Model Web pentru încadrarea şi orarul unei şcoli
Gestionarea şi expunerea încadrării şi orarului şcolii oferă un excelent context pentru o campanie de instruire asupra elaborării aplicaţiilor Web. Încadrarea şi orarul nu sunt independente una de alta şi cel mai firesc este de a le trata împreună, eventual în contextul mai larg al unui site de şcoală persistent (alte componente generice putând fi: Situaţii şcolare, Revistă electronică, Cercuri, Forum).
De unde pornim dezvoltarea unei aplicaţii Web? Întâi trebuie asigurată o bună cunoaştere a domeniului pe care vrem să-l modelăm. Apoi, trebuie determinate cerinţele potenţialilor utilizatori. În funcţie de acestea, trebuie concepută (şi experimentată) structurarea şi organizarea datelor specifice domeniului.
Dezvoltarea propriu-zisă - de la crearea bazei de date şi constituirea rând pe rând a modulelor de cod necesare, până la postarea finală - are loc pe o anumită platformă de lucru şi alegem Linux, fără ezitare (oricine poate instala Ubuntu); vom intercala unde se cuvine, cunoştinţele necesare (oricum avem încă, obiceiul de a nu miza din partea cititorului decât pe cunoştinţe elementare şi pe o anumită bunăvoinţă şi dorinţă de a înţelege şi corela lucrurile).
Ce este încadrarea şi ce este orarul
Înainte de orice este necesară înţelegerea şi tatonarea domeniului pe care intenţionăm să-l modelăm: care sunt conceptele şi entităţile de bază, ce practici se utilizează şi ce pretenţii ar fi de satisfăcut.
Încadrarea este concepută de către conducerea şcolii (pe baza unui plan-cadru furnizat de către Minister), la debutul anului şcolar (suferind modificări minore, pe parcursul anului). Datele de încadrare se exprimă sintetic astfel: care profesor, la care obiect şi la care clasă are câte ore:
profesor: Bazon Vlad
obiect:
Matematică:
clasa IX B: 4 ore/săpt. × 35 săpt. = 140 ore anual
clasa XI A: 4 ore/săpt. × 35 săpt. = 140 ore anual
clasa XII A: 4 ore/săpt. × 35 săpt. = 140 ore anual
Informatică:
clasa XII A: 4 ore/săpt. × 35 săpt. = 140 ore anual
Informatică/Grupă-laborator:
clasa XII A: 3 ore/sapt. × 35 săpt. = 105 ore anual
profesor: Chiriţescu
obiect:
Informatică/Grupă-laborator:
clasa XII A: 3 ore/sapt. × 35 săpt. = 105 ore anual
...
...
Se pot întâlni două greşeli: încadrarea a doi profesori pe un acelaşi obiect la o aceeaşi clasă (excepţie: cazul când la obiectul respectiv se prevede explicit împărţirea clasei în grupe, câte un profesor la fiecare grupă) şi respectiv, omiterea încadrării pe un anumit obiect la o clasă pentru care "planul-cadru" prevede obiectul respectiv.
Orarul este elaborat de un anumit profesor, la începutul anului şcolar şi este modificat pe parcurs după caz (de exemplu, după orice modificare a încadrării). Orarul precizează repartizarea orelor din încadrare pe fiecare dintre zilele săptămânii şi pe fiecare interval orar al fiecărei zile. De exemplu, următoarele extrase din sheet-urile Excel în care este furnizat orarul, arată repartizarea pe zile şi ore a încadrării redate mai sus:


Primul sheet corespunde orarului din schimbul "AM 8-14" (pentru clasele care funcţionează în prima parte a zilei), iar al doilea - schimbului "PM 14-20" (clasele care vin după-amiază). Clasele au fost codificate prin câte o literă (astfel încât clasele dintr-un acelaşi schimb să aibă coduri diferite): codul "A" corespunde clasei "XI A" din încadrare, "a" - clasei "XII A", iar "B" din celălalt schimb - clasei "IX B". Obiectele din încadrare nu apar explicit pe orar (fiind redate în cazul de faţă prin "mate/info", respectiv pe celălalt sheet - "mat/info").
Orarul trebuie să respecte două reguli de natură tehnică (nu discutăm aici principiile calitative pe care ar trebui să le respecte): să nu apară doi profesori într-o aceeaşi zi şi oră la o aceeaşi clasă (excepţie: cazul când clasa este împărţită în grupe) şi respectiv, fiecare clasă trebuie să nu aibă "liber" decât eventual prima sau ultima oră din cadrul orar al fiecărei zile (şi nu "la mijloc").
Încadrarea este un document de lucru primordial, servind conducerii şcolii şi secretariatului (calculul normelor didactice, stabilirea plăţii orelor suplimentare, etc.), cât şi elaborării orarului. De obicei (zic după 35 de ani de slujbă), încadrarea este realizată (de către "conducerea şcolii") cu creionul (şi cu… telefonul), pe un maldăr de hârtii, pe parcursul a două-trei săptămâni - apărând inerent şi greşeli de încadrare tipice: doi profesori încadraţi la o aceeaşi clasă pe un acelaşi obiect, sau clasă rămasă fără profesor la un anumit obiect.
Orarul este baza activităţii zilnice desfăşurate cu elevii în şcoală. Orarul serveşte nu numai elevilor şi profesorilor, ca să ştie fiecare unde, când şi ce are de făcut - dar şi secretariatului (care ţine o evidenţă lunară a numărului de ore efectuate de fiecare şi de asemenea - ce să faci?! - scrie orarul în condică) şi deasemenea, conducerii şcolii (în fel de fel de situaţii, începând de la repartizarea claselor în schimburi în corelare cu numărul de săli de clasă şi cu necesităţile specifice fiecărui profil privind utilizarea laboratoarelor disponibile şi până la planificarea anumitor activităţi în dependendenţă de orarul comun profesorilor dintr-o aceeaşi catedră).
Ce utilizări trebuie să avem în vedere
Fişierul Excel evocat mai sus - ca un exemplu tipic de formulare a orarului - oferă informaţii incomplete şi imprecise asupra încadrării şi numai în mod indirect (numărând literele - putem stabili câte ore are un profesor la o clasă sau alta, şi cam atât). În practica obişnuită în şcoli, încadrarea e una şi orarul e alta; însă pentru o aplicaţie Web, firesc este ca încadrarea şi orarul să fie văzute împreună - pentru că şi una şi alta au la bază aceleaşi entităţi: care sunt schimburile de lucru, clasele din fiecare schimb, obiectele şi profesorii.
