de operare oferă o gamă suficient de largă de funcţii standard pentru realizarea operaţiilor obişnuite: citire de la tastatură într-un buffer de memorie, deschiderea unui fişier pentru citire/scriere, crearea unui director, deservirea operaţiilor obişnuite cu mouse-ul, etc.; adresele de intrare în funcţiile respective sunt înregistrate într-o anumită zonă de memorie (numită de obicei tabela vectorilor de întrerupere).
Instrucţiunea INT 0x21 pentru DOS/Windows şi analog, INT 0x80 pentru Linux - întrerupe execuţia programului din care este lansată şi "apelează" funcţia a cărei adresă este înregistrată în tabele vectorilor de întrerupere la intrarea de rang 4*0x21 = 0x84 (= 132) şi respectiv 4*0x80 = 0x200 (=512) pentru Linux; această funcţie constituie interfaţa între aplicaţiile obişnuite şi serviciile oferite de către sistemul de operare. Protocolul asumat de această interfaţă presupune că în registrul AH (sau în EAX) a fost transmis "numărul serviciului", iar în alţi regiştri au fost transmişi anumiţi parametri corespunzători serviciului solicitat sistemului de operare; pe baza numărului existent în AH (sau în EAX) se determină intrarea în tabela vectorilor de întrerupere corespunzătoare acelui serviciu şi - după salvarea pe stivă a tuturor regiştrilor - se apelează funcţia a cărei adresă este indicată în tabel la intrarea respectivă, furnizându-i ca parametri valorile primite în ceilalţi regiştri; la încheierea execuţiei funcţiei apelate, se reconstituie de pe stivă regiştrii salvaţi iniţial şi se revine în aplicaţia care solicitase serviciul respectiv.
O problemă cu litere şi coduri ASCII
În alfabetul standard avem 26 litere (mari sau mici) şi - fiindcă 26 < 32 = 25 = 1000002 - rezultă că sunt suficienţi 5 biţi pentru a reprezenta valorile 1..26, prin 1 = 00001, 2 = 00010, 3 = 00011, ..., 26 = 11010.
Prefixând cu 010 rezultă codurile ASCII ale majusculelor, 'A' = 01000001 = 0x41 = 65, 'B' = 01000010 = 0x42 = 66, ..., 'Z' = 01011010 = 0x5A = 90; înlocuind prefixul cu 011, rezultă codurile ASCII ale literelor mici 'a' = 01100001 = 0x61 = 97, 'b' = 01100010 = 0x62 = 97, ..., 'z' = 01111010 = 0x7A = 122.
Prefixarea se poate face folosind operatorul logic OR între prefixul respectiv şi valoarea de "prefixat"; de exemplu, "01100000" OR "00000001" = 0x60 OR 0x01 = 0x61 = 'a' (codul literei 'a'). Fiindcă diferenţa celor două prefixe este "0110000" - "01000000" = 0x60 - 0x40 = 0x20, rezultă că oricare literă mică diferă (în privinţa codului ASCII) de litera mare omonimă prin 0x20 ('w' - 'W' = 0x20, oricare ar fi litera 'w').
Ne propunem un program în limbaj de asamblare, prin care să verificăm pur si simplu, mica "teorie" de mai sus: înscrie într-o zonă de memorie numerele de câte 8 biţi 1..26; prefixează octeţii din zona respectivă cu "010" şi afişează literele obţinute; comută prefixul pe "011" şi afişează literele rezultate.
Pe Linux, folosind asamblorul Gas
Fişierele sursă pentru Gas au extensia standard (neobligatorie totuşi) .s (sau .S; de altfel, cu opţiunea -S compilatorul GCC generează codul în limbaj de asamblare); fişierele obiect produse de asamblor au extensia standard .o. Opţiunea de asamblare -g determină includerea în fişierul obiect a unui tabel de simboluri, care - asociind simbolurile existente în programul-sursă cu adresele stabilite de asamblor pentru ele - va permite folosirea ulterioară mai comodă (mai "umană"), a diverselor instrumente de investigare a codului (a debugg-erelor).
### Asamblare "limb.s" cu: as -g -a -o limb.o limb.s > limb.lst ### Obţine executabilul cu: ld -o limb limb.o .section .bss .lcomm litere, 26 # alocă 26 octeţi .section .data br: .string "\n" # codul ASCII/C de trecere pe rând nou .equ to_upp, 0x40 # litere mari = 1..26 OR 0x40 ('A' = 0x41) .equ to_low, 0x60 # litere mici = 1..26 OR 0x60 ('a' = 0x61) .macro write STR, STR_SIZE # scrie 'STR_SIZE' octeţi de la adresa 'STR' mov $4, %eax # în fişierul cu descriptorul EBX (stdout = 1) mov $1, %ebx movl \STR, %ecx movl \STR_SIZE, %edx int $0x80 # apelează kernelul Linux pentru serviciul 4 (= write) .endm .macro Exit mov $1, %eax # apelul de sistem 1 ("exit") încheie execuţia şi mov $0, %ebx # redă controlul către sistemul de operare int $0x80 .endm .section .text .globl _start # _start este numele standard (neobligatoriu) _start: # al punctului de intrare în execuţie (IP = _start) movb $to_upp, %al # AL = 0x40 call transform # constituie codurile ASCII de majuscule şi afişează movb $to_low, %al # AL = 0x60 call transform # constituie codurile ASCII de litere mici şi afişează Exit # încheie şi redă controlul sistemului de operare transform: # subrutină pentru constituirea la adresa 'litere' a mov $26, %ecx # codurilor ASCII de litere mari sau mici, movl $litere, %edi # prin OR între valorile 1..26 şi registrul AL mov $1, %ah # (la apelare, AL conţine prefixul necesar) or %al, %ah # AH = codul ASCII al literei next: # repetă pentru cele 26 de litere movb %ah, (%edi) # înscrie litera la adresa pointată de EDI inc %ah # AH = codul ASCII al literei următoare inc %edi # EDI pointează locul următoarei litere de înscris loop next # ECX--; dacă ECX > 0 atunci reia de la adresa 'next' write $litere, $26 # scrie pe ecran cele 26 de litere write $br, $1 # şi trece pe rândul de ecran următor ret # încheie 'transform', reluând execuţia programului apelant
Executând programul (pentru verificare), obţinem cele două rânduri de litere:
vb@debian:~/lar$ ./limb ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz vb@debian:~/lar$
După asamblare, s-a obţinut fişierul obiect limb.o; îl putem dezasambla cu objdump, pentru a constata că:
— toate simbolurile folosite în sursa limb.s au fost "eliminate", fiind înlocuite prin adrese sau valori; de exemplu, 'transform' a devenit adresa 0x0000001a (iar "call transform" a devenit "call 1a"); simbolurile definite prin directiva .equ au fost înlocuite prin valorile respective (faptul că apar şi etichetele simbolice pe listingul de dezasamblare se datorează opţiunii de asamblare -g, prin care s-a cerut asamblorului să includă în fişierul obiect şi un tabel de simboluri);
— macrourile au fost expandate, în locul unde au fost invocate;
— secţiunea de date "nu apare" pe listing, decât în mod implicit: de exemplu, la adresa 0x0000001f avem codul instrucţiunii "mov $0x0,%edi" care corespunde instrucţiunii "movl $litere, %edi" din limb.s şi deducem că etichetei "litere" îi corespunde adresa relativă 0 din segmentul de date.
