Legăturile ecuaţiei cubice (partea a IV-a)
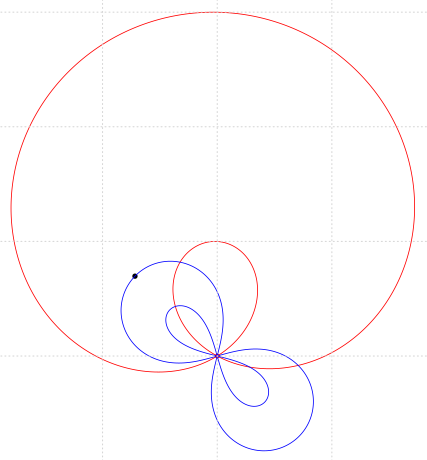
Încercăm să clasificăm - sau eventual, să caracterizăm direct - curba descrisă de punctele critice ale unui polinom redus de gradul trei care are o rădăcină fixată şi una mobilă, ambele de modul 1.
Legăturile ecuaţiei cubice (partea a III-a)
Locul geometric al valorilor parametrului complex p al ecuaţiei z3 + pz + q = 0, z∈C, când o rădăcină este fixată şi o a doua mobilă pe un acelaşi cerc cu centrul în origine, este o curbă trisectoare (cu axa de simetrie dată de dublul direcţiei rădăcinii fixe).
În plus - care ar fi locul punctelor critice? (să fie lemniscate Bernoulli? seamănă ele, dar… e greu de crezut: cine să fie focarele?)
Legăturile ecuaţiei cubice (partea a II-a)
Extinzând la numere complexe formula trigonometrică a rădăcinilor dată de Viète, ajungem să evidenţiem teorema lui Marden: punctele critice ale unui polinom de gradul trei cu rădăcini complexe necoliniare, sunt focarele elipsei lui Steiner înscrise triunghiului format de rădăcini (unica elipsă centrată în baricentru şi tangentă laturilor în mijloacele acestora).
Legăturile ecuaţiei cubice (partea I)
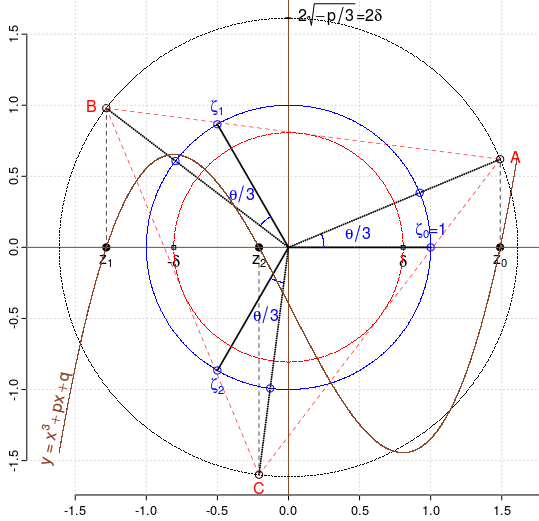
roteşte ζk (rădăcinile de ordinul 3 ale unităţii) cu unghiul θ/3;
proiectează (din origine) imaginile rezultate, pe cercul de rază 2δ (unde ±δ sunt rădăcinile derivatei), obţinând punctele A, B, C;
abscisele punctelor A, B, C sunt rădăcinile reale zk ale ecuaţiei x3+px+q=0, cu p<0, |0.5q / δ3| < 1 şi
θ = arccos( 1.5q / (pδ) ).
Triunghiul ABC este echilateral; cercul înscris lui conţine punctele critice (±δ, 0).
(dar numai întâmplător, ζk par a fi situate pe laturile triunghiului ABC)
Fractalii Newton ai rădăcinilor unităţii - partea a patra
Tranşăm practic (verificând un rezultat teoretic clasic), dilema locului punctelor periodice: generăm fractalul plecând de la unul dintre punctele 2-periodice - colectând preimaginile acestuia până la un anumit ordin de iterare; adăugând pe imaginea obţinută punctele 2-periodice, vedem că acestea ţin de "mulţimea Julia".
vezi Cărţile mele (de programare)