Datele concrete de încadrare (şi evident, orarul) se vor schimba radical de la un an şcolar la altul, dar structura lor este aproape invariabilă - ceea ce face ca aplicaţia să poată funcţiona şi în următorul an (fără nici o modificare a ei, trebuind doar să se înscrie noile date), ba chiar şi pentru o altă şcoală.
Imaginile următoare (vezi şi actualizări ulterioare, pe http://scorar/docere.ro sugerează parţial utilizările pe care le-am avut în vedere (derivate în fond din cele expuse mai sus).
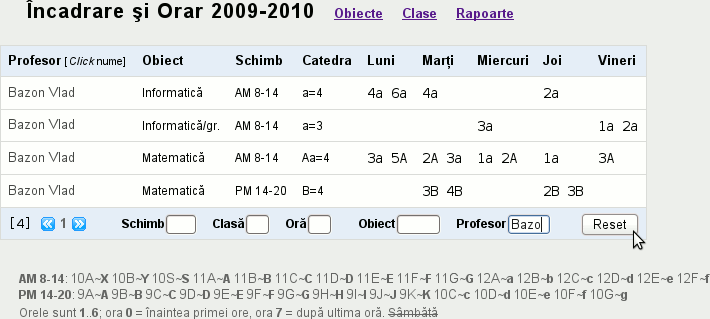
Avem aici datele de încadrare (pe schimburi şi obiecte) şi orarul corespunzător, pentru profesorul selectat. Butonul Reset va anula filtrările efectuate (de Schimb, Clasă, Oră, Obiect sau Profesor) şi va produce datele respective pentru toţi profesorii (paginând rezultatele).
Pentru orice eventualitate, să clarificăm: Aa=4 din coloana Catedra înseamnă că are câte 4 ore/săpt. de Matematică la clasele 'A' şi respectiv 'a' (adică "XIA" şi "XIIA" cum se vede pe nota de la subsol); 1a 2a din coloana Vineri (în linia a doua) spune că XIIA are "informatică/grupe" (laborator) Vineri, primele două ore.
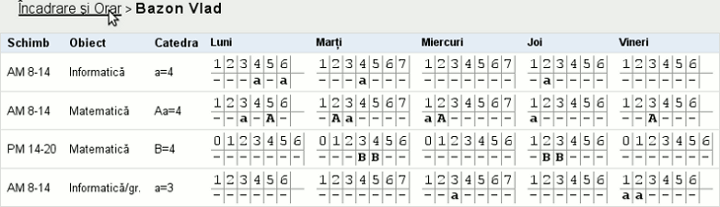
Dând curs indicaţiei "Click nume" din antetul coloanei Profesor, obţinem aceleaşi date - dar într-un format explicit, desigur mai convenabil pentru profesor:
Următoarea imagine redă încadrarea existentă la un anumit obiect (şi orarul corespunzător):
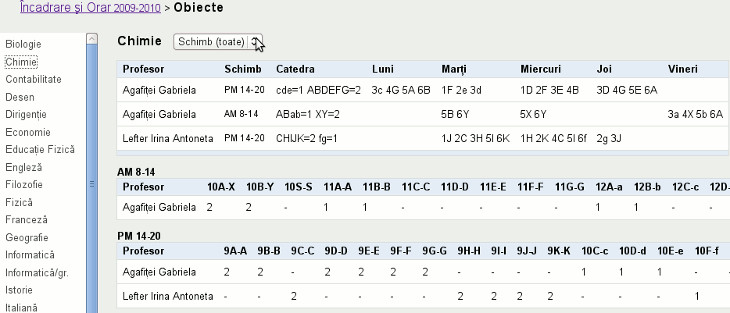
Vedem aici ca încadrarea este corectă: nu există doi profesori pe acelaşi obiect la o aceeaşi clasă; faptul că există clase "fără profesor" (de exemplu coloana XIC-C din al doilea tabel), se explică prin legea curentă: pentru profilul de care ţin clasele respective "curricula" nu prevede obiectul "Chimie".
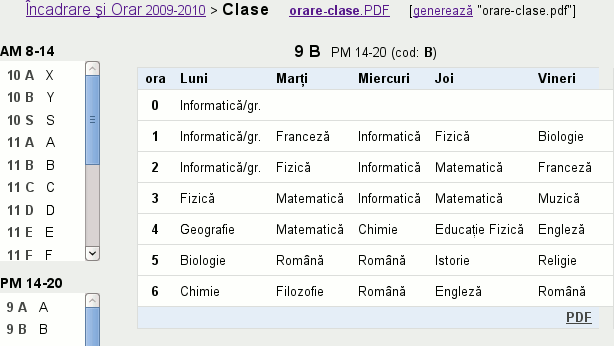
Mai jos avem imaginea orarului unei clase, după selectarea acesteia în coloana de link-uri din stânga; este sugerată şi posibilitatea furnizării orarului (pentru clasa respectivă, dar şi pentru ansamblul tuturor claselor) sub forma unui fişier PDF:
Facilităţile tocmai prezentate pot satisface necesităţile de informare şi de exploatare promptă (prin internet) asupra încadrării şi orarului, venite din partea elevilor, profesorilor, conducerii şcolii şi secretariatului; eventual, poate că ar putea trezi şi un interes mai larg (peste cadrul utilitar), legat de "cum se face" aplicaţia.
Dar mai există un aspect important al utilizării aplicaţiei anunţate: ce facilităţi oferim celui care a elaborat orarul şi are sarcina de a-l prezenta şi de a-l întreţine pe parcursul anului? Este necesară în primul rând, o modalitate cât se poate de comodă pentru înscrierea datelor specifice încadrării si orarului, şi pentru modificarea, extinderea, recuperarea sau actualizarea acestora. O parte a datelor (odată înscrise) va putea fi utilizată şi în anii următori.