vb@debian:~/lar$ objdump -d limb.o;
limb.o: file format elf32-i386
Disassembly of section .text:
00000000 <_start>:
0: b0 40 mov $0x40,%al
2: e8 13 00 00 00 call 1a <transform>
7: b0 60 mov $0x60,%al
9: e8 0c 00 00 00 call 1a <transform>
e: b8 01 00 00 00 mov $0x1,%eax
13: bb 00 00 00 00 mov $0x0,%ebx
18: cd 80 int $0x80
0000001a <transform>:
1a: b9 1a 00 00 00 mov $0x1a,%ecx
1f: bf 00 00 00 00 mov $0x0,%edi
24: b4 01 mov $0x1,%ah
26: 08 c4 or %al,%ah
00000028 <next>:
28: 88 27 mov %ah,(%edi)
2a: fe c4 inc %ah
2c: 47 inc %edi
2d: e2 f9 loop 28 <next>
2f: b8 04 00 00 00 mov $0x4,%eax
34: bb 01 00 00 00 mov $0x1,%ebx
39: b9 00 00 00 00 mov $0x0,%ecx
3e: ba 1a 00 00 00 mov $0x1a,%edx
43: cd 80 int $0x80
45: b8 04 00 00 00 mov $0x4,%eax
4a: bb 01 00 00 00 mov $0x1,%ebx
4f: b9 00 00 00 00 mov $0x0,%ecx
54: ba 01 00 00 00 mov $0x1,%edx
59: cd 80 int $0x80
5b: c3 ret
vb@debian:~/lar$
Procedând la fel cu fişierul executabil produs de linkerul ld (standard pentru Unix), vedem că secţiunile din program au fost relocatate corespunzător ("zona de cod" are adresa relativă 0x8048074; "litere" are adresa 0x80490d8; etc.):
vb@debian:~/lar$ objdump -d limb
limb: file format elf32-i386
Disassembly of section .text:
08048074 <_start>:
8048074: b0 40 mov $0x40,%al
8048076: e8 13 00 00 00 call 804808e <transform>
804807b: b0 60 mov $0x60,%al
804807d: e8 0c 00 00 00 call 804808e <transform>
8048082: b8 01 00 00 00 mov $0x1,%eax
8048087: bb 00 00 00 00 mov $0x0,%ebx
804808c: cd 80 int $0x80
0804808e <transform>:
804808e: b9 1a 00 00 00 mov $0x1a,%ecx
8048093: bf d8 90 04 08 mov $0x80490d8,%edi
8048098: b4 01 mov $0x1,%ah
804809a: 08 c4 or %al,%ah
0804809c <next>:
804809c: 88 27 mov %ah,(%edi)
804809e: fe c4 inc %ah
80480a0: 47 inc %edi
80480a1: e2 f9 loop 804809c <next>
80480a3: b8 04 00 00 00 mov $0x4,%eax
80480a8: bb 01 00 00 00 mov $0x1,%ebx
80480ad: b9 d8 90 04 08 mov $0x80490d8,%ecx
80480b2: ba 1a 00 00 00 mov $0x1a,%edx
80480b7: cd 80 int $0x80
80480b9: b8 04 00 00 00 mov $0x4,%eax
80480be: bb 01 00 00 00 mov $0x1,%ebx
80480c3: b9 d0 90 04 08 mov $0x80490d0,%ecx
80480c8: ba 01 00 00 00 mov $0x1,%edx
80480cd: cd 80 int $0x80
80480cf: c3 ret
vb@debian:~/lar$
Dacă am vrea să urmărim execuţia pas cu pas a programului, putem folosi GDB GNU's GDB Debugger.
Pe Windows, folosind asamblorul Nasm
Preferăm să folosim nasm în cel mai simplu mod: nu precizăm vreun format de fişier executabil (prin opţiunea -f), obţinând formatul executabil implicit bin (binar, în fişierul "limb.exe"); nu pretindem informaţie de depanare (prin opţiunea -g). Fişierul "limb.lst" (prin opţiunea -l) va conţine într-un format lizibil rezultatul asamblării.
;;; pe Windows: nasm limb.asm -o limb.exe -l limb.lst section .bss litere resb 26 ; aloca 26 octeti section .data br db "\n" ; codul ASCII/C de trecere pe rand nou (Unix) to_upp equ 40h ; litere mari = 1..26 OR 0x40 ('A' = 0x41) to_low equ 60h ; litere mici = 1..26 OR 0x60 ('a' = 0x61) %macro write 2 ; scrie %2 octeţi de la adresa %1 mov ah, 40h ; in fisierul cu descriptorul BX mov bx, 1 ; descriptorul 1 corespunde ecranului (stdout) mov cx, %2 ; numarul de octeti de scris mov dx, %1 ; adresa octetilor de scris int 21h ; apeleaza functia DOS pentru serviciul indicat in AH (scriere in fisier) %endmacro %macro Exit 0 mov ax, 4C00h ; functia DOS pentru exit (AH = 0x4C) int 21h %endm section .text start: ; punctul de intrare in execuţie (IP = start) mov al, to_upp ; AL = 0x40 call transform ; constituie codurile ASCII de majuscule si afiseaza mov al, to_low ; AL = 0x60 call transform ; constituie codurile ASCII de litere mici si afiseaza Exit ; incheie si reda controlul sistemului de operare transform: ; subrutina pentru constituirea la adresa litere a mov ecx, 26 ; codurilor ASCII de litere mari sau mici, mov edi, litere ; prin OR intre valorile 1..26 si registrul AL mov ah, 1 ; (la apelare, AL conţine prefixul necesar) or ah, al ; AH = codul ASCII al literei next: ; repeta pentru cele 26 de litere mov [edi], ah ; inscrie litera la adresa pointata de EDI inc ah ; AH = codul ASCII al literei urmatoare inc edi ; EDI pointeaza locul urmatoarei litere de inscris loop next ; ECX--; daca ECX > 0 atunci reia de la adresa next write litere, 26 ; scrie pe ecran cele 26 de litere write br, 1 ; si trece pe randul de ecran urmator ret ; incheie transform, reluand executia programului apelant
Executând şi dezasamblând cu ndisasm (inclus în pachetul Nasm):
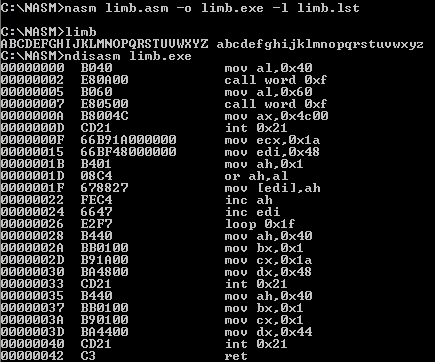
De asemenea, putem folosi debug, cu care putem urmări şi execuţia pas cu pas a programului (folosind comanda t). Putem constata şi acum (am mai făcut-o şi anterior) că deşi debug nu recunoaşte mnemonicele de regiştri extinşi, pune în execuţie instrucţiunile respective (de exemplu, instrucţiunea "inc EDI" de cod 0x6647 este redată de comanda de dezasamblare u prin "DB 66" - 0x66 este octetul-prefix pentru date de 32 biţi - şi apoi "inc DI").