Nu ilustrăm acum aspectul tocmai evidenţiat, fiindcă el este strâns legat de structurarea şi organizarea datelor (la care ne referim ceva mai jos). Dar putem sesiza chiar şi acum, că deja este vorba de două aplicaţii distincte: una de tip front-end, destinată publicului obişnuit (cu facilităţile ilustrate mai sus, oferite eventual în baza unei anumite autentificări prealabile) şi o a doua aplicaţie (eventual complet separată de prima) de tip back-end, destinată numai administratorului şi celui care se ocupă de înregistrarea şi întreţinerea datelor.
Organizarea datelor specifice şcolii
Se cuvine să privim lucrurile în ansamblu (chiar dacă ne ocupăm doar de o componentă a domeniului şcolar): nu avem numai schimburi, profesori, obiecte şi clase - entităţile angajate în realizarea încadrării şi orarului; avem deasemenea elevi în fiecare clasă, fiecare cu o anumită situaţie şcolară, în fiecare an şcolar.
Principii elementare, comune aplicaţiilor
Principiul de bază al oricărei aplicaţii este acela de a nu folosi date concrete în interiorul codului specific ei. De exemplu, dacă am implica direct numele profesorilor (sau obiectelor de învăţământ, etc.) în cadrul codului aplicaţiei noastre, atunci codul respectiv va trebui modificat pentru a funcţiona şi în anul şcolar următor, sau pentru a funcţiona cu datele specifice unei alte şcoli.
De fapt, acest principiu este aşa de binecunoscut încât chiar n-a fost nevoie vreodată, să mai fie explicitat. Nu învăţăm să rezolvăm ecuaţia x2 - 5*x + 6 = 0, ci învăţăm să rezolvăm ecuaţiile de gradul doi; nu poate fi vorba de un program care să furnizeze cel mai mare divizor comun al numerelor concrete 18 şi 24, ci poate de un program care să furnizeze cel mai mare divizor comun a două numere (cerute din program şi transmise programului, de exemplu "de la tastatură").
Tot aşa cum un program dintre cele obişnuite în manuale, cere date "de la tastatură" şi le prelucrează apoi prin codul propriu - o aplicaţie Web poate obţine date de la utilizator prin intermediul unor formulare de date prezentate spre completare acestuia, sau poate cere datele necesare unui "server de date" (presupunând că datele au fost înregistrate în prealabil, în modul specific acelui server de date).
Principiul de bază pentru organizarea datelor este asigurarea neredundanţei; nu înregistra o aceeaşi dată concretă, în locuri diferite. Dacă ai înregistrat "mate/info" într-un tabel, atunci într-un al doilea tabel nu mai înregistra a doua oară denumirea respectivă (rişti să tastezi "mat/info" în loc), ci mai degrabă înregistrează o referinţă la denumirea înregistrată în primul tabel.
Să facem însă distincţie între înregistrarea datelor şi prezentarea lor; într-unul dintre tabelele prezentate mai sus, apare de 4 ori valoarea concretă "Bazon Vlad", într-o aceeaşi coloană - dar acest fapt ţine de prezentare (poate că defectuoasă!) şi nu de înregistrarea propriu-zisă.
Un aspect foarte important pentru dezvoltarea unei aplicaţii (chit că este adesea neglijat) este alegerea denumirilor pentru tabelele de date, pentru coloanele de date, pentru funcţiile create, etc.; în principiu, denumirile trebuie alese în aşa fel încât să şi evoce scopul în care se instituie tabelele sau variabilele respective, sau funcţionalitatea pe care o asigură (astfel, aplicaţia va fi mai uşor de întreţinut şi de dezvoltat ulterior).
Mai jos vor rezulta alte câteva principii de lucru elementare, privind folosirea tabelelor de date în aplicaţii.
Schema bazei de date, pentru datele şcolii
Următoarea diagramă sintetizează entităţile (sau "tabelele") şi relaţiile de referenţiere concepute pentru datele specifice domeniului nostru.
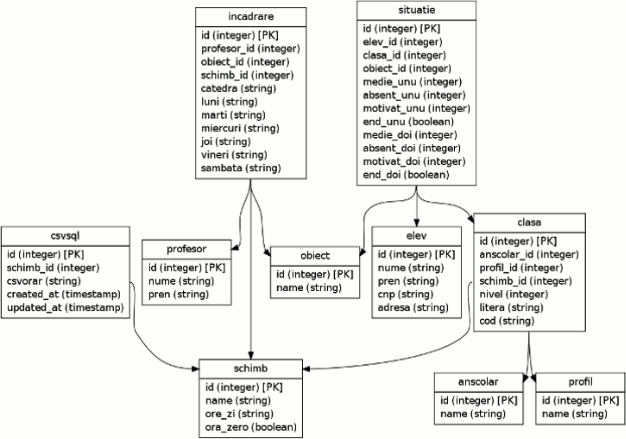
În general, am denumit tabelele şi coloanele de date prin cuvinte obişnuite domeniului (dar evitând diacriticele): "profesor", "obiect", "incadrare", "situatie", etc. Unele excepţii se explică prin faptul că diverse framework-uri oferă anumite facilităţi care simplifică lucrul pe coloane de date cu denumiri standard, precum name (folosit în obiect, profil şi alte două tabele), created_at, updated_at (folosite în tabelul denumit criptic csvsql), sau subject, title, etc. În schimb, în tabelul profesor (şi la fel în elev) n-am mai folosit "name" - ci nume şi pren, pentru motivul evident că "numele" unui profesor (sau elev) este de fapt compus din "nume" şi "prenume".
Tot pentru a beneficia de anumite facilităţi de lucru, am adoptat două convenţii: am desemnat prin id, în fiecare tabel, coloana de date destinată să identifice liniile de date în cadrul acelui tabel ("id" joacă rolul celebrului "Nr.Crt." de pe tabelele oferite de instituţiile publice); iar pentru coloanele menite să conţină "referinţe" la linii de date aflate într-un alt tabel, am folosit ca denumire numele tabelului referit, sufixat cu _id.
Ceee ce chiar nu este explicitat pe diagrama de mai sus este faptul că tabelele respective constituie împreună o bază de date, având desigur o anumită denumire ("colangrug" în cazul de faţă), spre a o putea identifica între bazele de date existente pe hard-disc.
Aspecte elementare privind structura unor tabele de date
Imaginea următoare prezintă nişte înregistrări selectate din tabelele menţionate:

Liniile de date (numite înregistrări) din tabelul clasa corespund biunivoc claselor din şcoală. Fiecare coloană de date (sau, câmp, atribut) din acest tabel conţine valorile specifice fiecărei clase pentru o anumită categorie de date; de exemplu, câmpul nivel înregistrează "nivelul" fiecărei clase (clasele I-a au nivelul 1, clasele a IX-a au nivelul 9; a X-a A, B, şi C au toate nivelul 10, etc.).
În general, pentru modelarea unei anumite entităţi ("clasă" a şcolii, în cazul de faţă) este esenţial să fie alese acele atribute care pe de o parte, caracterizează şi individualizează suficient componentele ei şi în plus, sunt suficient de stabile temporal (îşi modifică foarte rar valorile), iar pe de altă parte - corespund intenţiilor aplicaţiei care angajează entitatea respectivă.
Astfel, o clasă trebuie caracterizată în contextul nostru, nu numai prin nivel şi literă (clasa a IX-a B), dar şi prin cod (care va servi pentru formularea orarului) şi deasemenea, prin indicarea anului şcolar, a profilului de care aparţine şi a schimbului în care funcţionează acea clasă - toate acestea fiind atribute suficient de stabile în timp.
Nu are sens să considerăm un atribut ca "numărul de elevi" din clasă - acest număr variază frecvent. Nu are sens să adăugăm un atribut ca "numele dirigintelui" clasei: "dirigenţia" poate fi înregistrată în tabelul obiect, ca oricare alt obiect de învăţământ, iar tabelul incadrare permite şi relaţionarea între obiect (în speţă, "dirigenţie"), profesor şi clasă.
În schimb, are sens artificiul de a separa numelui clasei ("9A") în două câmpuri de tabel, nivel = 9 şi litera = 'A' - se facilitează astfel operaţiile care angajează clasele de pe un acelaşi nivel; apoi, nivelul "urcă" după fiecare an şcolar, dar "litera" este de obicei, constantă. Dar de obicei, artificiile mai mult încurcă lucrurile şi trebuie evitate!
Să ne uităm acum pe ultima linie de date din tabelul clasa - cea identificată prin valoarea 25 în coloana id (sau mai simplu zis: înregistrarea cu id=25). Această înregistrare se referă la clasa "9I" (ţinând cont că are înscrise datele nivel=9 şi litera=I); schimb_id=2 indică faptul că ea funcţionează în schimbul care are id=2 în tabelul schimb - deci în schimbul care are name="PM 14-20"; la fel deducem profilul clasei: avem profil_id=3, iar la id=3 în tabelul profil, găsim "Servicii".
În clasa (şi analog, în celelalte tabele de date) coloana id serveşte (ca şi "Nr.Crt.") pentru a putea identifica unic o înregistrare de date din cadrul tabelului (o linie din tabel), fiind specificată de regulă prin sintagma Primary Key (sau simplu, "PK"); coloana profil_id (şi analog, celelalte coloane sufixate cu "_id", din tabelele noastre) serveşte pentru a putea identifica o înregistrare (linie) de date dintr-un alt tabel (pentru o asemenea coloană se foloseşte sintagma Foreign Key - pentru că într-adevăr, ea conţine valori străine tabelului din care face parte şi anume, conţine valori ale unei "chei primare" dintr-un alt tabel).
Fiecare înregistrare din clasa conţine o anumită valoare în coloana profil_id; această valoare identifică unic o intrare (PK) în tabelul profil. Zicând simplu "clasă", în loc de "înregistrare din tabelul clasa" şi analog, "profil" în loc de "înregistrare din tabelul profil" - putem formula relaţia între clasa.profil_id pe de o parte şi profil.id pe de alta, astfel: "fiecare clasă are un profil" şi "un profil poate avea mai multe clase" (se zice mai scurt: "profil HAS_MANY clasa"); tocmai acest lucru vrea să-l arate săgeata clasa--->profil de pe diagrama redată la început (şi analog, pentru celelalte săgeţi existente pe diagrama respectivă).
Sintagma "server de date"
Un "server de date" este în fond, un program care aşteaptă ("ascultă" pe o anumită conexiune deschisă), acceptă şi interpretează cereri de date (sau mai general, cereri referitoare la tabele de date) din partea unei aplicaţii ("client"), identifică datele solicitate şi le returnează aplicaţiei care îi avansase cererea respectivă (sau după caz, înscrie în tabele valorile indicate de aplicaţie).
Există în uzul curent mai multe "servere de date" - noi ne bazăm pe MySQL; cam toate recunosc între altele - cu mici variaţii dialectale - limbajul SQL, un limbaj în care o cerere de date se formulează după şabloane precum: "SELECTEAZĂ datele_din_coloanele DIN tabelele CARE-SATISFAC condiţii_şi_relaţionări".
De exemplu, exact datele din tabelul clasa redat mai sus, dar de această dată şi într-o prezentare explicită (interesând nu valorile "foreign key", ci chiar datele referite: nu vrem "3", în loc de "Servicii") pot fi cerute prin:
mysql> SELECT clasa.id, CONCAT_WS('-', clasa.nivel, clasa.litera) AS Clasa,
profil.name AS Profil, schimb.name AS Schimb
FROM clasa, profil, schimb
WHERE clasa.id IN (1, 2, 6, 9, 17, 25) AND
profil.id = clasa.profil_id AND schimb.id = clasa.schimb_id
ORDER BY profil.name;
+----+-------+---------------+----------+
| id | Clasa | Profil | Schimb |
+----+-------+---------------+----------+
| 6 | 11-C | Contabilitate | AM 8-14 |
| 2 | 10-A | Informatică | AM 8-14 |
| 17 | 9-A | Informatică | PM 14-20 |
| 1 | 10-S | Servicii | AM 8-14 |
| 25 | 9-I | Servicii | PM 14-20 |
| 9 | 11-F | Turism | AM 8-14 |
+----+-------+---------------+----------+
Au fost selectate (de către mysql) acele înregistrări din tabelul clasa care au valorile clasa.id 1, 2, 6, 9, 17 sau 25 şi pentru aceste înregistrări s-au determinat din tabelele asociate, valorile corespunzătoare pentru profilul clasei şi pentru schimb; în final, înregistrările au fost ordonate după numele profilului.