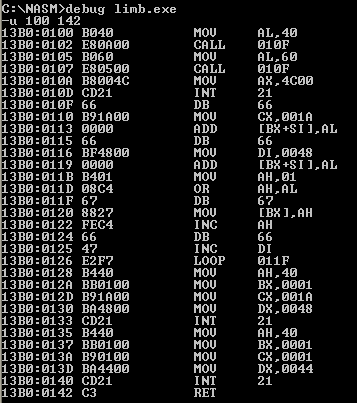
De data aceasta, prin executarea programului - literele au fost afişate toate pe acelaşi rând; de vină este interpretarea diferită a caracterului \n (emis prin instrucţiunea "write br, 1", care în cazul Linux a determinat trecerea pe următorul rând de ecran, la începutul acestuia).
Primele 32 de coduri ASCII sunt coduri de control; codurile 0x0A Line Feed şi 0x0D Carriage Return au fost destinate pentru controlul unei imprimante (sau al afişării pe ecran), anume: LF determină mutarea capului de imprimare cu o linie mai jos, iar CR determină mutarea capului de imprimare la marginea stângă (fără trecere pe următoarea linie); cu timpul, CR a fost de asemenea, asignat tastei ENTER, semnalând că s-a încheiat introducerea unui text de la tastatură.
Aceste coduri au fost implementate ca atare (păstrând semnificaţia originală) în multe protocoale de comunicaţie serială şi în sisteme de operare precum DOS/Windows; dar limbajul C şi Unix-ul au redefinit caracterul LF (0x0A) drept newline, însemnând acum combinarea operaţiilor "line feed" şi "carriage return" într-o singură operaţie (în multe limbaje, acest caracter de control este desemnat prin "\n") - motivarea fiind că este de dorit ca apăsând tasta ENTER să treci nu doar "dedesubt", dar chiar "dedesubt şi la începutul rândului".
Pe Linux, putem face următorul experiment simplu: creem un fişier text "test.txt" conţinând două rânduri; afişăm "test.txt" în hexazecimal (şi constatăm separarea rândurilor prin 0x0A); convertim "text.txt" la formatul DOS şi afişăm din nou (constatând acum că separarea rândurilor se face prin 0x0D şi 0x0A):
vb@debian:~/lar$ cat > test.txt aaa bbb vb@debian:~/lar$ hexdump -C test.txt 00000000 61 61 61 0a 62 62 62 |aaa.bbb| vb@debian:~/lar$ unix2dos test.txt vb@debian:~/lar$ hexdump -C test.txt 00000000 61 61 61 0d 0a 62 62 62 |aaa..bbb|
Folosind iarăşi hexdump (de pe Linux), putem vedea fişierul binar "limb.exe" (produs de nasm pe Windows, cum am arătat mai sus):
vb@debian:~/lar$ hexdump -C nasm/limb.exe 00000000 b0 40 e8 0a 00 b0 60 e8 05 00 b8 00 4c cd 21 66 |.@....`.....L.!f| 00000010 b9 1a 00 00 00 66 bf 48 00 00 00 b4 01 08 c4 67 |.....f.H.......g| 00000020 88 27 fe c4 66 47 e2 f7 b4 40 bb 01 00 b9 1a 00 |.'..fG...@......| 00000030 ba 48 00 cd 21 b4 40 bb 01 00 b9 01 00 ba 44 00 |.H..!.@.......D.| 00000040 cd 21 c3 00 5c 6e |.!..\n|
Confruntând cu dezasamblările prezentate mai sus, constatăm că "limb.exe" conţine nimic altceva decât codurile binare ale instrucţiunilor (conformându-se vechiului format de executabil .COM din DOS). Alte formate de fişier-executabil (produse prin intermediul unui linker, din fişierul-obiect) au în plus un header specific, cu informaţii de relocatare a secţiunilor şi eventual cu informaţii de depanare (tabele de simboluri); de exemplu, se poate vedea cu hexdump fişierul executabil rezultat în primul caz (când am folosit Gas şi linkerul ld pe Linux).
Porturi şi întreruperi
Am vizat anterior două elemente: microprocesorul şi memoria internă; CPU accesează memoria prin intermediul magistralelor, realizând operaţii de citire sau scriere şi prelucrând datele conform setului propriu de instrucţiuni.
Porturi I/O
Pentru introducere în memorie, sau extragere - sunt angrenate diverse dispozitive I/O (de intrare/ieşire): tastatură, unităţi de disc, display, printer, etc. Un astfel de echipament conţine circuite proprii care pot fi programate pentru a asigura funcţionarea specifică; pe de altă parte, el este cuplat la magistrale (fie direct printr-unul dintre circuitele proprii, fie prin intermediul unei plăci adaptoare).
Fiecărui dispozitiv extern conectat astfel cu CPU, îi este rezervată una sau mai multe "adrese" (porturi de comunicare); CPU poate accesa dispozitivul respectiv prin intermediul porturilor şi magistralelor: se depune adresa de port pe magistrala de adrese şi se emite pe magistrala de comenzi semnalul de citire (sau de scriere - caz în care data de transmis va fi depusă pe magistrala de date).
Astfel, accesul la un dispozitiv I/O decurge analog accesului CPU la memorie; iar evitarea confuziei între adresă de memorie şi adresă de port este asigurată prin existenţa unui semnal de comandă special: un anumit pin al CPU - notat cu M/IO - este pus pe "1" pentru acces la memorie, respectiv pe "0" pentru acces la un port I/O.
Circuitul (controler) care asigură astfel legătura între CPU şi dispozitivele I/O, dispune de un registru de stare, de un registru de comandă, de regiştri de date şi fiecăruia dintre aceşti regiştri îi este rezervată o anumită adresă de port. Pentru CPU (şi pentru programator), circuitul respectiv şi însuşi dispozitivul I/O aferent este reprezentat de porturile de comunicare ce i-au fost atribuite.
CPU poate citi în acumulator (adică în AL, în AX, sau în EAX) cuvântul de stare curentă a dispozitivului, sau datele emise de acesta - depunnând pe magistrala de adrese numărul portului respectiv, fie NrPort; pentru NrPort = 0..255 (de tip byte), instrucţiunea IN AL, NrPort realizează selectarea portului respectiv - valoarea NrPort este înscrisă pe magistrala de adrese, se activează semnalul de citire, iar semnalul M/IO este pus pe "0" - şi totodată obţine în AL valoarea emisă pe calea de date de către registrul de port selectat. Pentru NrPort > 255, adresarea portului respectiv are loc prin intermediul registrului DX: se încarcă valoarea NrPort în DX şi apoi se foloseşte instrucţiunea IN AX, DX - conţinutul lui DX va fi depus pe magistrala de adrese, iar acumulatorul va prelua cuvântul de pe calea de date.