Tabele de date versus obiecte ale aplicaţiei
"Serverele de date" operează cu tabele de date, care în fond sunt fişiere aflate pe hard-disc. În schimb, aplicaţiile Web operează cu obiecte ("variabile de memorie", care nu sunt stocate pe hard-disc). Într-un caz, se operează cu valori "scalare" - numere, şiruri de caractere - tratate în fond individual (doar că organizate în "înregistrări" şi tabele) şi persistente (fiind memorate pe disc), pe când în celălalt (într-un limbaj de nivel înalt) se lucrează cu obiecte constituite din diverse alte obiecte (şi funcţii) şi cu referinţe la obiecte, volatile.
Pentru "serverul de date" o clasă este în fond un set de valori: (100, 1, 3, 1, 12, 'A', 'a'), după cum se vede chiar din formularea comenzii de inserare:
mysql> use colangrug;
Database changed
mysql> insert into clasa values(100,1,3,1,12,'A','a');
Query OK, 1 row affected (0.00 sec)
S-a inserat o nouă înregistrare în tabelul clasa, având în prima coloană (id) valoarea 100, în coloana următoare valoarea 1, pe profil_id valoarea 3, schimb_id=1, nivel=12, litera='A' şi cod='a'.
La nivelul aplicaţiei Web, o clasă va fi un obiect $clasa, constituit din variabile private precum $nume, din obiecte sau referinţe la obiecte precum $schimb şi $profil, metode publice de acces (funcţii get_schimb(), set_profil(), etc.) şi diverse alte metode de lucru (de exemplu o metodă care să furnizeze setul de valori care va fi necesar comenzii INSERT). De regulă, funcţiile de operare ale aplicaţiei vor primi şi vor returna referinţe la obiecte $clasa şi nu vreun set de valori inividuale (ca în cazul INSERT).
Modelând datele concrete şi corelaţiile necesare prin obiecte "abstracte" existente numai pe parcursul execuţiei, aplicaţia este de fapt, persistentă: chiar când datele încadrării şi orarului se schimbă radical pe disc, aplicaţia va putea funcţiona fără a fi modificată.
Trebuie înţeles că aplicaţia nu doar "transformă în obiecte" înregistrările şi tabelele de date - ea constituie deasemenea formularele şi layout-urile necesare pentru preluarea datelor care trebuie înscrise în tabelele de date şi pentru prezentarea tabelelor; diverse framework-uri creează automat codul de bază pentru modelarea obiectuală a tabelelor de date existente, împreună cu form-urile şi layout-urile corespunzătoare.
De obicei, aplicaţiile Web sunt "scrise" folosind limbaje de nivel înalt care suportă "programarea orientată pe obiecte" (OOP); noi vom folosi aici PHP5 (şi javaScript), împreună cu nişte "biblioteci de obiecte PHP5" (framework-uri PHP): symfony şi Doctrine.
Tradiţional, un program cuprinde o funcţie "principală", nişte "variabile globale" şi diverse alte funcţii "ajutătoare" - fiind până la urmă o listă de instrucţiuni date calculatorului spre execuţie, începând cu prima şi terminând cu instrucţiunea de încheiere a programului; de regulă, programul (şi nu vreun eveniment extern programului) "spune" calculatorului când să încheie execuţia şi să redea controlul către sistemul de operare subiacent.
OOP a schimbat radical optica tradiţională asupra "programului": un program este o colecţie de obiecte care au un comportament specific şi care pot să interacţioneze între ele după caz; calculatorul va executa nu "programul", ci de fapt, metodele de comportament specificate în program pentru obiectele respective, reacţionând nu după regula "de la prima instrucţiune a programului până la ultima", ci în funcţie de anumite "evenimente" specificate de obicei în cadrul metodelor proprii obiectelor.
Unde este baza de date?
O bază de date este constituită din mai multe fişiere, aflate desigur pe hard-disc într-un anumit director. Întrebarea ar fi… care hard-disc?
Întrebările stupide au sensul de a corecta unele idei greşite, formate "conform programei şcolare". În general, baza de date nu este pe Desktop şi nici pe calculatorul propriu, ca să o deschizi din Visual FoxPro.
Să ne imaginăm că la un moment dat, mai multe persoane aflate în diverse locuri, se interesează asupra trenurilor care trec prin Vaslui. Să facă o plimbare la gara din Vaslui, unde este afişat răspunsul?! Să sune la Agenţia CFR (suportând un răspuns în doi peri)? Să caute în cartea de "Mersul Trenurilor", publicată acum câteva luni şi probabil neactuală?. Dar să ne imaginăm că fiecare are acces la un calculator conectat la Internet; în această circumstanţă, persoanele respective - oricât de multe şi oriunde s-ar afla - pot apela la un serviciu Internet care furnizează informaţii actuale privind mersul trenurilor pe teritoriul României:
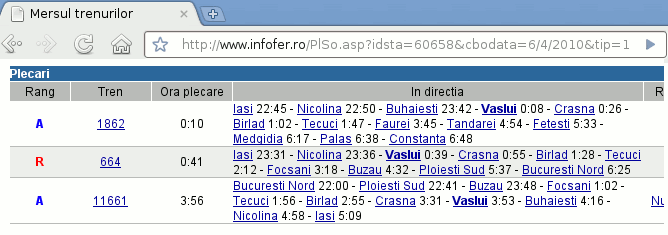
Cum funcţionează oare, aplicaţia Web astfel invocată? Cu siguranţă că există o bază de date privitoare la numeroasele gări (localităţi), trenuri, intervale orare, etc.
Aplicaţia a preluat de la utilizatori cererea ("care trenuri mai trec prin VASLUI"), a reformulat-o în maniera specifică "serverului de date" la care este conectată şi i-a transmis-o acestuia spre execuţie; apoi, primind răspunsul - l-a reformulat spre a-l prezenta utilizatorului, ca în imaginea de mai sus (repetând probabil toate acestea, pentru fiecare dintre ceilalţi utilizatori - deşi, fiind vorba de o aceeaşi cerere şi la intervale scurte de timp, aplicaţia putea probabil şi să răspundă imediat prin preluarea răspunsului din "memoria cache").
Este evident că baza de date folosită de aplicaţia "Mersul Trenurilor" nu se află pe niciunul dintre calculatoarele de pe care utilizatorii au accesat aplicaţia. De obicei, baza de date se află chiar pe acelaşi hard-disc (sau măcar pe acelaşi calculator, sau pe o reţea particulară) pe care se află şi fişierele-sursă ale aplicaţiei care o foloseşte; iar aplicaţia se află într-un singur loc, de unde poate fi accesată prin Internet de către diverşii clienţi.
În plus, să mai subliniem odată - baza de date respectivă nu poate fi accesată direct de vreun client, ci numai prin intermediul aplicaţiei (care propune utilizatorului diverse formulare de interogare) şi aceasta chiar dacă acel client are instalat pe calculatorul său, MySQL sau chiar şi Visual FoxPro…
Povestea imaginată mai sus se aplică aproape fără excepţie, aplicaţiilor Web care folosesc baze de date. Pentru un alt exemplu, foarte la îndemână: fiecare foloseşte un "server de mail", yahoo.com, gmail.com etc.; are cineva pe hard-discul propriu, baza de date unde îi sunt păstrate mesajele (arătate în "Inbox")?!
În cazul nostru, fiind vorba de MySQL - putem răspunde ceva mai precis: pe fişierul specific de configurare my.cnf (din /etc/mysql, pe Linux) vedem datadir = /var/lib/mysql (valoarea "default"), ceea ce ne indică directorul în care MySQL păstrează fişierele bazelor de date.
Ca să consultăm acest director, putem folosi comanda ls ("list directory contents"); dar ea trebuie prefixată cu sudo (a folosi comanda man sudo, pentru manualul comenzii) fiindcă avem de accesat o zonă exterioară directorului propriu /home/vb (sub Linux, fiecărui utilizator îi este rezervat un subdirector în /home şi numai în această zonă, utilizatorul respectiv are drepturi "depline" - de scriere, de citire şi de execuţie; sudo permite extinderea drepturilor unui utilizator şi pentru zone din afara propriului "home").
vb@localhost:~$ sudo ls -l /var/lib/mysql
total 28776
drwx------ 2 mysql mysql 4096 Apr 4 2008 chess
drwx------ 2 mysql mysql 4096 Jun 1 13:13 colangrug
-rw-rw---- 1 mysql mysql 18874368 Jun 5 02:54 ibdata1
...
În ultima coloană avem denumirile bazelor de date existente, inclusiv colangrug - baza de date a cărei schemă am redat-o mai sus. La instalare, MySQL a înfiinţat automat un "user" (şi un "group") denumit "mysql" - acest "user" şi respectiv "group" apar pe a doua şi a treia coloană (ca "proprietari" ai fişierelor respective; un "group" poate conţine mai mulţi useri). Vedem că numai "proprietarul" (nu şi alţi useri) are drepturi de citire, scriere şi răsfoire (specificate prin "rwx") a acestor fişiere (sau directoare).
Să listăm la fel şi conţinutul directorului constituit de MySQL pentru baza noastră de date:
vb@localhost:~$ sudo ls -la /var/lib/mysql/colangrug/
total 252
-rw-rw---- 1 mysql mysql 8586 Jun 1 13:13 anscolar.frm
-rw-rw---- 1 mysql mysql 8774 Jun 1 13:13 clasa.frm
-rw-rw---- 1 mysql mysql 8716 Jun 1 13:13 csvsql.frm
-rw-rw---- 1 mysql mysql 62 May 15 11:57 db.opt
-rw-rw---- 1 mysql mysql 8678 Jun 1 13:13 elev.frm
-rw-rw---- 1 mysql mysql 8914 Jun 1 13:13 incadrare.frm
-rw-rw---- 1 mysql mysql 8586 Jun 1 13:13 obiect.frm
-rw-rw---- 1 mysql mysql 8616 Jun 1 13:13 profesor.frm
-rw-rw---- 1 mysql mysql 8586 Jun 1 13:13 profil.frm
-rw-rw---- 1 mysql mysql 8658 Jun 1 13:13 schimb.frm
-rw-rw---- 1 mysql mysql 8994 Jun 1 13:13 situatie.frm
...
Vedem că tabelul clasa este reprezentat prin fişierul clasa.frm şi analog celelalte tabele din baza de date discutată mai sus. MySQL memorează definiţia tabelului într-un fişier denumit la fel ca tabelul şi cu extensia frm ("the table format file"). Modul de memorare a datelor propriu zise şi a eventualelor indexări prevăzute la definirea tabelului (pentru a asigura accesul rapid într-o anumită ordine, a înregistrărilor) depinde de tipul de ENGINE specificat la crearea tabelului:
CREATE TABLE clasa ( id INT AUTO_INCREMENT, anscolar_id INT NOT NULL, profil_id INT NOT NULL, schimb_id INT NOT NULL, nivel TINYINT NOT NULL, litera VARCHAR(1) NOT NULL, cod VARCHAR(3), INDEX anscolar_id_idx (anscolar_id), INDEX profil_id_idx (profil_id), INDEX schimb_id_idx (schimb_id), PRIMARY KEY(id)) ENGINE = INNODB;
Avem aici ENGINE = InnoDB, caz în care datele şi indecşii creaţi sunt memorate într-un acelaşi fişier şi depinde de existenţa opţiunii innodb_file_per_table în fişierul de configurare my.cnf, pentru ca să avem câte un fişier de date şi indecşi pentru fiecare tabel în parte (având extensia ibd), respectiv să avem un singur astfel de fişier (redat mai sus, /var/lib/mysql/ibdata1) pentru toate tabelele de tip Innodb.
Desigur, putem şi verifica această "teorie" , listând conţinutul unui asemenea fişier pentru a constata prezenţa datelor respective în cadrul lui; sub Linux, se poate invoca hexdump -C path/to/filename (prefixând după caz, cu "sudo"), în scopul listării în hexazecimal şi în ASCII a conţinutului unui fişier de pe disc.