Analog, CPU poate emite o dată sau un cuvânt de comandă (pentru a selecta un anumit mod de lucru, sau a specifica anumiţi parametri de funcţionare a dispozitivului), prin OUT NrPort, acumulator (sau OUT DX, acumulator).
Tabelul vectorilor de întrerupere
Folosind instrucţiuni IN, OUT şi cunoscând porturile necesare, se vor putea programa operaţiile I/O adecvate. Fiindcă mai toate aplicaţiile implică numeroase operaţii I/O, programele necesare au fost standardizate şi incluse împreună într-o bibliotecă de bază - BIOS Basic Input Output System.
Însă BIOS-ul este o memorie de tip read only; astfel că, pentru a asigura posibilitatea ca programatorul însuşi (sau sistemul de operare) să administreze sau să extindă unele operaţii I/O - în loc să apeleze la serviciile standardizate minimale oferite de BIOS - s-a adoptat ideea de a "vedea" BIOS-ul nu în mod direct, ci prin intermediul unei anumite "staţii de comunicare" instituite în memoria RAM (de tip Read/Write). Şi anume, odată cu "iniţializarea sistemului" - sarcină distinctă, realizată direct de anumite rutine din BIOS - are loc înscrierea în memoria RAM a unor puncte de intrare în rutinele incluse în BIOS (precum şi a unor date rezultate din testarea echipamentelor existente).
Exemplificând pe I8086, zona respectivă dispune de 1024 octeţi şi înregistrează maximum 1024/4 = 256 de adrese Segment:Offset; fiecare intrare în acest tabel este un vector de 4 octeţi (vectorul 0 indică primii patru octeţi din tabel; vectorul 5 indică cei patru octeţi începând de la octetul de rang 5×4 din tabel); vectorul respectiv înregistrează adresa unei anumite rutine (una din BIOS, sau una din nucleul sistemului de operare).
Această zonă RAM este denumită tabelul vectorilor de întrerupere, sau tabela descriptorilor de întrerupere IDT; dacă programatorul va opta uneori pentru o tratare proprie în locul celei standard oferite de BIOS (sau de sistemul de operare), atunci el nu are decât să înlocuiască adresa existentă la intrarea respectivă în tabel, cu adresa propriei rutine. Desigur, înlocuirea unei adrese "oficiale" din IDT cu adresa unei rutine proprii necesită multă precauţie; de exemplu, adresa originală trebuie salvată pentru a o înregistra înapoi la momentul potrivit - altfel, după execuţia programului propriu, zona de memorie aferentă este de regulă eliberată, încât adresa care a fost lăsată în IDT în locul celei originale nu mai poate deservi corect o eventuală solicitare ulterioară.
Instrucţiunea INT vector va determina apelarea rutinei a cărei adresă este conţinută în vectorul precizat de instrucţiune ca intrare în IDT (la offsetul egal cu 4×vector, faţă de baza IDT); este vorba într-adevăr de o INTrerupere (şi anume, o întrerupere soft), pentru că rutina apelată astfel nu este de obicei, parte a programului din care este apelată. INT vector realizează întâi salvarea stării curente a programului (registrul flagurilor şi adresa de revenire) şi apoi lansează rutina externă indicată de intrarea respectivă din IDT; revenirea în programul din care s-a cerut serviciul respectiv este provocată de instrucţiunea IRET - aceasta, spre deosebire de RET, asigură şi reconstituirea registrului flagurilor.
Controlerul de întreruperi
Am descris mai sus mecanismul întreruperilor doar ca posibilitate de utilizare a serviciilor existente în BIOS (sau a celor oferite de sistemul de operare). Dar sorgintea acestui mecanism este în primul rând de natură hardware, având la bază perceperea dispozitivelor I/O ca elemente active care dispun de o anumită autonomie funcţională; în fond, s-a dorit ca CPU să fie scutit de a le purta de grijă - prevăzând pentru aceasta un circuit special, PIC Programmable Interrupt Controller.
Pentru a evidenţia aspectele tipice ale mecanismului întreruperilor, considerăm circuitul I8259 - controlerul programabil de întreruperi introdus de Intel în 1980. La un circuit I8259 sunt conectate până la 8 dispozitive I/O (ca surse de întreruperi), prin linii desemnate prin IRQ0, IRQ1, ..., IRQ7; pe aceste linii, dispozitivele respective pot emite controlerului cereri de întrerupere.
În registrul IRR Interrupt Request Register (registrul cererilor în aşteptare) al lui I8259, bitul 0 (sau nivelul 0 de întrerupere - cel cu prioritate maximă) corespunde liniei IRQ0; bitul 1 (nivelul 1 de întrerupere) corespunde liniei IRQ1; ş.a.m.d. Fiecărei surse de întrerupere îi este asociat astfel câte un cod unic 0002...1112 - acesta va fi depus la un anumit moment pe magistrala de date, iar CPU îl va prelua drept selector (tipul întreruperii) de intrare în tabela vectorilor de întrerupere (în octetul de tip-întrerupere, I8259 are de poziţionat numai ultimii 3 biţi, corespunzător uneia dintre cele 8 linii; primii 5 biţi au valoarea implicită "00001"):
| linia | nivel | Tip | Adresa intrării în IDT (= 4×Tip) | dispozitiv deservit |
| IRQ0 | 0 | 00001000 = 08 | 0000:0020 | contor de timp |
| IRQ1 | 1 | 00001001 = 09 | 0000:0024 | tastatură |
| IRQ2 | 2 | 00001010 = 0A | 0000:0028 | placă video |
| IRQ3 | 3 | 00001011 = 0B | 0000:002C | port serial 2 |
| IRQ4 | 4 | 00001100 = 0C | 0000:0030 | port serial 1 |
| IRQ5 | 5 | 00001101 = 0D | 0000:0034 | harddisk |
| IRQ6 | 6 | 00001110 = 0E | 0000:0038 | floppy disk |
| IRQ7 | 7 | 00001111 = 0F | 0000:003C | port paralel 1 |
De exemplu, la acţionarea unei taste, dispozitivul deservit este tastatura; controlerul tastaturii va activa linia de întrerupere care-i corespunde, IRQ1; sesizat astfel, I8259 va genera codul 09, pe baza căruia CPU va selecta din IDT vectorul al 9×4 = 36-lea, adică cei 4 octeţi consecutivi de la offsetul 0x0024, reprezentând adresa rutinei care va deservi întreruperea.
Întreruperile controlate de I8259 sunt mascabile - ele pot fi dezactivate sau activate în mod selectiv, prin setarea sau resetarea biţilor corespunzători din registrul IMR Interrupt Mask Register al controlerului. Totodată, CPU poate inhiba temporar toate întreruperile mascabile, prin ştergerea bitului IF Interrupt Flag din cadrul registrului de flaguri - în urma executării instrucţiunii CLI CLear Interrupt; efectul invers, de permitere a întreruperilor mascabile (IF = 1) este asigurat prin instrucţiunea STI SeT Interrupt.
Sunt prevăzute de asemenea, întreruperi externe nemascabile - care nu îşi au originea în I8259 şi nu sunt afectate de starea flagului IF; ele "vin" direct la CPU, pe pinul NMI Non-Maskable Interrupt - semnalând un eveniment critic, care necesită atenţie imediat (scăderea tensiunii de alimentare, apariţia unei erori la memorie, o excepţie de operare).
În sfârşit, unele întreruperi sunt generate intern, de către CPU însuşi - ca urmare a producerii unei situaţii de excepţie prevăzute pentru anumite instrucţiuni (împărţire la 0, depăşire), sau pentru a permite urmărirea execuţiei "pas cu pas".
În principiu, elementele angajate în mecanismul de tratare prin întreruperi pot fi sintetizate astfel:
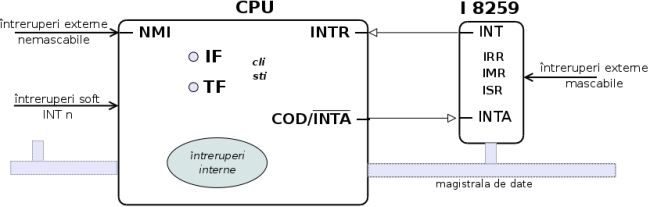
Pinul COD/INTA Code / Interrupt Acknowledge al CPU - pe lângă faptul că serveşte disocierii între citire de cod al unei instrucţiuni şi citire a unei date - permite lansarea unor impulsuri de recunoaştere (sau confirmare) a întreruperii. Când primeşte prin pinul INTA confirmarea acceptării de întrerupere, I8259 scoate pe magistrala de date codul întreruperii respective, resetează în registrul IRR bitul corespunzător acesteia (ceea ce asigură dispozitivului respectiv posibilitatea de a depune eventual o nouă cerere de întrerupere, "în aşteptare") şi înscrie 1 în bitul corespunzător nivelului întreruperii din registrul ISR In-Service Register (registrul întreruperilor în curs de tratare); bitul respectiv din ISR va fi şters în final - ca urmare a recepţionării unui semnal EOI End-Of-Interrupt - şi controlerul va trece la tratarea următoarei cereri de întrerupere.
I8259 poate fi configurat prin program să funcţioneze în diverse moduri de operare, emiţând cuvinte de comandă şi cuvinte de mod corespunzătoare; astfel, se pot masca unele întreruperi, se poate fixa un alt lanţ de priorităţi decât cel implicit, se poate alege între a aştepta semnalul EOI de la CPU sau a genera un semnal AEOI (Automatic EOI); un anumit cuvânt, va permite citirea de către CPU, de la portul respectiv, a registrului IRR, sau a registrului ISR.
CPU răspunde la o întrerupere mascabilă după următorul scenariu general:
- termină de executat instrucţiunea curentă (instrucţiunile CPU sunt neîntreruptibile);
- dacă nu au apărut întreruperi interne şi nici întreruperi externe nemascabile, atunci - dacă linia INTR este activă - se testează IF; dacă IF = 0 (adică întreruperile mascabile sunt inhibate), atunci se trece la executarea următoarei instrucţiuni din program (paşii de mai jos nu mai există, în acest caz);
- însă dacă IF = 1, atunci se confirmă acceptarea întreruperii şi se citeşte octetul de tip-întrerupere depus de I8259 pe magistrala de date; acest octet indică vectorul din tabela vectorilor de întrerupere care conţine adresa rutinei ce va deservi întreruperea;
- se salvează pe stivă registrul flagurilor (inclusiv, starea curentă a flagului IF);
- se resetează biţii IF şi TF; procedând astfel (punând IF = 0 înainte de a lansa rutina corespunzătoare serviciului cerut), se elimina posibilitatea ca deservirea să fie ea însăşi întreruptă printr-o viitoare altă întrerupere;
- se salvează pe stivă şi adresa de revenire în programul ce urmează să fie suspendat, după care în sfârşit - se intră în rutina de servire a întreruperii (a cărei adresă a fost depistată în pasul 3);
- la încheierea rutinei respective - anume, prin IRET - se reconstituie de pe stivă registrul flagurilor (deci şi starea originală a flagului IF - ceea ce permite şi eventuala imbricare a unor întreruperi) şi se reia execuţia programului suspendat.
Codul ASCII şi generarea caracterelor
În martie 2008 s-au împlinit 40 de ani de la adoptarea oficială (Lyndon B. Johnson) a codului ASCII.
Când s-au înfiinţat serviciile poştale, mesajele au putut fi transmise la distanţă cu tolba (în goana calului, vezi şi povestea The Postman); când a apărut telegraful electric, s-a pus problema transmiterii la distanţă de mesaje scrise fără a transporta pe sârme şi… literele componente. Samuel Morse a rezolvat problema prin 1837, creând codul Morse - prin care literele erau reprezentate prin combinaţii distincte de câte două impulsuri standard, reprezentate în scris prin . (iar verbal, prin: di sau did) şi — (impuls lung, verbal: dah); de exemplu, litera A era transmisă prin secvenţa .— (verbal: di dah), iar litera B prin —... (dah di di did).
La vechiul telegraf, cel care recepţiona trebuia să scrie prin puncte şi linioare ceea ce auzea în cască şi apoi să decodifice mesajul, transformând în litere secvenţele notate; apărând calculatoarele, monitoarele, imprimantele - s-a pus şi problema transformării automate a semnalelor recepţionate, în caractere scrise (sau afişate) obişnuit.
Când se apasă o tastă, în bufferul tastaturii se înregistrează un anumit cod numeric scan code, corespunzător poziţiei tastei în cadrul tastaturii; codul respectiv permite selectarea unei anumite intrări într-un tabel de coduri preexistent, de unde se determină eventual codul ASCII corespunzător (care este un număr 0..255, nu reprezintă forma grafică obişnuită a literei!); prin ce mecanisme, acest cod este transpus pe ecran în forma grafică obişnuită pentru litere? Aproape evident, există un tabel în care fiecare cod ASCII de caracter selectează printr-un anumit mecanism, descrierea grafică necesară afişării acelui caracter.
Cu DEBUG-ul, despre placa video şi BIOS (sub DOS/Windows)
Imaginea curentă a întregului ecran este memorată într-o zonă de memorie prestabilită, într-o anumită codificare digitală: în modul text, unitatea de măsură este caracterul, reprezentat în memoria video printr-o pereche de octeţi - codul ASCII şi octetul atributelor de afişare (culoarea cu care este afişat caracterul, culoarea fundalului, etc.); în modul grafic, unitatea de adresare este pixelul, având asociat câte un anumit bit în mai multe "plane" posibile (adresate în paralel) ale memoriei video.
Controlerul video dispune de nişte numărătoare (de caractere pe linie, de linii pe ecran), pe baza cărora se generează spre memoria video adresa următorului cod ASCII de afişat; codul adresat astfel este dirijat ca intrare în tabelul de caractere, pentru a selecta matricea grafică aferentă; fiecare linie de "puncte" din această matrice este emisă spre monitor (iar conversia în semnal video şi compunerea cu semnale de sincronizare specifice conduc la afişarea obişnuită a caracterului).