Scripturi PHP (sub Linux)
Un script este un fişier-text care începe (obligatoriu pe prima linie, chiar la începutul ei) cu caracterele #! (combinaţie denumită shebang); acest semn este recunoscut de către sistemul de operare (Linux) ca directivă de precizare a programului care poate interpreta şi executa scriptul respectiv. Un script pentru Perl trebuie să înceapă cu "#! path/to/perl", unul pentru PHP cu "#! path/to/php", etc.
Să remarcăm că HTML prevede un tag cu rol analog semnului "#!": <script src="path/to/un_program.js"> indică browserului să încarce fişierul "un_program.js" şi să-l paseze pentru interpretare şi execuţie interpretorului javaScript (încorporat în browser, încât nu este necesară precizarea "#!path/to").
Este important în diverse momente, să ştim să determinăm calea absolută a unui program; putem folosi comanda which:
vb@localhost:~/websco/doc$ which php
/usr/bin/php
Desigur, scriptul trebuie să conţină instrucţiuni pe care interpretorul căruia îi este adresat să le poată executa. Pe de altă parte, sistemul de operare va încărca fişierul respectiv numai dacă îl recunoaşte ca fiind unul executabil; altfel, invocând pe linia de comandă a terminalului un fişier text obişnuit (chiar şi dacă ar avea extensia ".php") obţinem desigur mesajul "command not found".
Cum recunoaşte sistemul de operare că are de-a face cu un fişier executabil (caz în care trebuie să-l încarce în memorie şi să vadă cine trebuie pus să-l execute)? Linux asociază fiecărui fişier un set de biţi de mod şi un set de biţi de permisiuni şi oferă comenzi pentru setarea corespunzătoare a acestora; permisiunile vizează pe userul care a creat fişierul respectiv ("proprietarul" fişierului, care poate fi şi o aplicaţie, nu neapărat un utilizator obişnuit), vizează un "group" de useri asociaţi proprietarului şi apoi, pe ceilalţi useri posibili. Biţii de mod indică operaţiile posibile cu fişierul respectiv: read, write sau execute şi ei pot fi stabiliţi fie numai pentru proprietar, fie şi pentru "group", fie pentru toţi userii.
Putem constata cine si ce permisiuni are asupra unui fişier folosind ls -l. Comanda chmod serveşte pentru a seta biţii de mod asupra unui fişier. Pentru exemplu, după ce am creat un fişier (fie şi vid) "test.php":
vb@localhost:~/websco/doc$ ls -l test.php
-rw-r--r-- 1 vb vb 0 Jun 6 00:42 test.php
vedem că: este vorba de un fişier obişnuit (nu director, căci atunci primul caracter era 'd', nu '-'), creat de userul 'vb' (din grupul 'vb'). Proprietarul (userul 'vb') are drepturile 'rw-' adică poate citi fişierul ('r') şi îl poate edita ('w'), dar nu şi executa; userii asociaţi (grupul 'vb') pot doar să citească fişierul ('r--'); "others" au deasemenea, numai drept de citire. Nu există drept de execuţie - putem încerca să-l punem în "execuţie":
vb@localhost:~/websco/doc$ ./test.php
-bash: ./test1.php: Permission denied
Permisiunea de execuţie "denied". Să-l "transformăm" acum în fişier executabil şi să verificăm:
vb@localhost:~/websco/doc$ chmod 0755 test.php
vb@localhost:~/websco/doc$ ls -l test.php
-rwxr-xr-x 1 vb vb 0 Jun 6 00:42 test.php
Cifra 7 (din "0755") este în binar: "111", marcând toţi biţii "rwx"; 5 = "101" marchează "r-x". Fişierul este recunoscut de-acum ca executabil ('x'). Să încărcăm "test.php" (vid în acest moment) într-un editor de cod-sursă şi să înscriem o instrucţiune PHP simplă:
#!/usr/bin/php echo "Hello World!\n";
apoi să executăm scriptul respectiv:
vb@localhost:~/websco/doc$ ./test.php echo "Hello World!\n";
Explicaţia insuccesului (s-a afişat doar textul-sursă, fără prima linie) este următoarea: spre deosebire de alte limbaje de nivel înalt, PHP a fost creat cu scopul de a putea mixa HTML-ul obişnuit cu instrucţiuni executabile puternice; aceasta a necesitat considerarea unui tag similar elementului <script> din HTML, dar deosebit de cele existente şi s-a ales drept "tag PHP", combinaţia de caractere <?php. O secvenţă de instrucţiuni PHP trebuie să înceapă cu acest tag, pentru a fi recunoscută ca atare de PHP:
#!/usr/bin/php <?php echo "Hello World!\n";
vedem că acum execuţia reuşeşte (nu se mai afişează textul-sursă, ci se execută instrucţiunea):
vb@localhost:~/websco/doc$ ./test.php Hello World!
PHP răspunde necesităţilor de a folosi scripturi direct din linia de comandă (în maniera arătată mai sus) printr-o componentă specializată a sa, CLI ("Command Line Interface"). E altceva însă, când instrucţiuni PHP sunt incluse într-un fişier HTML (adresat deci unui browser, nu liniei de comandă); un asemenea fişier (conţinând instrucţiuni PHP, ambalate desigur între tagurile "<?php" şi "<?") nu va fi returnat ca atare şi nici imediat, browserului care l-a invocat - ci mai întâi va fi transferat lui PHP spre a interpreta şi executa instrucţiunile respective; iar PHP va înlocui secvenţa de instrucţiuni respectivă cu rezultatul execuţiei şi abia rezultatul final (după ce PHP execută toate instrucţiunile care îi erau adresate şi după ce face toate înlocuirile) va fi transmis browserului.
Folosirea bazelor de date MySQL în cadrul scripturilor PHP
Maniera standard de lucru cu baze de date în cadrul unui script PHP constă în următoarele: se foloseşte o funcţie PHP care realizează conectarea la "serverul de date" (MySQL în cazul nostru) şi una care permite selectarea unei baze de date; se formulează o interogare de date (sub forma unei comenzi SQL, dar fără terminatorul ; şi încadrând între ghilimele sau apostrofuri - adică drept o variabilă de tip "şir de caractere"); se invocă apoi o funcţie PHP care trimite interogarea la MySQL, spre interpretare şi execuţie - obţinând o referinţă la zona de date corespunzătoare rezultatului; folosind această referinţă, datele obţinute vor putea fi mai departe prelucrate în cadrul scriptului, ca variabile PHP.