La pornirea calculatorului, CPU primeşte spre execuţie programul de iniţializare înscris în modulul ROM BIOS de pe placa de bază, prin care se testează funcţionarea componentelor de bază; eventualele erori sunt semnalate acum prin coduri audio, căci sistemul video încă nu este iniţializat. După ce este completată şi tabela vectorilor de întrerupere, urmează căutarea şi lansarea programului ROM BIOS conţinut în placa adaptoare video; acestui program îi corespunde în memorie adresa de bază 0xC000:0000 (în cazul plăcilor VGA) :
Primii doi octeţi 0x55, 0xAA - constituie o "semnătură" pentru "început de modul valid"; următorul octet 0x64 indică dimensiunea modulului respectiv (= 0x64 × 0x200 = 0xC800 =51200 octeţi). Octetul următor 0xE9 este codul unei instrucţiuni JMP, de salt la rutina de iniţializare propriu-zisă (deplasamentul acestui salt fiind 0xC14B; dezasamblând cei trei octeţi ai instrucţiunii cu uC000:0003 găsim JMP 0xC151).
Rutina respectivă (care se poate dezasambla prin comanda uC000:C151) configurează corespunzător diverşi regiştri ai controlerului video şi înregistrează setările rezultate şi alte informaţii specifice adaptorului video respectiv, în anumite zone de date rezervate BIOS-ului. Astfel, în segmentul de date BIOS 0x00400:
C:\>debug -d 0000:0400 0000:0400 F8 03 F8 02 E8 03 E8 02-BC 03 78 03 78 02 80 9F ..........x.x... 0000:0410 23 C8 00 80 02 28 00 00-00 00 3A 00 3A 00 64 20 #....(....:.:.d 0000:0420 20 39 30 0B 30 0B 30 0B-30 0B 3A 27 30 0B 34 05 90.0.0.0.:'0.4. 0000:0430 34 05 08 0E 30 0B 30 0B-0D 1C 00 00 00 00 01 00 4...0.0......... 0000:0440 9B 00 38 00 FF 59 FA E0-35 03 50 00 40 1F 00 00 ..8..Y..5.P.@...
găsim la adresa 0x00449 valoarea 03 pentru modul de afişare activ = "text"; la adresa 0x0044A avem numărul de coloane-ecran = 0x0050 (= 80 de caractere pe linia de ecran), iar următorii doi octeţi dau dimensiunea unei pagini-ecran = 0x1F40 = 8000 octeţi. Mai departe sunt stocate informaţii despre pagina-ecran activă (numărul de ordine al ei, offsetul faţă de baza memoriei video), despre poziţia cursorului în fiecare pagină ecran şi despre tipul cursorului.
Adresa rutinei BIOS care asigură serviciile video standard este înregistrată pe a 16-a intrare în tabelul vectorilor de întrerupere; deci această rutină va putea fi apelată prin INT 0x10. Rolul de selector de servicii este rezervat registrului AH; de exemplu, pentru a afişa caracterul de cod ASCII 1:

(comanda g Go pune în execuţie secvenţa de instrucţiuni, până la instrucţiunea de întrerupere INT 3)
Folosind comanda de trasare t pentru o secvenţă precum cea redată mai sus, putem parcurge pas cu pas inclusiv rutina BIOS apelată cu INT 10h (studiu pretenţios, dar foarte instructiv: necesită răbdare, concentrare, capacitate de reluare şi putere de sinteză). Se pot observa astfel, următoarele etape, parcurse la fiecare apel al rutinei BIOS indicate de vectorul 0x10:
— mai întâi sunt investigaţi mai mulţi parametri din zona de date BIOS (mod video curent, număr coloane ecran, etc.) - ramificând execuţia după setările găsite;
— se face apoi o filtrare pe tipuri de servicii; anume, se compară valoarea transmisă în AH cu anumite limite de încadrare, ramificând execuţia corespunzător tipului de serviciu depistat astfel. Aceasta permite executarea unor operaţii preliminare care sunt comune mai multor servicii de un acelaşi tip;
— în sfârşit, se caută într-un tabel de adrese offsetul subrutinei corespunzătoare valorii din AH, se apelează această subrutină şi apoi se încheie (cu IRET, nu cu RET).
Programul angajat cu INT 0x10, cu etapele de mai sus - este ca să zicem aşa, cam năcăjât; el ar putea fi rescris mai bine, dacă s-ar folosi instrucţiunile CPU mai noi - numai că trebuie să se aibă în vedere faptul că BIOS-ul respectiv trebuie să poată deservi o gamă cât mai largă de microprocesoare (nu numai Pentium, dar chiar şi I8086). Linux nu foloseşte serviciile BIOS (nu are apeluri de sistem similare cu INT 0x10 din DOS).
Ocolirea serviciilor BIOS
În etapa finală, fiecare serviciu video din BIOS accesează şi înscrie corespunzător regiştrii programabili ai controlerului video, folosind instrucţiuni OUT port, valoare; dacă se doreşte sporirea vitezei de lucru, atunci se pot ocoli serviciile video oferite de BIOS, angajând direct instrucţiuni OUT (desigur, aceasta înseamnă a lucra direct cu hardware-ul, ocolind cumva sistemul de operare - ceea ce necesită de obicei permisiuni speciale).
Controlerul video are cinci seturi de regiştri programabili; câte un registru-index din fiecare set este destinat selectării unuia dintre regiştrii existenţi în setul respectiv (la fel cum AH permite selectarea unui serviciu la INT 0x10), iar un al doilea registru (registrul de date al setului) permite emiterea unei date către registrul selectat. Pentru o exemplificare, vizăm aici lucrul cu setul regiştrilor de control (în general, aceştia controlează formatul ecranului, modul de afişare, dimensiunea, forma şi poziţia cursorului, adresa de start a paginii ecran).
În zona de date BIOS, la adresa 0000:0463 se află înregistrată adresa 0x03D4 care reprezintă portul de acces la registrul-index al setului de regiştri de control. Portul imediat următor 0x3D5, corespunde registrului de date asociat setului regiştrilor de control. Portul 0x3D4 (pentru plăcile VGA) permite selectarea prin index a unui registru de control:
mov DX, 03D4h mov AL, index out DX, AL
După selectarea registrului dedicat realizării operaţiei dorite, urmează setarea lui la valoarea necesară - prin emiterea datei respective la portul de date 0x3D5:
mov AL, valoare_de_programat inc DX ; acum, DX = 3D5h (portul de date) out DX, AL
Ambele operaţii - selectarea registrului şi emiterea datei către el - pot fi realizate şi într-un singur pas (dat fiind că cele două porturi sunt adrese consecutive), folosind OUT DX, AX (prin care se va depune indexul AL la portul [DX] şi totdată se va emite AH la portul următor [DX + 1]).
Pentru exemplu, să modificăm cursorul; în modul text 3, cursorul ocupă în mod implicit penultimele două linii (13 şi 14) dintr-o boxă de caracter 9×16 pixeli (tipul curent al cursorului este înregistrat în zona de date BIOS 0000:0460, anume 0x0E 0x0D - adică pe liniile de pixeli 13 şi 14 din matricea de pixeli care corespunde unui caracter afişat pe ecran).
În setul de regiştri indexaţi prin registrul de index 0x3D4, la offseturile 0x0A şi 0x0B - se află regiştrii dedicaţi gestionării dimensiunii cursorului şi îi vom putea folosi astfel:
mov DX, 03D4 ; sub DEBUG, valorile sunt implicit în hexazecimal mov AX, 000A ; Selectează registrul 0x0A start-cursor, setând linia ; de început a cursorului la linia 0 a boxei de caracter. out DX, AX ; Ca urmare (sub DEBUG se vede imediat), deja cursorul se întinde între ; liniile 0 şi 14, având forma ▉ inc AL ; Pentru a selecta registrul 0x0A + 1 = 0x0B end-cursor. mov AH, 7 ; Pentru a fixa linia 7 ca linie de sfârşit a cursorului. out DX, AX ; Acum, cursorul va ocupa liniile 0..7: ▀
Desigur, acelaşi efect (sigur mai încet, dar şi cu actualizările necesare: de exemplu, la adresa 0000:0460 trebuie înscrisă noua formă de cursor) se putea obţine apelând la BIOS, prin INT 0x10 cu AH = 1 şi CH = 0 (linia de început a cursorului), CL = 7 (linia de sfârşit a cursorului).
Matricea caracterului
Mai sus, am afişat cu DEBUG caracterul de "cod ASCII" 1, similar ca formă cu ☺. De fapt, nu mai este vorba chiar de ASCII - în cadrul codului ASCII propriu-zis, primele 32 de coduri 0..31 desemnează "caractere de control", fără imagine grafică; este vorba de pagina de coduri CP437 (mai denumită şi "Extended ASCII", sau "Original Equipment Manufacturer-font") - un tabel cu 256 intrări, în care intrarea de rang K = 0..255 cuprinde o matrice de 8 linii şi 8 coloane pe care este "desenat" un caracter (chiar cel desemnat prin codul ASCII K, dacă K = 32..127). CP437 - creată de IBM, prin 1980 - este înscrisă în memoria ROM a plăcilor video (pe lângă alte câteva asemenea seturi de caractere) şi este primul font folosit pentru afişare pe ecran în momentul pornirii calculatorului.
Găsind (cum arătăm mai încolo) adresa la care este mapat tabelul CP437 şi făcând un "dump":

Prima intrare de 8 octeţi (toţi nuli) corespunde codului 0; următorii 8 octeţi sunt asociaţi codului 1 şi compun forma grafică următoare (░ reprezintă un bit 0, iar ▒ = 1):
| 7E | 01111110 | ░▒▒▒▒▒▒░ |
| 81 | 10000001 | ▒░░░░░░▒ |
| A5 | 10100101 | ▒░▒░░▒░▒ |
| 81 | 10000001 | ▒░░░░░░▒ |
| BD | 10111101 | ▒░▒▒▒▒░▒ |
| 99 | 10011001 | ▒░░▒▒░░▒ |
| 81 | 10000001 | ▒░░░░░░▒ |
| 7E | 01111110 | ░▒▒▒▒▒▒░ |
INT 0x10 şi în particular, serviciile BIOS de încărcare a unui set de caractere sunt investigate amănunţit în [1] şi nu mai este cazul să actualizăm aici. Secvenţa următoare va încărca setul CP437 şi va furniza informaţii corecte asupra lui:
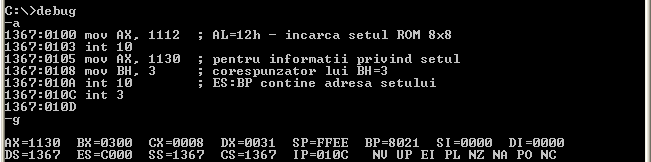
Informaţiile returnate sunt CL = 8 = numărul de octeţi pe caracter; DL = 0x31 = 49 = rangul ultimei linii ecran (numărând de la 0); ES:BP = 0xC000:0x8021 = adresa de încărcare a setului de caractere (adresă la care făcusem "dump" mai sus). Să precizăm că "numărul de octeţi pe caracter" se referă la dimensiunea unei intrări în pagina de coduri respectivă; pe ecran nu-i corespunde o lăţime de 8 pixeli - ci de 9 pixeli (încât lăţimea ecranului este de 9 × 80 caractere = 720 pixeli), o a noua coloană de pixeli fiind inserată automat în scopul unei mai clare separări a caracterelor.
Program NASM pentru generarea formelor grafice CP437
Un set de caractere din ROM BIOS descrie 128 sau 256 de caractere; le vom reprezenta în succesiuni de câte NR_MAT = 8 matrici alăturate orizontal; primul şir de matrici din fişier va constitui vizualizarea grafică a caracterelor de coduri 0..7, al doilea şir de matrici corespunde codurilor 8..15, ş.a.m.d. În total, fişierul va conţine 256/NR_MAT şiruri de câte NR_MAT matrici-caracter. Fiecare astfel de şir de matrici acoperă un număr de ROW linii-text, unde ROW este numărul de octeţi pe caracter specific setului (ROW = 8 pentru CP437). O linie-text a fişierului - dacă nu separă ("\n") două şiruri consecutive de matrici - vizualizează octeţii de acelaşi rang 0..(ROW - 1) din descrierile a NR_MAT caractere consecutive din setul respectiv; pentru vizualizarea formelor grafice vom marca bitul 0 prin ░, iar bitul 1 prin ▒.
Pentru a evita calcularea repetată a componenţei binare a octetului curent (dintre cei ROW octeţi care compun descrierea caracterului curent din set), vom genera în prealabil toate cele 256 de modele de linie-caracter (de la "00000000" până la "11111111"); rezervăm în acest scop 256×8 octeţi (iniţializaţi cu ░) la adresa MODELE, în cadrul zonei de date. De exemplu, dacă octetul curent din descrierea caracterului ar fi 0x7E, atunci forma grafică a liniei-caracter corespunzătoare va putea fi preluată direct din zona MODELE, de la intrarea 0x7E × 8 = 0x7E (se înmulţeşte cu 8 fiindcă fiecărui cod îi corespund în MODELE câte 8 octeţi, ░ sau ▒).
Cele NR_MAT modele binare obţinute astfel (pentru octeţii de acelaşi rang 0..(ROW - 1), din descrierile a NR_MAT caractere consecutive din set), vor fi concatenate succesiv (intercalând câte un spaţiu separator) în bufferul BUF_ROWS, care va fi scris apoi în fişier.