Această schemă de lucru cu baze de date este generală, fiind folosită şi în scripturi Perl, în aplicaţii cu Java, sau cu alte limbaje de nivel înalt. Ce s-ar cuveni de subliniat este faptul că aceasta este metoda tradiţională - diverse framework-uri (Doctrine, de exemplu) oferă modele OOP pentru baze de date.
Există mai multe extensii PHP (împreună cu drivere pentru diverse "servere de date"), care asigură funcţiile PHP necesare lucrului cu baze de date (şi o asemenea extensie trebuie să fi fost montată, în prealabil).
Pentru exemplu, scriptul următor va produce rezultatul care a fost obţinut anterior (dar atunci - în mod direct), pentru datele din tabelul clasa:
#!/usr/bin/php <?php $link = mysql_connect('localhost', 'vb', '123456') or die( 'Serverul de date NU poate fi contactat'); mysql_select_db('colangrug', $link) or die( 'Baza de date indicată NU poate fi deschisă'); // Formulează o cerere de date ("query") // $sql = 'SELECT nivel as Clasa, litera as Schimb, cod as Profil FROM clasa'; $sql = <<< HERE SELECT CONCAT_WS('-', clasa.nivel, clasa.litera) AS Clasa, profil.name AS Profil, schimb.name AS Schimb FROM clasa, profil, schimb WHERE clasa.id IN (1, 2, 6, 9, 17, 25) AND profil.id = clasa.profil_id AND schimb.id = clasa.schimb_id ORDER BY profil.name HERE; // Cere MySQL să execute interogarea; $result vizează rezultatul returnat de MySQL $result = mysql_query($sql, $link) or die( 'interogarea NU poate fi executată' . mysql_error()); // var_dump($result); // Variabilă de tip "resource": referinţă la o resursă externă $row = mysql_fetch_assoc($result); // Prima linie de date de la $result /** Afişează tabloul $row, sub forma Cheie => Valoare: print_r($row); Array ( [Clasa] => 11-C [Profil] => Contabilitate [Schimb] => AM 8-14 ) */ $format = "%-16s"; // Formatul de afişare: coloane cu 16 caractere, aliniere stânga // Afişează "antetul" tabelului (numele coloanelor) print "\n"; foreach(array_keys($row) as $atribut) { // 'Clasa', 'Profil', 'Schimb' printf($format, $atribut); } print "\n\n"; // Preia liniile de date (prima există deja în $row) şi le afişează do { foreach($row as $valoare) { printf($format, $valoare); } print "\n"; } while ($row = mysql_fetch_assoc($result)); // Închide eventual, conexiunea mysql_close($link);
Invocând acest script de pe linia de comandă obţinem:
vb@localhost:~/websco/doc$ ./get_date.php Clasa Profil Schimb 11-C Contabilitate AM 8-14 10-A Informatic# AM 8-14 9-A Informatic# PM 14-20 10-S Servicii AM 8-14 9-I Servicii PM 14-20 11-F Turism AM 8-14 vb@localhost:~/websco/doc$
Să remarcăm totuşi, două diferenţe faţă de rezultatul obţinut anterior (prin comanda directă la promptul mysql>). Am ignorat acum, coloana id - pentru bunul motiv că valorile cheii primare nu au de ce să-l intereseze pe utilizatorul aplicaţiei (ele servesc doar pentru lucrul intern al "serverului de date").
Apoi, să vedem că acum s-a afişat "Informatic#" în loc de "Informatică" şi în plus - în pofida faptului că am formatat afişarea coloanelor pe câte 16 caractere, sau tocmai de aceea - coloana a treia apare "defazat" în liniile corespunzătoare valorii "Informatic#".
Explicaţia acestei nereguli decurge din faptul că PHP nu are încă, suportul necesar pentru Unicode (spre deosebire de MySQL şi de Linux); ă este reprezentat pe doi octeţi (nu pe unul singur, precum caracterele standard), încât "Informatică" este reprezentat pe 11 octeţi; ori printf('%-16s', $valoare) ignoră/substituie caracterele nestandard, astfel că "Informatică" are pentru printf() numai 10 octeţi ceea ce (după completare cu spaţiu la formatul indicat de 16 octeţi) determină "defazarea" de 1 caracter pe ultima coloană.
Modificarea printf ($format, utf8_decode($valoare)); ar "repara" alinierea, fiindcă utf8_decode() converteşte şirul codificat UTF-8 (în cazul nostru, "Informatică" - cu 10 caractere, dar pe 11 octeţi) într-un şir "single-byte" (cu 11 caractere); dar "ă" tot nu va fi recunoscut şi va fi înlocuit cu "?".
Scriptul redat mai sus obţine anumite date de la MySQL şi le prezintă clientului; asemenea scripturi (în special în PHP şi în Perl) se găsesc în foarte multe locuri (pe internet, în cărţi). Ar fi de văzut acum şi un script care face invers - preia date de la utilizator (prin intermediul unui formular HTML) şi le trimite apoi lui MySQL spre a le înscrie în baza de date - vezi de exemplu, CMS cu PHP şi MySQL (şi vezi PHP-MySQL-CRUD pentru un exemplu de modelare sintetică a operaţiilor "CRUD").
Dar trebuie înţeles că aproape fără excepţie, aceste scripturi au caracter pur didactic. Ele nu sunt de folosit într-o aplicaţie reală, pentru că "în producţie" totdeauna intervin diverse alte aspecte importante, care pur şi simplu "nu încap" în scripturile menţionate; este vorba de exemplu, de aspecte "de securitate" a datelor şi a funcţionării aplicaţiei, pe traseul utilizator - formular HTML - aplicaţie - bază de date.
Aceste "alte aspecte" sunt în fond comune tuturor aplicaţiilor Web şi de aceea ele sunt avute în vedere şi sunt rezolvate într-o manieră unitară, în cadrul multora dintre framework-urile existente; folosind scripturi de genul celor menţionate mai sus, ar trebui de exemplu, să "securizăm" fiecare formular în parte - pe când folosind un framework pentru a dezvolta aplicaţia, am avea deja (aproape) asigurată securizarea corespunzătoare.
vezi Cărţile mele (de programare)