; C:\> nasm -fobj cargen.asm ; C:\> tlink cargen.obj %define NR_MAT 8 ; analog cu #define în C/C++ section .data align 4 file db "map437.txt", 0 ; nume fişier (şir ASCIIZ, cerut de DOS FN 40h) newline db 13, 10 ; codul ASCII de "newline" pentru DOS bitgr db 176 ; caracter grafic (cod CP437) pentru bit = 0 section .bss align 4 MODELE resb 256*8 ; 8 biţi de fiecare octet 0..255 (bit=0 —> 0xB0, bit=1 —> 0xB1) BUF_ROWS resb 9*NR_MAT ; Linia de scris în fişier: câte 8 caractere 'bitgr' plus ; un spaţiu, pentru octeţii de acelaşi rang din NR_MAT caractere consecutive. file_id resw 1 ; descriptorul fişierului ROW resw 1 ; nr. octeţi/caracter (= 8 pentru CP437) %macro EXIT 0 mov AX, 4C00h ; funcţia DOS FN 4Ch, pentru EXIT (AH = 0x4C) int 21h %endm section .text group DGROUP bss data ..start: ; punctul de intrare în execuţie (IP = start) mov AX, data ; Fixează DS = DGROUP pentru a putea adresa mov DS, AX ; datele prin intermediul lui DS. mov DX, file ; DOS FN 3Ch creează fişierul mov CX, 0 mov AH, 3Ch int 21h jnc begin ; Daca fişierul nu poate fi creat - EXIT ; - abandonează în acest punct. begin: mov [file_id], AX ; Salvează descriptorul fişierului creat. ; Mai întâi generăm la adresa MODELE, modelele binare grafice ale codurilor 0..255 ; SHL scoate in Carry bitul de rang curent din codul respectiv; pentru Carry = 0 ; înscriem 0xB0, iar pentru Carry = 1 înscriem 0xB1 (pe locul curent în MODELE) xor AL, AL ; AL va enumera crescător codurile 0..FFh mov DI, MODELE mov DL, [bitgr] ; iniţial, înscrie 0xB0; S0: mov CX, 8 ; In ciclul S1 se obţin succesiv cei 8 biţi constitutivi ai mov BL, AL ; codului curent din AL (folosind SHL). S1: shl BL, 1 ; Daca bitul de rang curent este 0, mov [DI], DL ; la adresa DS:DI rămâne B0h, altfel adc [DI], byte 0 ; (adunând Carry = 1) se trece la B1h. inc DI ; Vizează următoarea poziţie din MODELE. loop S1, CX inc AL ; INC şi DEC nu afectează flagurile... and AL, AL ; Seteaza Zero-flag, daca AL a ajuns 0 (FFh + 1 = 100h => AL = 0). jnz S0 ; Reia de la S0, daca AL <= 0xFF. ; Se încarcă setul ROM BIOS indicat prin BL (folosind INT 10h, AH = 11h, AL = BL) şi ; se determină adresa setului şi valoarea ROW (cu INT 10h, AX = 1130h, BH primit). mov BX, 0312h ; BH = 3, pentru a obţine informaţii asupra setului CP437 mov AH, 11h ; Se încarcă setul ROM corespunzător valorii primite în BL. mov AL, BL xor BL, BL int 10h mov AX, 1130h mov BH, 3 ; Se obţine adresa ES:BP a setului respectiv şi int 10h ; CX = numărul de octeţi din descrierea fiecărui caracter. mov [ROW], CX ; În ciclurile P0, P1, P2 se constituie repetat BUF_ROWS şi se scrie in fişier. mov CX, 256 / NR_MAT ; În ciclul exterior P0 se va înregistra în fişier câte unul ; dintre cele 256/NR_MAT şiruri de matrice alăturate. P0: push CX mov CX, [ROW] push BP ; În ciclul P1 se va înregistra în fişier câte unul (de la ES:BP până P1: ; la ES:BP + 8×NR_MAT) dintre cele 256/NR_MAT şiruri de matrice alăturate. push CX mov CX, NR_MAT ; În ciclul P2 se obţine o linie-text BUF_ROWS, conţinând mov DI, BUF_ROWS ; modelele binare ale octeţilor de rang curent (indicat de push BP ; contorul lui P1) din descrierile a NR_MAT caractere consecutive. P2: xor BX, BX mov BL, [ES:BP] ; octetul grafic curent (din 8 în 8) din ROM shl BX, 3 ; înmulţeşte cu 8, găsind intrarea corespunzătoare în MODELE mov SI, MODELE add SI, BX ; SI referă cei 8 octeţi grafici B0h/B1h pentru octetul din ROM push ES ; Salvează ES (pentru reluare de la ES:BP) şi pune ES = DS, mov AX, DS ; pentru a transfera cu MOVSD cei 8 octeţi grafici mov ES, AX ; din MODELE, în BUF_ROWS. movsd movsd mov [DI], byte 20h ; adaugă (în BUF_ROWS) spaţiu, după cei 8 octeţi grafici inc DI pop ES ; recuperează ES add BP, 8 ; BP referă acum octetul din caracterul grafic următor din ROM, de loop P2, CX ; acelaşi rang cu octetul tocmai prelucrat, din caracterul curent. call write ; scrie BUF_ROWS în fişier, adăugând şi un "newline" call writenl pop BP ; Recuperează referinţa de bază a octeţilor de acelaşi rang inc BP ; şi trece la rangul următor. pop CX loop P1, CX call writenl ; desparte prin "newline" un şir de matrici de cel următor pop BP ; actualizează referinţa la un set de 8×NR_MAT caractere consecutive din ROM add BP, 8*NR_MAT pop CX loop P0, CX mov AH, 3Eh ; DOS FN 3Eh închide fişierul (disponibilizând descriptorul) mov BX, [file_id] int 21h EXIT ; redă controlul sistemului de operare write: mov AH, 40h ; DOS FN 40h scrie în fişierul cu descriptorul BX mov bx, [file_id] ; un număr de CX caractere, de la adresa DS:DX. mov cx, 9*NR_MAT mov dx, BUF_ROWS int 21h ret writenl: mov ah, 40h mov bx, [file_id] mov cx, 2 mov dx, newline int 21h ret
Maniera în care am specificat secţiunile (folosind group DGROUP), punctul de intrare ..start, precum şi maniera de adresare a memoriei (pe 16 biţi) - sunt specifice formatului obj de fişier-obiect (indicată prin opţiunea -f a asamblorului NASM) care este recunoscut şi de editorul de legături tlink (Borland):
Rulând executabilul obţinut şi folosind programul DOS edit (existent pe Windows, dacă sistemul a fost decent instalat) - putem vizualiza exact caracterele din setul respectiv (aici, setul CP437 8×8, din ROM BIOS-ul unei plăci VGA). Primele caractere grafice (de la codul 0) sunt:
Deschizând cu alt editor de text, cele două caractere prevăzute în program pentru a reprezenta biţii 0 şi 1 vor fi "înlocuite" prin caracterele de acelaşi cod din cadrul fontului de lucru curent. Cu Notepad, alegând prin meniul View/Format/Font fontul Terminal, vedem (aici am făcut o selecţie de caractere):
Iar dacă folosim browserul Firefox, alegând şi în acest caz View/Character Encoding Western (IBM-850):
Desigur, puteam obţine nu 8 ci de exemplu 16 "matrici-alăturate", schimbând definiţia pentru NR_MAT; de asemenea, putem obţine fişierul de matrici corespunzător altor seturi de caractere din ROM BIOS, schimbând folosirea INT 0x10 (de exemplu, cu AL = 0x14 şi BH = 6 am fi obţinut caracterele 8×16).
vezi Cărţile mele (de programare)